今天处理了一些数据量很大的表,拿其中一个来做总结
对数据表在执行不明白原理的命令之前一定要备份好数据表,不要随意终止你不清楚底层原理的命令,因为很可能就会造成表的损坏,比如optimize命令
事情是这样的,最近在整理一个几亿的数据表,因为数据表太大,在执行插入等操作的时候变得非常慢,而我决定优化这个表
之前自己建了一个新表,没有多大的数据量,因为在删除表之后,需要把磁盘空间释放一下,
比如在自己建的表操作
知识点之一:执行delete删除的时候,mysql并没有把数据文件删除,而是将数据文件的标识位删除,没有整理文件,因此不会彻底释放空间,被删除的数据将会保存在一个连接清单中,当有数据写入mysqsl利用这些已删除的空间再写入,删除操作会带来一些数据碎片,正是这些碎片在占用硬盘空间,官方文档上写的是innodb引擎的可以利用操作系统来帮忙回收这些碎片,myisam的标没有办法自己回首。
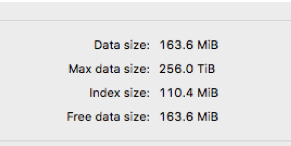
官方推荐使用命令是optimize table 表名 . 之后再看数据
因为这个是新表,空间也没有很大,没有人用,所以在执行optimize命令的时候很快 但是!执行线上的表就有问题
后来了解到这个表有人在实时的往里写数据,而且存储引擎还是myisam,而且这个表存放的数据上亿
表数据:
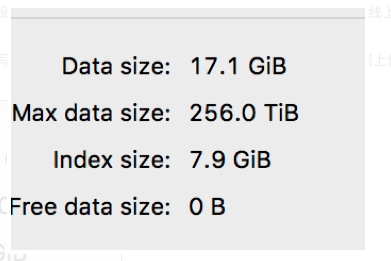
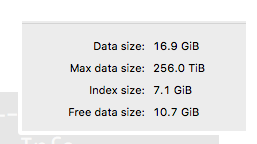
然后我执行了删除其中的一个月份数据,看到的空闲空间是
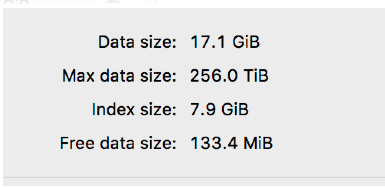
最后删除其中一部分备份过的数据后,空闲的空间是:
执行了 optimize命令的过程,看进程
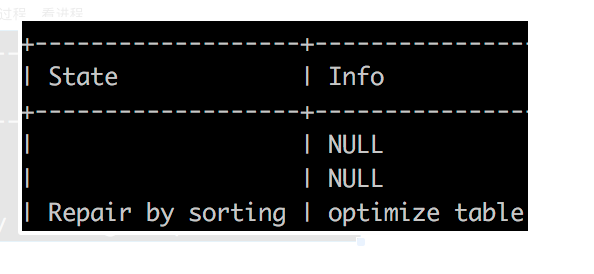
如果在这个过程中不小心终止了进程,就会出现 Table './库名/表名' is marked as crashed and last (automatic?) repair failed提示!!!
执行了check table 表名后:
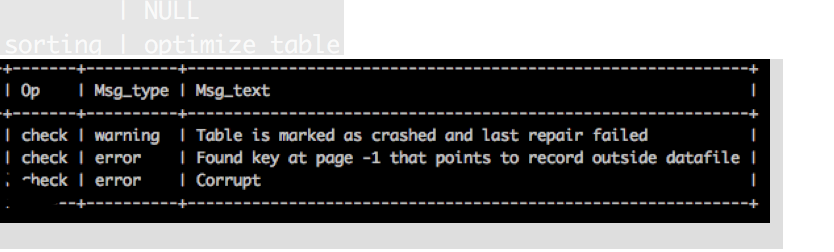
是这个提示!!大概意思就是表坏了 一谷歌全是让你修复表的
执行了repair table 表名,然后就等了十几分钟就开始报超时,对 就是Lost connection to MySQL server during query
因为我这个上亿的表数据实在太大了,空间根本就不够,
然后开始查原因
一个是mysql允许的最大数据包设置,就是sql操作的时间过长,或者传送的数据太大,这样可以修改max_allowed_packet配置参数
另一个执行show global variables like '%timeout'; 看一下wait_timeout、interactive_timeout参数把它改大我设置的都是28800也就是八小时,后来执行修复的命令在八小时内弄完了谢天谢地
后来两次执行的repair命令都自动超时断开,但是show processlist后看到这个进程还在,因为无知,kill掉这个进程之后再看数据表,几亿的数据只剩一条。。。一条数据。。。后来我们就琢磨是不是kill的原因,最后用最后一条数据做了实验,果然。。。。
具体引用大神的解释:

后来考虑到我有17G的数据,然后就把参数myisam_max_sort_file_size设置了18G,这个参数的意思是mysql重建索引时所允许的最大临时文件的大小还有参数myisam_sort_buffer_size表示myisam表发生变化时重新排序所需的索引缓冲
设置完以上参数后
执行mysqlcheck -hdatabasehost -uuser -ppassword database table -c //检查这个损坏的表
返回
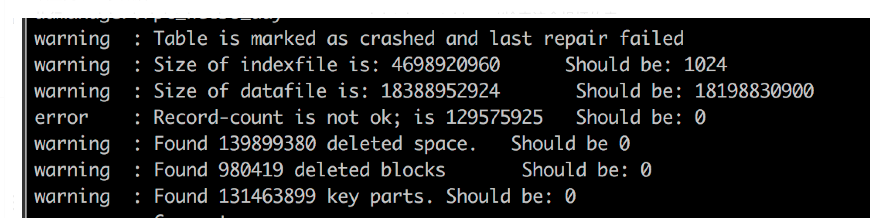
非常清楚的显示了表现在的问题
执行 mysqlcheck -hhost -uuser -ppassword database table -r
之后 经历了漫长的等待之后返回的结果就是:

我们其实还做了plan B 就是从从库中把表导出,也确实导出来了,35个G。。。正准备怎么替换的时候执行完成了,
最后郑重的感谢大热天帮忙的兄弟,总之 感谢身边的人 让我还能安稳的活着 本来 以为 这是我在公司的最后一天的。。。。
总结:备份 备份!还有不清楚的命令千万不要去设置
既然修复表好了之后,工作还得继续,后续做的方案就是不能直接执行优化表,因为一不知道具体时间多长时候会影响别的端使用
第一次使用的方案是,新建一张一摸一样的表,但是不加索引,然后把这种表导入到新表,用insert。。 select 很快因为没有索引,导入完之后再加索引,第一个索引很快,第二个就超时了。。。fail
第二次使用的方案就是直接建一张带索引的新表,然后使用shell脚本把数据导入,花费六个多小时吧,最后检查两张表数据是否一致并且使用left join 或者抽查数据是否一致,这些工作都做完之后就准备修改表名
因为使用alter table 表名 rename to 新表名,这样执行其实是很快的 ,但是也得确保这个时候用的人很少,而且还要看进程有没有锁表的查询之类的,如果没有,就可以执行了
非常快 不用一秒,完成。
这样整体任务完成
现在可以用老表做实验,看看优化表操作可以用多久,最后发现优化10G的空间用了49分钟
那这样的话推测一百多兆的空间应该是很快的,感觉自己要学习的东西太多,加油。。。