性能下降SQL慢 、执行时间长 、 等待时间长 常见原因:
1.查询语句写的烂
2.索引失效
#id name email weixinNumber select *from user where name=""; select *from user where name="" and email=""; create index idx_user_name on user(name);#单值 create index idx_user_nameEmail on user(name,email);#复合
2.关联查询太多join(设计缺陷或不得已的需求)
3.服务器调优及各个参数设置(缓冲线程数等)
#手写sql的顺序 7 select 8 distinct <select_list> 1 from <left_table> 3 <join_type> join <right_table> 2 on <join_condition> 4 where <where_condition> 5 group by <groupby_list> 6 having <having_condition> 9 order by <orderby_conditoin> 10 limit <limit number>; #机读 1. FROM <left_table> 2. ON <join_codition> 3. <join_type> JOIN <right_table> 4.WHERE <where_condition> 5. GROUP BY <group_by_list> 6. HAVING <HAVING_condition> 7. SELECT 8. DISTINCT <select_list> 9. ORDER BY <order_by_condition> 10. LIMIT <limit_number>
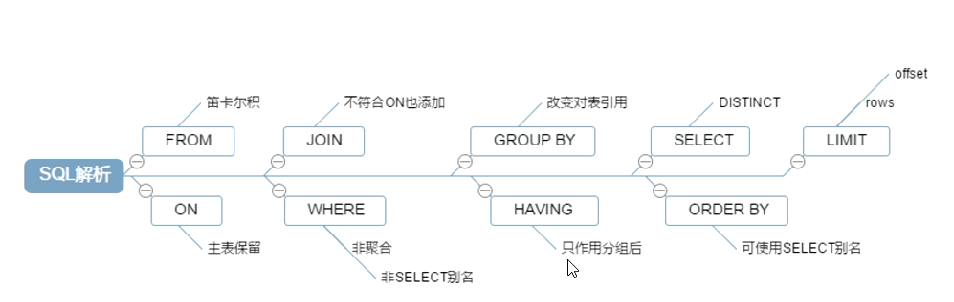
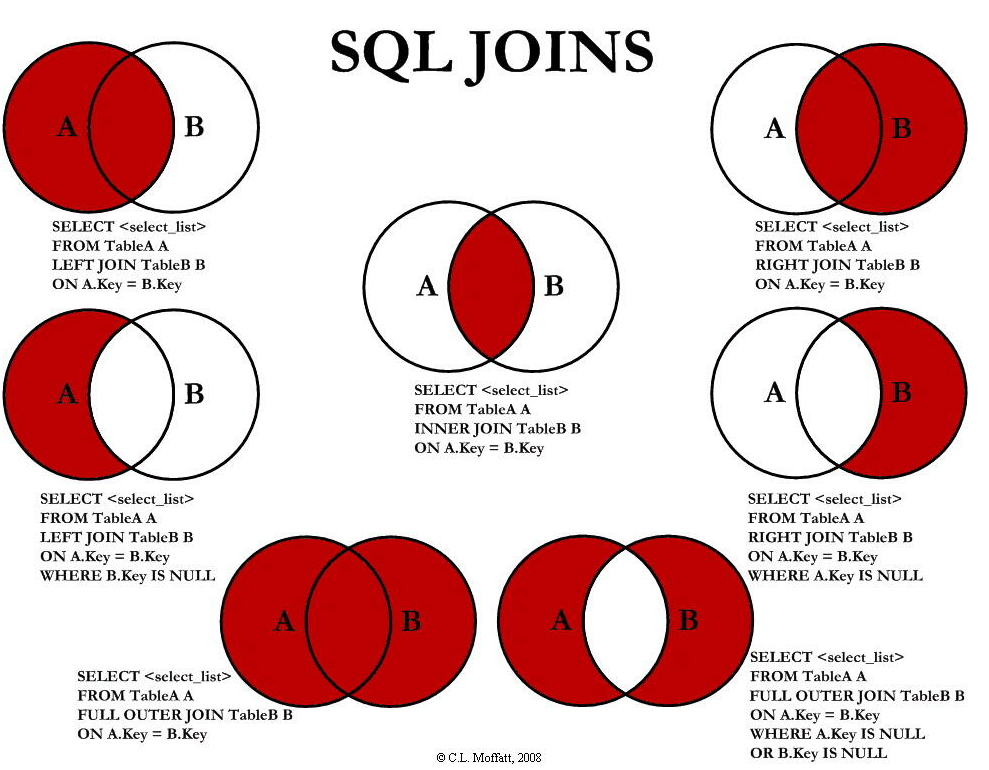
#join 7 用法 #1.left join select * from tbl_emp a left join tbl_dept b on a.deptId=b.id ; #2.left join select * from tbl_emp a left join tbl_dept b on a.deptId=b.id where b.id is null; #3.right join select * from tbl_emp a right join tbl_dept b on a.deptId=b.id; #4.right join select * from tbl_emp a right join tbl_dept b on a.deptId=b.id where a.deptId is null; #5.inner join select * from tbl_emp a inner join tbl_dept b on a.deptId=b.id; #6. mysql 中不支持full outer join,可使用left join... union right join...实现 select * from tbl_emp a left join tbl_dept b on a.deptId=b.id union select * from tbl_emp a right join tbl_dept b on a.deptId=b.id; #7. mysql 中不支持full outer join,可使用left join... union right join...实现 select * from tbl_emp a left join tbl_dept b on a.deptId=b.id where b.id is null union select * from tbl_emp a right join tbl_dept b on a.deptId=b.id where a.deptId is null;
#案例sql CREATE TABLE `tbl_dept` ( `id` int(11) NOT NULL AUTO_INCREMENT, `deptName` varchar(30) DEFAULT NULL, `locAdd` varchar(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; CREATE TABLE `tbl_emp` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `deptId` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `fk_dept_id` (`deptId`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
是什么
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高校获取数据的数据结构。可以得到索引的本质:索引是数据结构。
索引的目的在于提高查询效率,可以类比字典eg:要查找“mysql”这个单词,我们可定需要定位到m字母,然后从上往下找到y字母,在找到剩下的sql
你可以简单理解为"排好序的快速查找数据结构"。
详解(重要):在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指引 (指向)数据。
结论:数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以文件形式存储在硬盘上 我们平时所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉树)结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种类型的索引之外,还有哈希索引(hash index)等。
优势
类似大学图书馆建书目索引,提高数据检索效率,降低数据库的IO成本
通过索引列对数据进行排序,降低数据排序成本,降低了CPU的消耗
劣势
实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如果对表INSERT,UPDATE和DELETE。 因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立优秀的索引,或优化查询语句
