1.创建Python文件对象的读写模式(r,w模式)与创建Java输入输出流;
FileInputStream inputStream=new FileInputStream(new File("E:\workspace\tmpfile\farrago.txt"));
FileOutputStream outputStream=new FileOutputStream(new File("E:\workspace\tmpfile\outagainb.txt"));
2.序列化Python对象,序列化成字符串如toJson和序列化成二进制;
3.向文件对象中写入序列化对象。
PS:有的序列化包,有方便的方法直接将序列化和写入过程合二为一。numpy的save和load感觉就是序列化而已,那么其必要性不大了?
import umsgpack
import pickle
import numpy as np
"""
1.创建Python文件对象的读写模式(r,w模式)与创建Java输入输出流;
FileInputStream inputStream=new FileInputStream(new File("E:\workspace\tmpfile\farrago.txt"));
FileOutputStream outputStream=new FileOutputStream(new File("E:\workspace\tmpfile\outagainb.txt"));
2.序列化Python对象,序列化成字符串如toJson和序列化成二进制;
3.向文件对象中写入序列化对象。
PS:有的序列化包,有方便的方法直接将序列化和写入过程合二为一。numpy的save和load感觉就是序列化而已,那么其必要性不大了?
"""
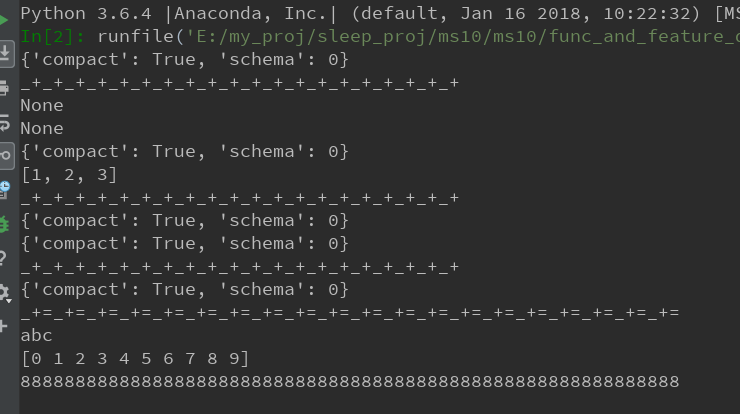
with open('test0.bin', 'wb') as f:
rs = umsgpack.packb({u"compact": True, u"schema": 0})
f.write(rs)
with open('test0.bin', 'rb') as f:
print(umsgpack.unpackb(f.read()))
print("_+"*20)
with open('test.bin', 'wb') as f:
print(umsgpack.pack({u"compact": True, u"schema": 0}, f))
print(umsgpack.pack([1,2,3], f))
with open('test.bin', 'rb') as f:
print(umsgpack.unpack(f))
print(umsgpack.unpack(f))
print("_+"*20)
with open('test2.bin', 'wb') as f:
rs = pickle.dumps({u"compact": True, u"schema": 0})
f.write(rs)
print(pickle.loads(rs))
with open('test2.bin', 'rb') as f:
print(pickle.load(f))
print("_+"*20)
with open('test3.bin', 'wb') as f:
pickle.dump({u"compact": True, u"schema": 0},f)
with open('test3.bin', 'rb') as f:
print(pickle.load(f))
print("_+="*20)
with open('test4.bin', 'wb') as f:
"""有没有觉得numpy的save与load就是个二进制序列化协议"""
np.save(f, 'abc')
np.save(f, np.arange(10))
with open('test4.bin', 'rb') as f:
print(np.load(f))
print(np.load(f))
print("888" * 20)