在之前已经对二叉树进行了详细的学习,这次会升级二叉树,就比之前学习的二叉树要更加的复杂麻烦了,涉及到左悬右悬的概念了。
Haffman树:
概念:
Haffman树主要是用在压缩技术上,来看一张图:

压缩之后的大小相比原文件要小了很多,其它的压缩思想下面简单简述一下:
先看一下代码:
这种代码在平常中会经常见到,那如果有一个班上的成绩占比图:

假设有100个人,那么根据上面的占比可以得到:
0~59有5个人、60~69占用15个人、70~79占用40个人、80~89占用30个人、90~100占用10个人。 那面来大致一下其要判断的总条件的个数:
0~59有5个人,只会执行这么一个条件:

所以5个人的数量的话,这个比例执行条件的总数量为5x1;
而60~69占用15个人,当要执行到这个区间断时,会要经过2个条件判断才行,如下:

所以15个人的数量的话,这个比例执行条件的总数量为15x2;
以此类推,整个100人要执行的总条件个数就为:5*1 + 15 * 2 + 40 * 3 + 30 * 4 + 10 * 5 = 5 + 30 + 120 + 120 + 50 = 325次。
那如果咱们优化一下条件的顺序呢?
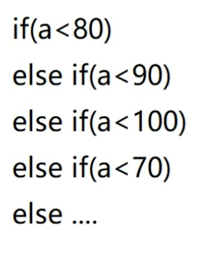
下面再来看一下对于100人的一个总的条件执行次数:

这三个都只会执行一次条件:

而

它会执行2次条件:

最后一个则需要执行3次:


所此经过条件顺序改造之后的总执行条件个数就变为了:5 * 1 + 15 * 1 + 40 * 1 + 30 * 2 + 10 * 3 = 150,以上整个过程就是一个压缩的非常标准的启萌思想。依据它我们可以用二叉树来表示这个条件,如下:
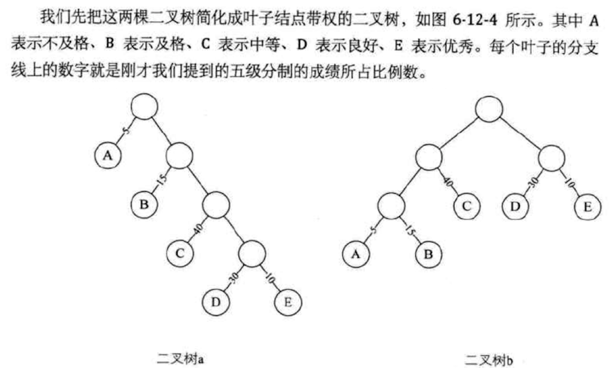

其中第一个概念为“路径长度”,再解释一下:

所以整个结果点的路径长度为:

所以如图所示:

而对于改良之后的二叉树此时的路径长度则为:
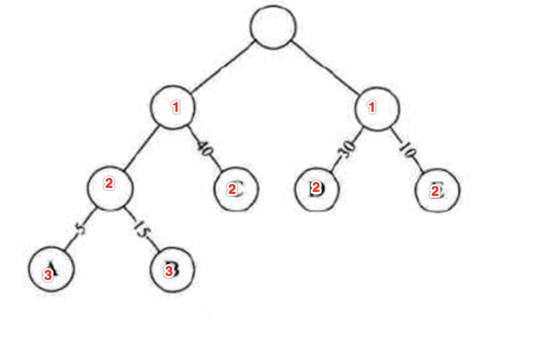
所以如图中说明:

很明显右边的整个树的路径长度就变短了。
其中还有一段话,也来理解一下:

其中标红处道出了Haffman树的一个定义了,那啥叫“带树路径长度”呢?比如说拿这个图来说:

其中每个结点上标出了其权重值,类似于分数的一个比例:,而这棵树的带权路径长度就为30【权值】x1【总共要经过的路径数,也就是边数】+30x1+15x2+15x2+5x3+10x3。
其中树上标的数字代表节点出现的次数,如:

树的构造:
上面对Haffman树的特点有了一个理论化的了解,那么。。该树的生成规则是如何生成的呢?下面来看下:
对于字母“A B C D E”,我们知道如果在Java中的Unicode编码一个字符占三个字节,而在ASCII码中一个英文字符占1个字节、中文字符占2个字节,而1个字节就是8位二进制,这里拿ASCII码来存这五个字符的话则需要5x8=40位二进制才能存储,接下来咱们来优化一下这种存储方式,比如:
A用1表示、B表0表示、C用10表示、D用11表示、E用101表示,此时存储这5个字节就只需要101011101(9位)这么多位就可以存储它们了,大大的缩减的存储空间,但是!!存储是优化了,但是如何来还原则ABCDE这样的数据呢?所以这种存法是不可逆的,接着Haffman编码就诞生了。
下面先来看一下Haffman树的构造理论说明,来自于书上:



看了上面的说明还是一头雾水,下面依照上面的理论步骤一条条来动手来构造一下,咱们来领略一下Haffman树构造的完美过程,其数列就如图中所说:


也就是:



此时树的形态就变为了:


此时树的形态就变为:
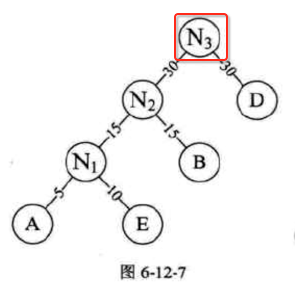


以上就是Haffman树的整个完整构建过程。
Haffman编码:
先来看一下它的一个思想:

解释一下:

这样数据就大大的压缩了,而且也能被逆序正确的读出来的。
好,上面了解了Haffman树的思想之后,下面则用代码来实现一下,首先定义好树的结点结构:

接下来则开始定义一个方法来实现Haffman树,如下:

接下来开始具体实现一下,按着步骤一步步来:
1、首先需要将结点进行排序,所以排下就成了:
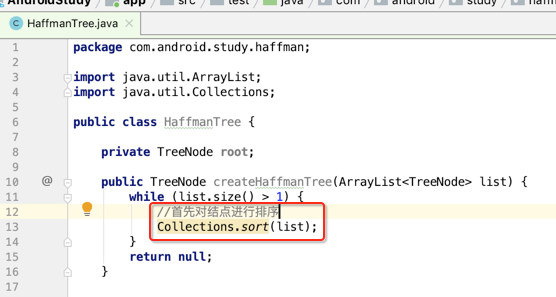
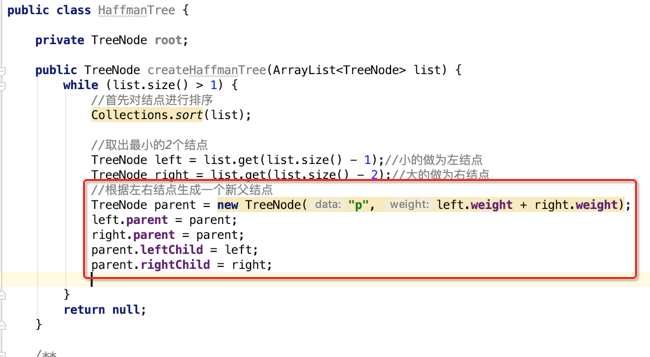
2、从有序数列中取出最小的两个结点:

接下来根据左右结点的权重相加生成一个它的父结点,如下:
接着将这两个结点从列表中删除,并用这个新结点替换之:
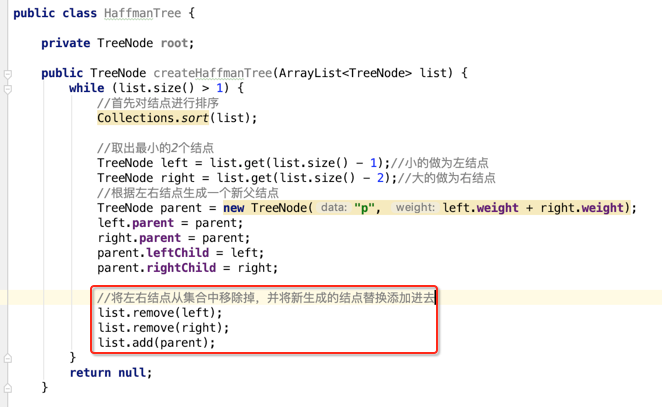
这样不断进行循环,则就将整个完整的Haffman树给建立起来啦,最后则将第一个结点做为整个树的根结点返回既可,如下:

好,接下来则需要打印生成的Haffman树,那如何打印呢?咱们按一层层的来打印,如下:
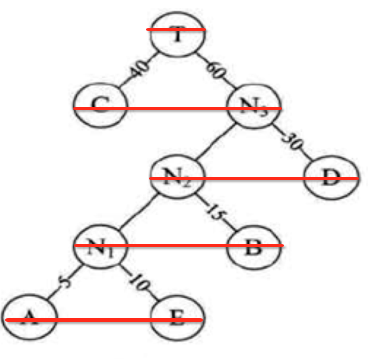
其中的N结果其实对于输出是没啥意义的,这个可以在输出时过滤掉,不过这里先不管过滤的事,先按这种规则来打印,具体如何实现呢,这里采用队列的方式,如下:

比较容易理解,下面来调用一下看下效果:
public class HaffmanTree { private TreeNode root; public TreeNode createHaffmanTree(ArrayList<TreeNode> list) { while (list.size() > 1) { //首先对结点进行排序 Collections.sort(list); //取出最小的2个结点 TreeNode left = list.get(list.size() - 1);//小的做为左结点 TreeNode right = list.get(list.size() - 2);//大的做为右结点 //根据左右结点生成一个新父结点 TreeNode parent = new TreeNode("p", left.weight + right.weight); left.parent = parent; right.parent = parent; parent.leftChild = left; parent.rightChild = right; //将左右结点从集合中移除掉,并将新生成的结点替换添加进去 list.remove(left); list.remove(right); list.add(parent); } //最后将第一个结点做为根节点 root = list.get(0); return root; } public void showHaffman(TreeNode root) { LinkedList<TreeNode> linkedList = new LinkedList<>(); linkedList.offer(root);//先将根结点入列 while (!linkedList.isEmpty()) { TreeNode treeNode = linkedList.pop(); System.out.println(treeNode.data); if (treeNode.leftChild != null) linkedList.offer(treeNode.leftChild); if (treeNode.rightChild != null) linkedList.offer(treeNode.rightChild); } } /** * 结点 */ public static class TreeNode<T> implements Comparable<TreeNode<T>> { private T data; private int weight;//权值 private TreeNode leftChild; private TreeNode rightChild; private TreeNode parent; public TreeNode(T data, int weight) { this.data = data; this.weight = weight; leftChild = null; rightChild = null; parent = null; } @Override public int compareTo(TreeNode<T> o) {//比较权重从大到小排 if (this.weight > o.weight) return -1; else if (this.weight < o.weight) return 1; return 0; } } @Test public void test() { ArrayList<TreeNode> list = new ArrayList<>(); TreeNode<String> node = new TreeNode<>("good", 50); list.add(node); list.add(new TreeNode("morning", 10)); list.add(new TreeNode("afternoon", 20)); list.add(new TreeNode("hell", 110)); list.add(new TreeNode("hi", 200)); HaffmanTree haffmanTree = new HaffmanTree(); haffmanTree.createHaffmanTree(list); haffmanTree.showHaffman(haffmanTree.root); } }
运行一下:

那下面咱们来手动梳理一下这个打印是否是对的:





按层次打印确实如输出的一样。
好接下来咱们来对此Haffman得到它某个结点的编码,其规则是左子树则用0,右子树则用1,如下:
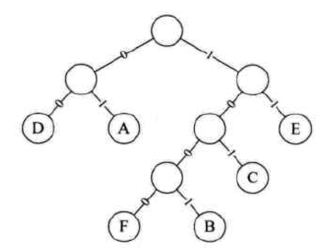
比如我想找A结点,则是从根搜索起,会经过01,所以A的Haff编码为01:
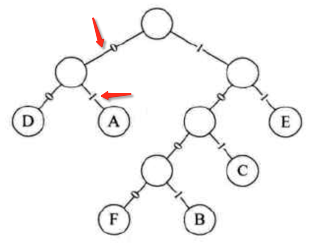
以此规则我们就可以把每个Haffman树上的结点得到相应的编码,如下:

那代码怎么来实现呢,先来挼一下其实现思路,还是以图中的A为例,我们可以先逆着找:
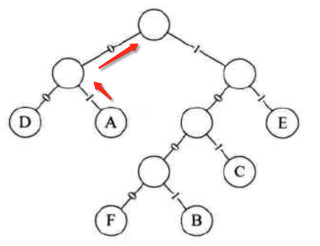
结果为10,然后将其找到的按顺序存到Stack当中,接着再取出元素则就逆过来输出来,也就是10,好,有了思路之后下面来实现一下,不难:
public class HaffmanTree { private TreeNode root; public TreeNode createHaffmanTree(ArrayList<TreeNode> list) { while (list.size() > 1) { //首先对结点进行排序 Collections.sort(list); //取出最小的2个结点 TreeNode left = list.get(list.size() - 1);//小的做为左结点 TreeNode right = list.get(list.size() - 2);//大的做为右结点 //根据左右结点生成一个新父结点 TreeNode parent = new TreeNode("p", left.weight + right.weight); left.parent = parent; right.parent = parent; parent.leftChild = left; parent.rightChild = right; //将左右结点从集合中移除掉,并将新生成的结点替换添加进去 list.remove(left); list.remove(right); list.add(parent); } //最后将第一个结点做为根节点 root = list.get(0); return root; } public void showHaffman(TreeNode root) { LinkedList<TreeNode> linkedList = new LinkedList<>(); linkedList.offer(root);//先将根结点入列 while (!linkedList.isEmpty()) { TreeNode treeNode = linkedList.pop(); System.out.println(treeNode.data); if (treeNode.leftChild != null) linkedList.offer(treeNode.leftChild); if (treeNode.rightChild != null) linkedList.offer(treeNode.rightChild); } } /** * 获得某个结点的二进制编码 */ public void getCode(TreeNode node) { TreeNode tNode = node; Stack<String> stack = new Stack<>(); while (tNode != null && tNode.parent != null) { if (tNode.parent.leftChild == tNode) stack.push("0"); else if (tNode.parent.rightChild == tNode) stack.push("1"); tNode = tNode.parent; } System.out.print("node【" + node.data + "】的Haffman编码为: "); //然后从栈中读出来则为结果 while (!stack.isEmpty()) { System.out.print(stack.pop()); } } /** * 结点 */ public static class TreeNode<T> implements Comparable<TreeNode<T>> { private T data; private int weight;//权值 private TreeNode leftChild; private TreeNode rightChild; private TreeNode parent; public TreeNode(T data, int weight) { this.data = data; this.weight = weight; leftChild = null; rightChild = null; parent = null; } @Override public int compareTo(TreeNode<T> o) {//比较权重从大到小排 if (this.weight > o.weight) return -1; else if (this.weight < o.weight) return 1; return 0; } } @Test public void test() { ArrayList<TreeNode> list = new ArrayList<>(); TreeNode<String> node = new TreeNode<>("good", 50); list.add(node); list.add(new TreeNode("morning", 10)); list.add(new TreeNode("afternoon", 20)); list.add(new TreeNode("hell", 110)); list.add(new TreeNode("hi", 200)); HaffmanTree haffmanTree = new HaffmanTree(); haffmanTree.createHaffmanTree(list); haffmanTree.showHaffman(haffmanTree.root); System.out.println("---------------"); haffmanTree.getCode(node); } }

AVL树(平衡二叉树):
概念:
先看一下它的概念:

而二叉排序树咱们在之前https://www.cnblogs.com/webor2006/p/11575167.html已经学习过了,其规则就是小的结点都往左放,而大的结点都往右放,但是!!在数据量比较大的情况下,很容易出现连续的数字,比如说:

如果用二叉排序树来表示就会成这样:
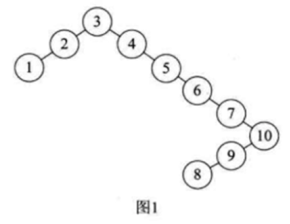
有木有发现都集中到右侧去了,当大数据量时其查找性能肯定会大大的降低,但是如果想办法能将这棵树:
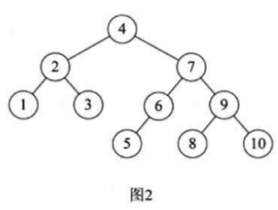
那性能也能保证,最终它也属于一棵排序二叉树,像这样的树其实就是属于平衡二叉树。根据概念的描述:

这是啥意思呢,这里拿上图来解释一下:
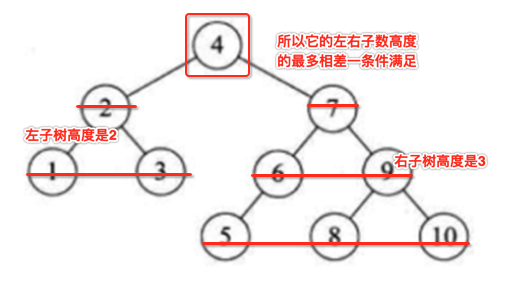
好,在了解了平衡二叉树的概念之后,下面来看几个树,来判断是否是平衡二叉树:

很明显不是的,比如说看"58",它的左子树的深度为2,而右子树木有,那它们之间的差值为2,不满足“每一个节点的左子树和右子树的高度差至多等于1”。

这个也很明显不是的,看下58这个结点。
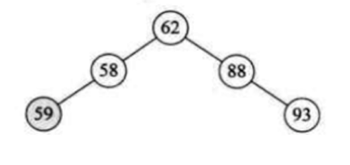
这棵肯定属于平衡二叉树。

这棵也是的,同样属于一个平衡二叉树。
下面需要再了解两个概念:
平衡因子:
二叉树上节点的左子树深度减去右子树深度的值称为平衡因子BF(Balance Factor),举例说明:

对于这个结点的平衡因子为左子树深度2-右子树尝试2=0。

而对于上面这个结点的平衡因子为左子树深度2-右子树尝试0=2。
最小不平衡树:
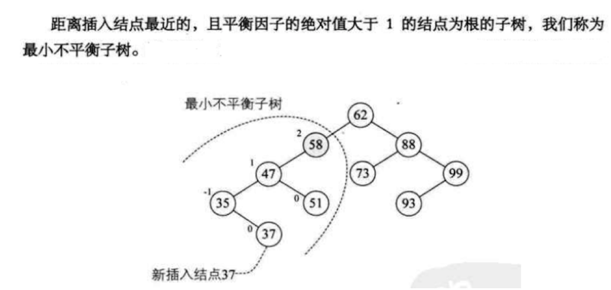
下面来解释一下,如图中所示我们新插入的节点是37:
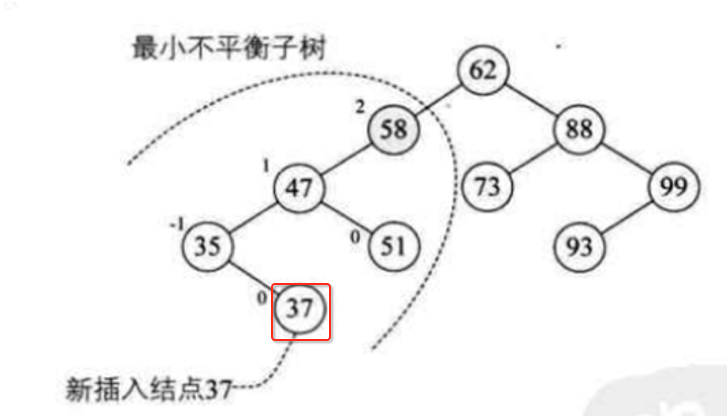
而接下来根据它来算各个结点的平衡因子,其中算到了58这个节点时,发现它的平衡因为2,大于1了:

那么最小不平衡子树就产生了,就是以这个58为根的子树则就叫做小小不平衡子树:

构建AVL树【开始涉及到左旋右旋的概念了】:
好,那AVL平衡二叉树的构建过程就变得很重要了,下面以这个数咱们来将其生成一棵AVL树:
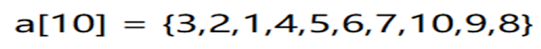
按着排序二叉树的规则拿“3,2,1”这三数其二叉树就会成这样:

目前3的平衡因子就变成了2,就打破了平衡二叉树的平衡规则了,所以此时为了让其平衡不被打破,就需要对它进行一下旋转,那是左旋还是右旋呢?这里画一个三角形:

很明显我们应该是要将左斜边的节点往右斜边进行平衡,也就是:

那此时就需要对它进行右旋转了:
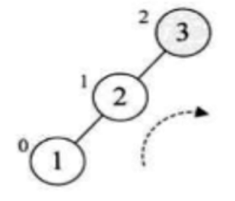
此时旋转之后就会变成:

经过右旋之后,一下又回到平衡树的状态了,接着继续添加第四个元素:

还是按照排序树的规则来添加,如下:

继续再添加第5个节点:
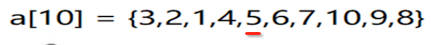

此时平衡二叉树又被打破了,接着当然又要开始旋转处理喽:

打破平衡的树为标三角形的地方,很明显应该是三角的右边往三角的左边来旋转,也就是:
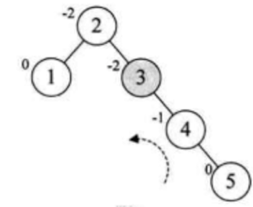
此时就变成:

此时又回到了平衡状态了,接下来再来添加元素:
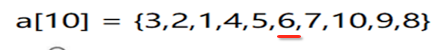
二叉树的形态就变为了:

此时平衡又被打破了,又得要做旋转处理了,此时发现跟之前旋转的形态有些变化了,不像之前的左旋和右旋都是没有相印子树的,比较好旋转,比如:
没有右子树,则往右旋。
没有左子树,则往左旋。
但是此时咱们这个没法旋了,为啥?
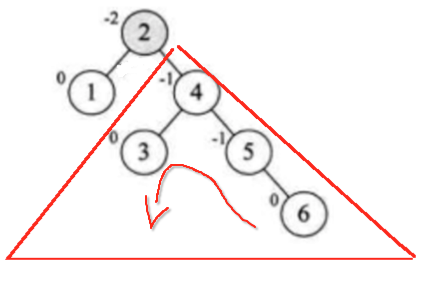
如果往左旋最终还是不平衡的,那此时怎么办呢?当不可旋转时,则可以往上延身一个结点来进行旋转,咱们这种情况其实也就是回到根结点来进行旋转,如下:

此时形态就会变为:
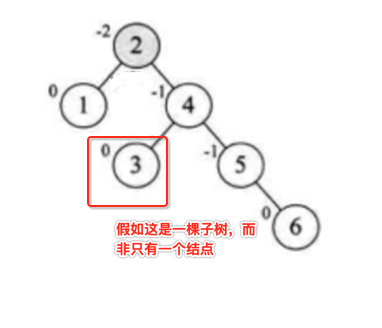
原来4的左子树的3结点就需要跟4进行比大小,由于它比4小,则应该放在4的左子树下,所以最后3就会放到:

此时又恢复平衡了,那此时有个问题,看图:
最终旋转时不管这么多,都会带着整个这个子树进行移动的,这里需要注意。
好,继续再添加元素:

此时又不平衡了:
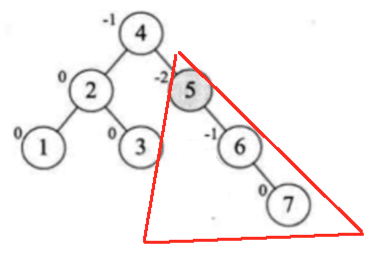
这个比较简单,直接左旋转就成了:
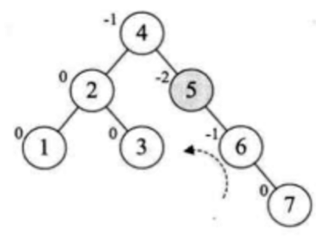
所以:
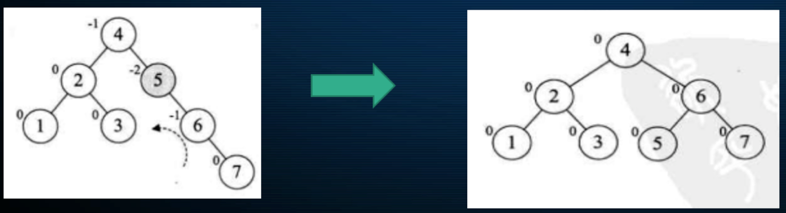
此时又回到平衡状态了,接下来再继续添加:
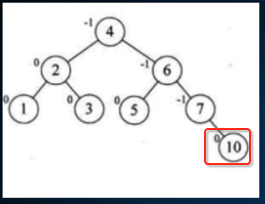
还是平衡的,继续再添加:
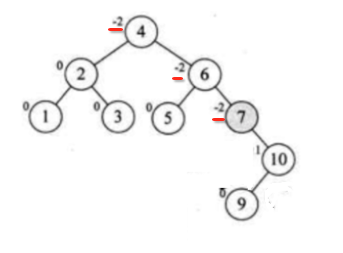
此时又不平衡了,接下来这个形态有点麻烦了,因为旋转之后看:
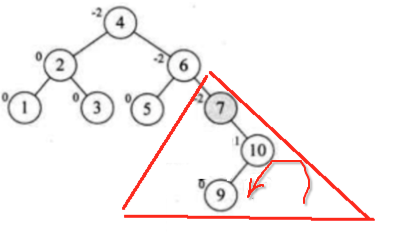
往左旋转之后,看:

此时就不是一棵二叉排序树了。。那咋办呢?此时又有一个新规则出现了,此时先将这俩数通过右旋转交换一下:

那此时就变为:
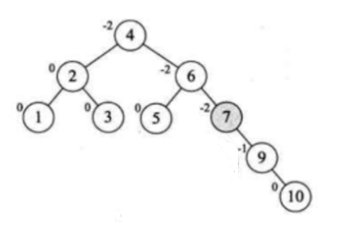
此时再进行左旋转:
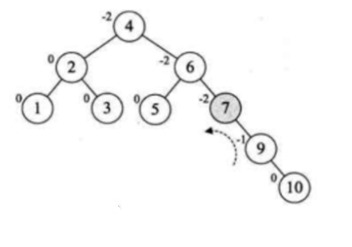
又恢复平衡啦,继续再添加:


此时又不平衡了,然后进行旋转呗:

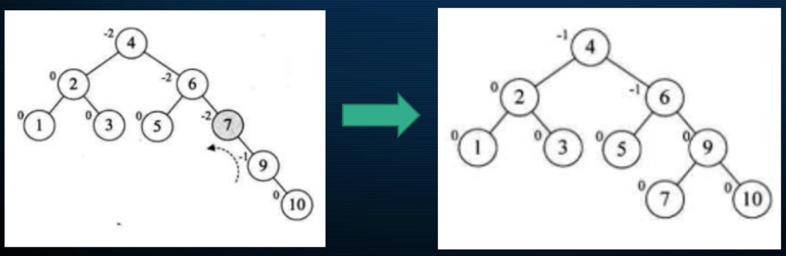
发现9这个结点已经有了左右子数了,貌似没法进行旋转,这又是一种新规则,这样来搞:
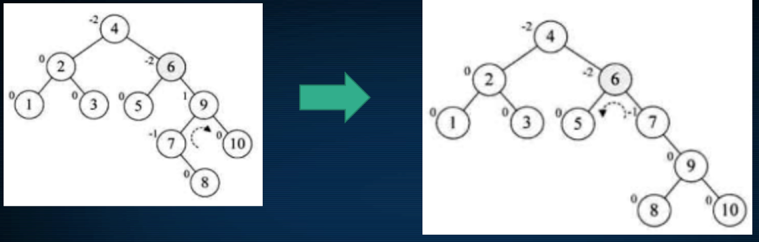
往右一转,此时再基于它的父结点进行左旋转,最后就成了这样了:
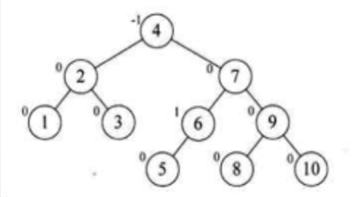
呃,真的是最后这一个旋转有点懵逼,先了解一下吧,到时还得想办法变成代码,想想就觉得可怕。。其实关于旋转是有套路可循的,咱们先来对左旋转这个套路先将其代码化,先搭建个树的框架:

接下来就集中精力来实现左旋的代码,先来看一下左旋的示例图:

咱们则根据上图具体来实现一下:
public class AVLBTree<E extends Comparable<E>> { Node<E> root; int size; public class Node<E extends Comparable<E>> { E element; int balance = 0;//平衡因子 Node<E> left; Node<E> right; Node<E> parent; public Node(E element, Node<E> parent) { this.element = element; this.parent = parent; } } public void left_rotate(Node<E> x) { if (x != null) { Node<E> y = x.right;//先取到Y //1.把贝塔作为X的右孩子 x.right = y.left; if (y.left != null) { y.left.parent = x; } //2。把Y移到原来X的位置上 y.parent = x.parent; if (x.parent == null) { root = y; } else { if (x.parent.left == x) { x.parent.left = y; } else if (x.parent.right == x) { x.parent.right = y; } } //3.X作为Y的左孩子 y.left = x; x.parent = y; } } }
这种思想用一个具体的二叉树再来看一下左旋转:

知道了左旋转的实现之后,右旋转就比较简单了,这个在下一次再继续学习。