监督学习
按照经验数据分类:监督学习、无监督学习、强化学习。
监督学习框架:f(x)=y
训练:函数f
测试:将训练好的函数f应用到测试样本x,输出预测结果y=f(x)
监督学习方法:线性回归、分类-k最近邻、分类-逻辑回归、分类-支持向量机等等。
机器学习三要素:方法=模型表达+目标函数+优化算法。
模型表达:模型的表达式或者假设空间
目标函数:模型的优化目标
优化算法:求解最优模型参数的算法
实例:根据训练样本,学习以4个布尔变量为输入,1个布尔变量为输出的函数y=f(x1,x2,x3,x4)
2种输出,16种输入,一共有2^16种 f函数。
题目给出7种输出的情况,则满足所有训练样本的函数f仍然有2^9种可能。
某个假设空间:m of n:n个变量中有m为真,则输出y为真。此时只有32种可能的函数。
只有(x1,x3,x4)里面有两个为真,才满足所有的7种训练样本。
不同的模型表达规定了不同的假设空间:实例、超平面、分叉树、图模型、神经网络、模型集成。
目标函数:按照什么目标去训练模型?
均方误差、正确率、似然概率、后验概率、交叉熵等等。
优化算法:优化策略有组合优化(例如贪婪搜索)、凸优化(例如梯度下降法)等等。
