mybatis 是一个半ORM(对象关系映射)框架 支持对象与数据库的ORM字段关系映射,内部封装了jdbc
在查询关联对象时,需要手动编写 sql 来完成 sql写在 xml里,解除 sql 与程序代码的耦合,便于统一管理
一、流程与逻辑
编程式使用的方法:
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession session = sqlSessionFactory.openSession();
try {
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
System.out.println(user);
} finally {
session.close();
}
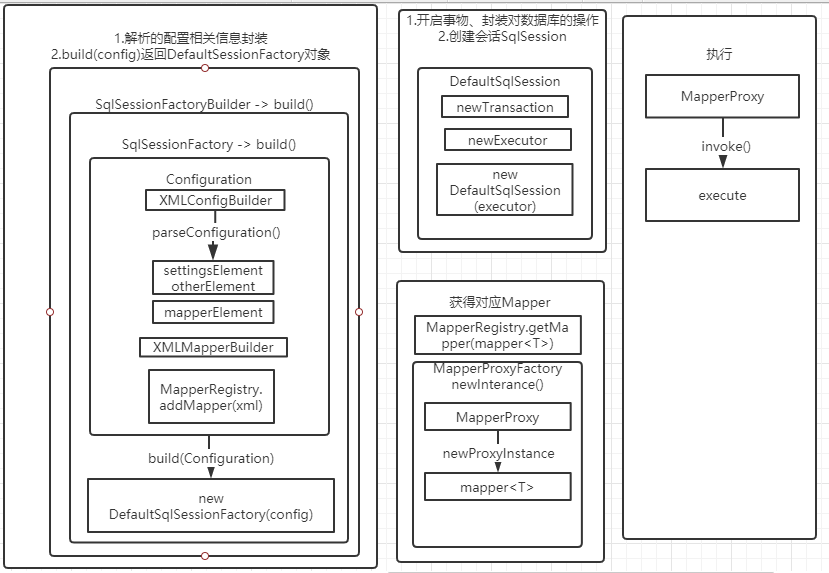
1.通过建造者模式创建一个工厂类SqlSessionFactory,定位,加载,解析 封装 配置文件的就是在这一步完成的(mybatis-config.xml 和Mapper xml文件)
(MapperRegistry 也在Configuration 里面)
2.通过SqlSessionFactory 创建一个SqlSession
3.获得Mapper 对象
4.调用接口方法
常用设计模式 有构造者模式、装饰器模式、工厂方法模式 等 后面详解
二、没有手写mapper实现类
在加载阶段时 MapperRegistry 里面维护了一个Map 容器,存储接口和代理工厂的映射关系 (key = Mapper class value = 创建当前Mapper的工厂)
在解析mapper 标签和Mapper.xml 的时候已经把接口类型和类型对应的MapperProxyFactory 放到了一个Map 中。
获取Mapper 代理对象,从Map 中获取对应的工厂类后,最终通过代理模式返回代理对象
三、一二级缓存
将用户经常查询的数据的结果的一个保存,保存到一个内存中(缓存就是内存中的一个对象)
加入缓存后 先去缓存中查询数据 如命中则通过内存中返回 ,反之则查询数据库并同步至缓存中,mybatis在做增删改时会清理掉对应数据的缓存
一级缓存是MyBatis天然自带的,是默认开启且没有关闭的地方,1级缓存只能使用一个sqlSession作用于查询回话中,所以也叫会话缓存
一级缓存需要注意:
和spring整合后进行mapper代理开发,不支持一级缓存
一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据。
二级缓存也称为全局缓存是mapper级别的缓存,是针对一个表的查结果的存储,可以共享给所有针对这张表的查询的用户。
也就是说对于mapper级别的缓存不同的sqlsession是可以共享的
config.xml设置二级缓存开关<setting name="cacheEnabled" value="true"/>
开启本Mapper的namespace下的二级缓存<cache eviction="LRU" flushInterval="10000"/>
二级缓存需要注意:
缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响。但刷新缓存是刷新整个 namespace 的缓存,也就是update 了一个, 则整个缓存都刷新
最好在 「只有单表操作」 的表的 namespace 使用缓存, 而且对该表的操作都在这个 namespace 中。 否则可能会出现数据不一致的情况
一级二级缓存都采用 PerpetualCache类实现Cache接口,内部使用HashMap 存储
四、延迟加载
先从单表查询、需要时再从关联表去关联查询,大大提高 数据库性能,因为查询单表要比关联查询多张表速度要快
如果查询订单并且关联查询用户信息。如果先查询订单信息即可满足要求,当我们需要查询用户信息时再查询用户信息。把对用户信息的按需去查询就是延迟加载
resultMap可以实现高级映射(使用association、collection实现一对一及一对多映射),association、collection具备延迟加载功能
开启延迟加载:<setting name="lazyLoadingEnabled" value="true"/>
五、#{}和${}
#{}是预编译处理(预编译是提前对SQL语句进行预编译,而其后注入的参数将不会再进行SQL编译,所以恶意注入都变成字符串)
${}是字符串替换 ($ 符号一般用来当作占位符)
处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;使用 #{} 可以有效的防止SQL注入,提高系统安全性。
#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号
处理${}时,传入的数据直接显示生成在sql中。“${xxx}”这样格式的参数会直接参与SQL编译,从而不能避免注入攻击