python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

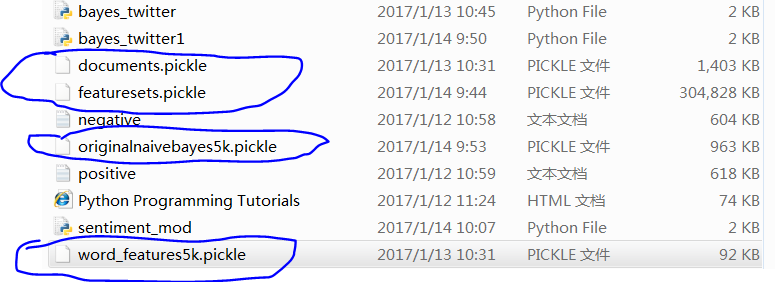
已经生成4个pickle文件,分别为documents,word_features,originalnaivebayes5k,featurests
其中featurests容量最大,3百多兆,如果扩大5000特征集,容量继续扩大,准确性也提供
https://www.pythonprogramming.net/sentiment-analysis-module-nltk-tutorial/
Creating a module for Sentiment Analysis with NLTK
# -*- coding: utf-8 -*-
"""
Created on Sat Jan 14 09:59:09 2017
@author: daxiong
"""
#File: sentiment_mod.py
import nltk
import random
import pickle
from nltk.tokenize import word_tokenize
documents_f = open("documents.pickle", "rb")
documents = pickle.load(documents_f)
documents_f.close()
word_features5k_f = open("word_features5k.pickle", "rb")
word_features = pickle.load(word_features5k_f)
word_features5k_f.close()
def find_features(document):
words = word_tokenize(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
featuresets_f = open("featuresets.pickle", "rb")
featuresets = pickle.load(featuresets_f)
featuresets_f.close()
random.shuffle(featuresets)
print(len(featuresets))
testing_set = featuresets[10000:]
training_set = featuresets[:10000]
open_file = open("originalnaivebayes5k.pickle", "rb")
classifier = pickle.load(open_file)
open_file.close()
def sentiment(text):
feats = find_features(text)
return classifier.classify(feats)
def sentiment_test(text):
feats = find_features(text)
value=classifier.classify(feats)
if value=="pos":
print("正面评价")
else:
print("负面评价")
def sentiment_inputTest():
text=input("主人请输入留言:")
feats = find_features(text)
value=classifier.classify(feats)
if value=="pos":
print("正面评价")
else:
print("负面评价")
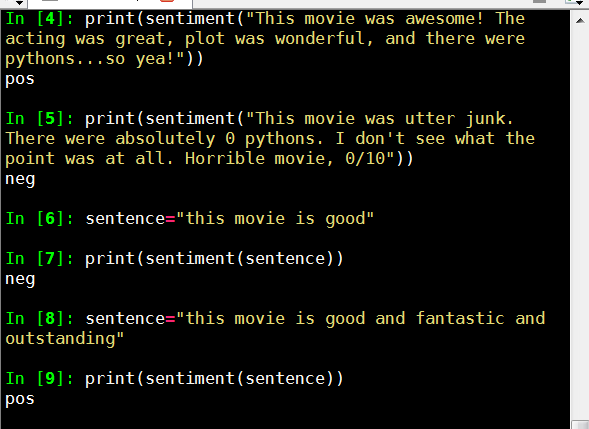
print(sentiment("This movie was awesome! The acting was great, plot was wonderful, and there were pythons...so yea!"))
print(sentiment("This movie was utter junk. There were absolutely 0 pythons. I don't see what the point was at all. Horrible movie, 0/10"))
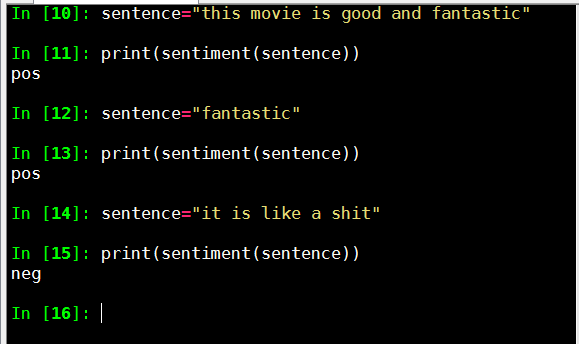
测试效果
还是比较准,the movie is good 测试不准,看来要改进算法,考虑用频率分析和过滤垃圾词来提高准确率