线性回归
线性回归:线性回归的定义、最小二乘法、欠拟合等等。
线性模型:f(a*w1+b*w2)=af(w1)+bf(w2)
注意:机器学习的变量是参数,不是输入!!!
线性模型的优点:形式简单、易于建模、可解释性强。
例子:好瓜、坏瓜
目标函数:通过均方误差求解。
优化:最小化均方误差:
如果考虑偏移:有小b
优化算法:最小二乘法,对未知数w求导,获得闭式解。
常用的对向量求导公式:
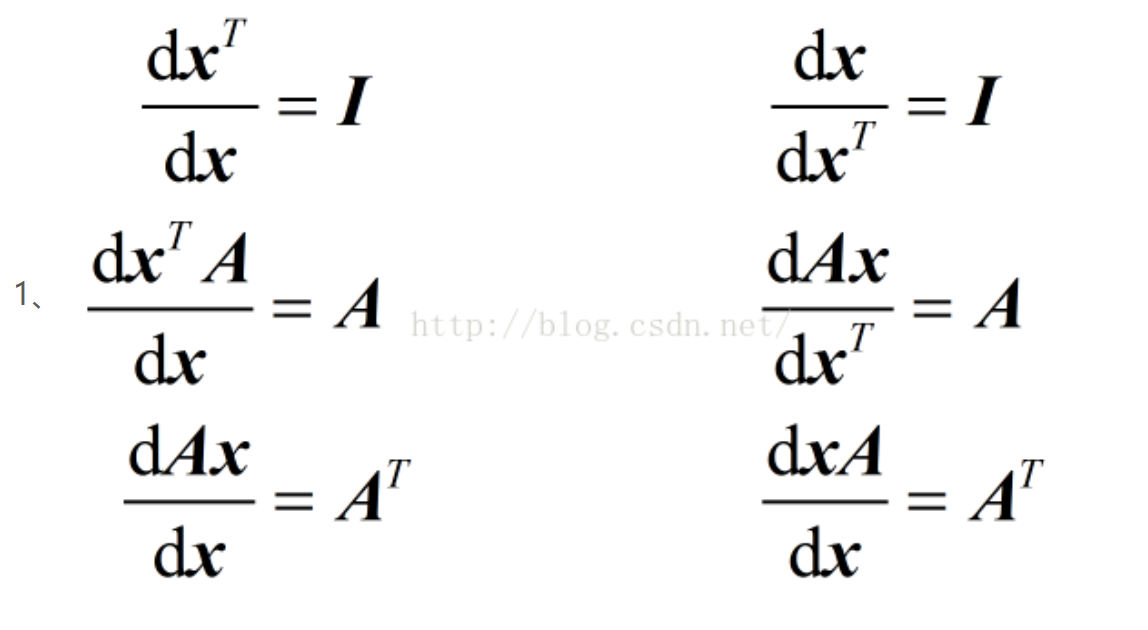
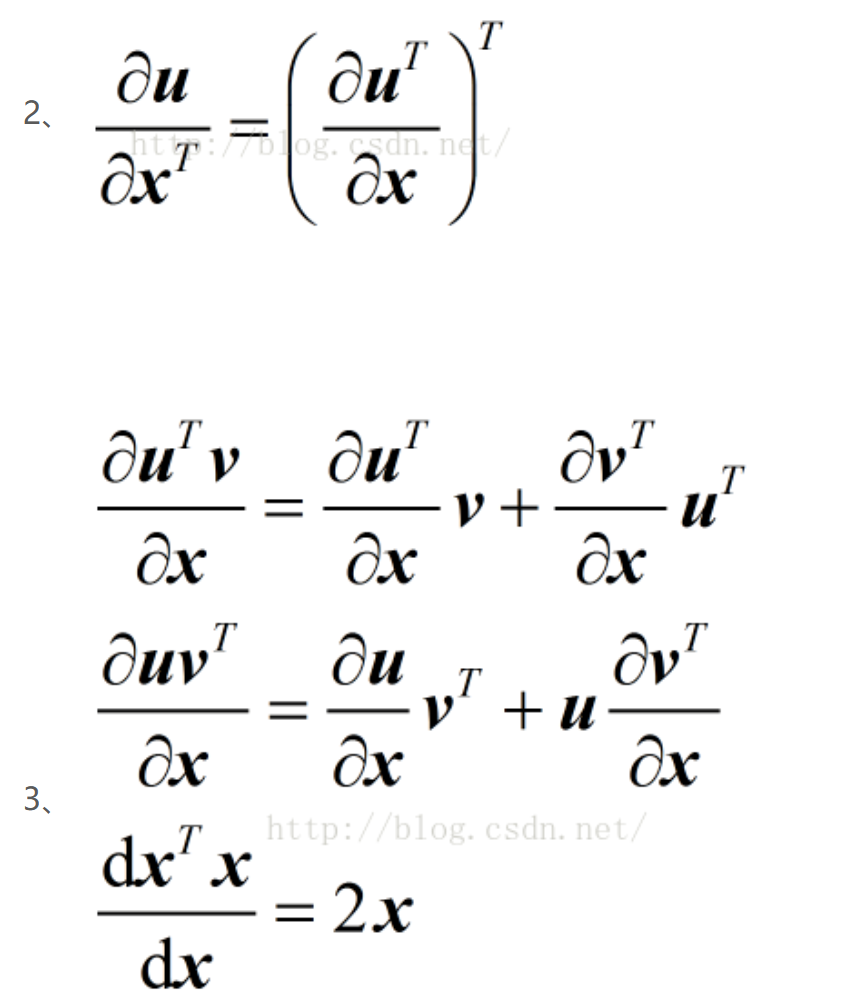
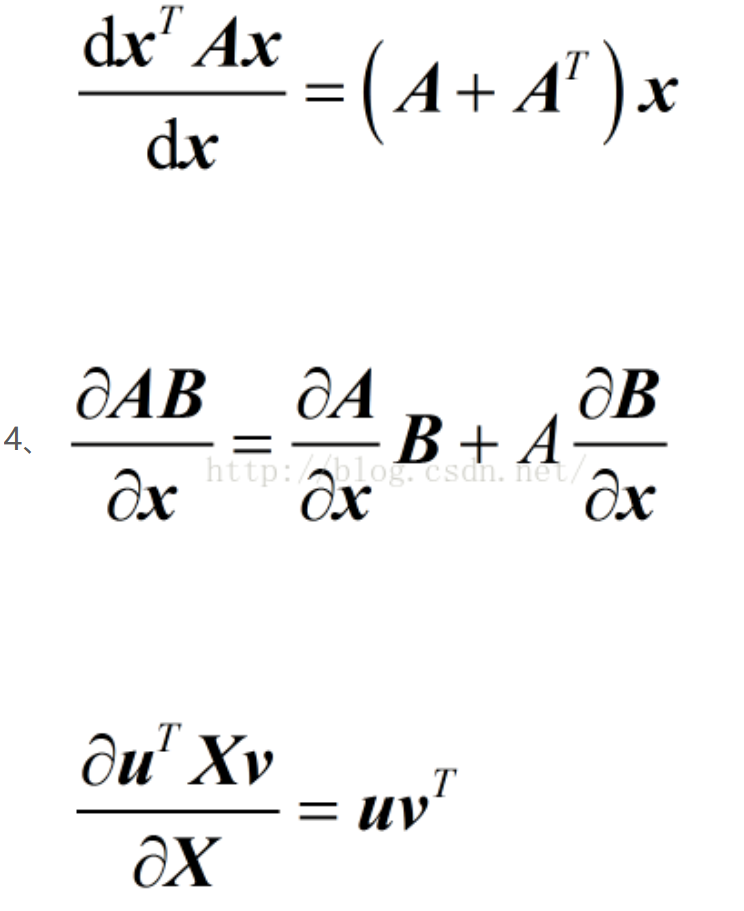
异常数据(outlier)的影响:拟合数据,但是不一定是最理想的模型。
鉴别它的方法:标准化残差值。
应对它的方法:自主法(Bootstrapping)。
欠拟合(underfitting):模型太简单,会导致欠拟合。解决办法有:非线性映射,原始数据转换数据,对输出x进行非线性,注意模型仍然是线性模型。
下节课,涉及欠拟合和过拟合。