十行代码爬取多页数据
有一个需求,获取www.weidawang.xyz网站中的所有文章名称。
如下图所示:

有一个问题,由于文章较多,文章是分页展示的,每页展示15篇。
如何能够尽可能简单的获取所有博文名称呢?
很简单,只需要三步:
- 发送请求,获取网页数据
- 解析数据
- 获得结果
完整代码见文末
工具准备
- 安装
requests模块,用于发送get请求。
pip install requests
- 安装
bs4模块,用于解析html代码。
pip install beautifulsoup4
安装不成功的话,记得升级pip版本:pip install -U pip
知识准备
requests如何发送get请求
resp = requests.get(url)
get请求返回的Response对象
| 属性 | 描述 |
|---|---|
| resp.status_code | Response状态码,200为成功 |
| resp.text | Response内容文本,就是我们想要的数据 |
| resp.encoding | 从header中猜测的内容编码格式 |
| resp.apparent_encoding | 从内容分析出来的编码格式 |
| r.content | Response内容的二进制形式 |
通常,我们只需要使用 resp.text 就好了。
- 使用
bs4解析html
bs4.BeautifulSoup(resp.text,"html.parser")
以上代码返回值,就是解析后的 html 代码
css选择器
利用 bs4 对象的 select() 方法,选择我们想要的 html 元素对象。
操作步骤
- 进入www.weidawang.xyz,点击页面底部分页按钮,观察网址变化。
如下图所示:
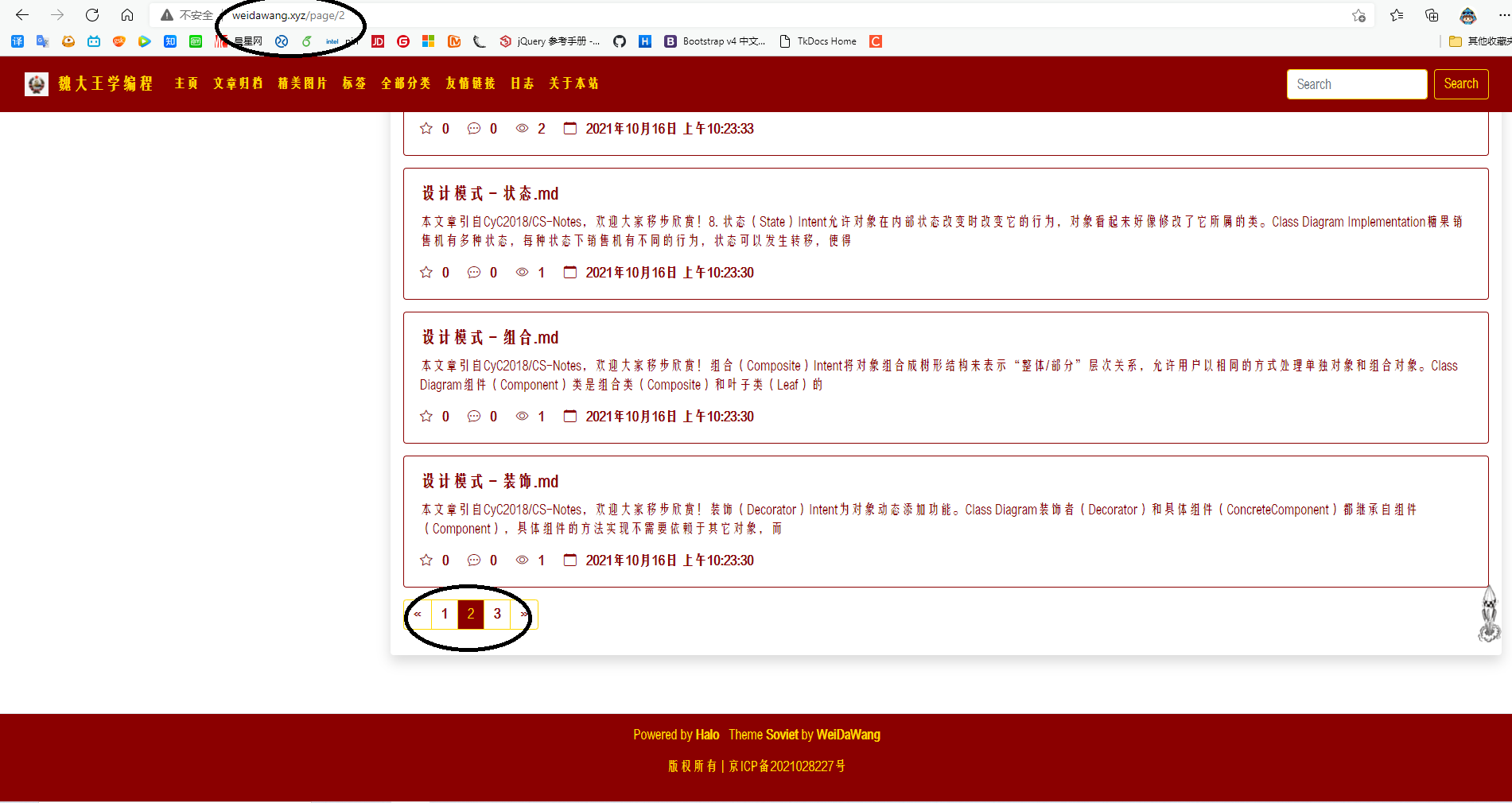
需要注意的是,当我们选择第2页时,网址变成了www.weidawang.xyz/page/2
也就是说,www.weidawang.xyz/page/3代表的是第三页!
所以,我们可以用以下代码,获取所有页面数据:
url = "http://weidawang.xyz/page/"