mysql索引分类
单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引 ps:建议一张表索引不要超过5个,优先考虑复合索引
唯一索引 :索引列的值必须唯一,但允许有空值
复合索引 :即一个索引包含多个列
主键索引,主键自动的为主索引 (类型Primary) 唯一索引 (UNIQUE) 普通索引 (INDEX) 全文索引 (FULLTEXT) [适用于MyISAM] sphinx + 中文分词 coreseek [sphinx 的中文版 ] 综合使用=>复合索引**简述mysql四种索引的区别 PRIMARY 索引 =》在主键上自动创建 UNIQUE 索引=> 只要是UNiQUE 就是Unique索引.(只能在字段内容不重复的情况下,才能创建唯一索引) INDEX 索引=>就是普通索引 FULLTEXT => 只在MYISAM 存储引擎支持, 目的是全文索引,在内容系统中用的多, 在全英文网站用多(英文词独立). 中文数据不常用,意义不大 国内全文索引通常 使用 sphinx 来完成,全文索引只能在 char varchar text字段创建. **全文索引案例 1.创建表 create table news(id int , title varchar(32),con varchar(1024)) engine=MyISAM; 2.建立全文索引 create fulltext index ful_inx on news (con); 3.插入数据 这里要注意,对于常见的英文 fulltext 不会匹配,而且插入的语句本身是正确的. ‘but it often happens that they are not above supporting themselves by dishonest means.which should be more disreputable.Cultivate poverty like a garden herb’ 4.看看匹配度 mysql> select match(con) against('poverty') from news; +-------------------------------+ | match(con) against('poverty') | +-------------------------------+ | 0 | | 0 | | 0 | | 0.9853024482727051 | +-------------------------------+ 0表示没有匹配到,或者你的词是停止词,是不会建立索引的. 使用全文索引,不能使用like语句,这样就不会使用到全文索引了. select * from news where match(con) against(‘poverty’); **复合索引 create index 索引名 on 表名(列1,列2);
#基本语法 ALTER TABLE emp ADD INDEX (empno); ALTER TABLE emp DROP INDEX empno; SHOW INDEXES FROM emp G; #创建 CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length)); #如果是CHAR,VARCHAR类型,length可以小于字段实际长度; #如果是BLOB和TEXT类型,必须指定length。 ALTER mytable ADD [UNIQUE] INDEX [indexName] ON(columnname(length)); #删除 DROP INDEX [indexName] ON mytable; #查看 SHOW INDEX FROM table_nameG #使用alter命令: #有四种方式来添加数据表的索引 alter table tbname add primary key (column_list);#该语句添加一个主键,这意味着索引值必须是唯一的,且不能为null; alter table tbname add unique index_name(column_list);#这条语句创建索引的值必须是唯一的(除null外,null可能会出现多次); alter table tbname add index index_name(column_list);#添加普通索引,索引值可以出现多次; alter table tbname add fullindex index_name(column_list);#该语句指定了索引为fullindex,用于全文索引
BTree索引(*)重点
Hash索引(了解)
full-text全文索引(了解)
R-Tree索引(了解)
何时使用索引
哪些情况需要创建索引
1.主键自动建立唯一索引
2.频繁作为查询的条件的字段应该创建索引
3.查询中与其他表关联的字段,外键关系建立索引
4.频繁更新的字段不适合创建索引 因为每次更新不单单是更新了记录还会更新索引,加重IO负担
5.Where条件里用不到的字段不创建索引
6.单间/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
7.查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
8.查询中统计或者分组字段
哪些情况不要创建索引
1.表记录太少
2.经常增删改的表 why:提高了查询速度,同时却会降低更新表的速度,如对表的insert,update,delete.因为更新表时候,mysql不仅要保存数据,还要保存一下索引文件.更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1 select * from emp where sex = '男'
例如:假如一个表中有十万行记录,有一个字段a,a只有T和F两种值,且每个值的分布概率大概约为50%,那么对这种表的a字段建立索引一般不会提高数据库的查询速度索引的选择性是指索引列中不同值的数目与表记录数的比。如果一个表有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0,99,一个索引的选择性越接近于1,这个索引的效率就越高
MySQL常见瓶颈
CPU:CPU在饱和的时候一般发生在数据装入在内存或从磁盘上读取数据时候
IO:磁盘I/O瓶颈发生在装入数据远大于内存容量时
服务器硬件的性能瓶颈:top,free,iostat和vmstat来查看系统的性能状态