for i in range(100):
resp= requests.get(url+str(i+1)) # 获取页面 html 代码
if(resp.status_code==200): # 判断请求是否成功
# req.encoding='utf-8' # 如果出现乱码记得加上
bs = bs4.BeautifulSoup(resp.text,"html.parser") # 解析 html 数据
- 进入www.weidawang.xyz,点击
F12观察网页源码结构,定位我们想要的对象。
如下图所示:
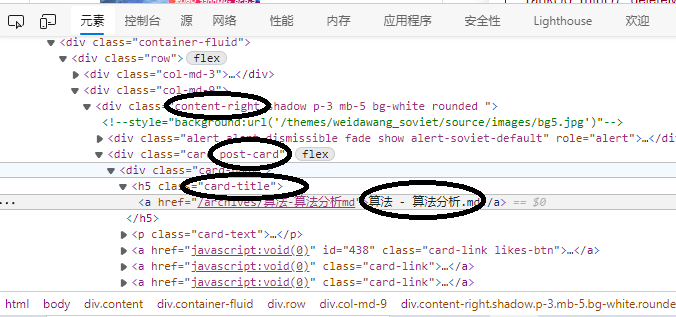
我们的目的地是在 class content-right -> post-card -> card-title -> a 标签中。
所以,我们可以通过以下代码,获取所有符合要求的 a 标签:
l = bs.select(".content-right .post-card .card-title a")
- 获得结果
然后我们可以对获得的 a 标签列表执行以下代码,获取内部文字值:
for itm in l:
print(itm.get_text())
补充知识
有时候,我们需要的不是标签中的文字,而是标签中的某个属性值,比如 href、id,这个使用只需要对标签元素使用 get() 方法就能获得对应的值。
例如,针对标签 itm:
itm.get("href") # 获取 href 值
itm.get("id") # 获取 id 值
完整代码
赶快去尝试吧!
import bs4
import requests
url = "http://weidawang.xyz/page/"
for i in range(100):
resp= requests.get(url+str(i+1))
if(resp.status_code==200):
# req.encoding='utf-8'
bs = bs4.BeautifulSoup(resp.text,"html.parser")
l = bs.select(".content-right .post-card .card-title a")
for itm in l:
print(itm.get_text())