博主当初也曾一度对python的对象引用机制晕头转向,毕竟之前也只是对c泛泛有一些了解,在阅读过《流畅的python》这一章节之后,就豁然开朗。目前来说,这是最让博主兴奋的一章,里面不仅详细介绍了变量的内部机制,对象的回收等,还介绍了在函数传参时候容易出错,但不容易发现的一些问题。
一、变量不是盒子
可能在学习数据结构之后会说,变量就是内存区分配的一小快空间,就像一个盒子存储着某个数据,然后需要数据时,直接拿出来就好了,但事实不是这样。
看下面例子
>>> a = [1, 2, 3]
>>> b = a
>>> a.append(4)
>>> b
[1, 2, 3, 4]
如果按照上面说的变量是存储 数据的盒子,那么显然在对a列表操作的时候,b盒子出现了同样的变化,所以这种说法是错误的。那么实际情况是怎样的呢?
可以理解为是a = [1, 2, 3]的时候,内存去分配出一块空间给列表[1, 2, 3]而变量a则像是贴在列表上的一个标签,然后a复制给b,b也成为了一个贴在列表上的标签。
二、标识,相等性,别名
1、is与==
那上面的a, b变量来说,两个变量指向的是同一个列表,是同一个内存空间,也就是说两个变量的地址是相同的
>>>id(a) , id(b)
123, 123 # 这里举个例子来说
>>> a == b
True
>>> a is b
True
is 运算符比较的是两个变量是不是引用的同一个对象,比较的是对象的标识,== 运算符比较的是两个对象的值,通常我们关注的是值,而不是标识,因此 Python 代码中 == 出现的频率比 is 高。
然而,在变量和单例值之间比较时,应该使用 is。目前,最常使用 is检查变量绑定的值是不是 None。下面是推荐的写法:
x is None
x is not None # 否定的写法
is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找并调用特殊方法,而是直接比较两个整数 ID。而 a == b 是语法糖,等同于a.eq(b)。继承自 object 的 eq 方法比较两个对象的 ID,结果与 is 一样。但是多数内置类型使用更有意义的方式覆盖了 __eq__方法,会考虑对象属性的值。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级深的结构时。
2、元祖的相对不可变性
元组属于容器序列,但是又具有不变性,这是相对的,上面说过,变量是对对象的引用,其实元组内部保存的也是对其他对象的引用,那么如果在元组内保存对其他可变对象的引用呢。也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
下面实例一开始,t1 和 t2 相等,但是修改 t1 中的一个可变元素后,二者不相等了
>>> t1 = (1, 2, [30, 40]) ➊
>>> t2 = (1, 2, [30, 40]) ➋
>>> t1 == t2 ➌
True
>>> id(t1[-1]) ➍
4302515784
>>> t1[-1].append(99) ➎
>>> t1
(1, 2, [30, 40, 99])
>>> id(t1[-1]) ➏
4302515784
>>> t1 == t2 ➐
False
❶ t1 不可变,但是 t1[-1] 可变。
❷ 构建元组 t2,它的元素与 t1 一样。
❸ 虽然 t1 和 t2 是不同的对象,但是二者相等——与预期相符。
❹ 查看 t1[-1] 列表的标识。
❺ 就地修改 t1[-1] 列表。
❻ t1[-1] 的标识没变,只是值变了。
❼ 现在,t1 和 t2 不相等。
所以说对于那些不变性的元组是可散列的,而那些可变性的元组则不行
三、 深浅拷贝
经过上面的介绍我们知道,其实在变量赋值的时候其实是在对内存空间追加引用,那么如果我想为现有的对象创建一个副本(这里的副本指的是创建一个内容相同的对象,而不是为一个已经创建号的对象追加引用),它的实现原理以及方法是怎样呢,以及会带来怎样的问题呢?
1、浅拷贝
下面使用最常用的数据结构之一:列表来说明问题,我们在复制列表时候使用的最常用的方式就是使用内置的类型构造方法
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1) ➊
>>> l2
[3, [55, 44], (7, 8, 9)]
>>> l2 == l1 ➋
True
>>> l2 is l1 ➌
False
❶ list(l1) 创建 l1 的副本。
❷ 副本与源列表相等。(我们可以清楚的看到这两个列表的内容是相同的)
❸ 但是二者指代不同的对象。对列表和其他可变序列来说,还能使用简洁的 l2 = l1[:] 语句创建副本。
这样看起来是没有问题的,我们实现了我们想要的功能:创建一个与原来内容相同的列表,但是真的是这样吗?来看下下面例子
l1 = [3, [66, 55, 44], (7, 8, 9)]
l2 = list(l1)
l1.append(100)
l1[1].remove(55)
print('l1:', l1)
print('l2:', l2)
l2[1] += [33, 22]
l2[2] += (10, 11)
print('l1:', l1)
print('l2:', l2)
你可能会以为结果是这样
l1: [3, [66, 44], (7, 8, 9), 100]
l2: [3, [66, 55, 44], (7, 8, 9)]
l1: [3, [66, 55, 44, 33, 22], (7, 8, 9)]
l2: [3, [66, 55, 44, 33, 22], (7, 8, 9,10,11)]
因为你觉得,我已经创建了一个副本,那么就和原来的列表没什么关系了,但是其实打印台会输出这样:
l1: [3, [66, 44], (7, 8, 9), 100]
l2: [3, [66, 44], (7, 8, 9)]
l1: [3, [66, 44, 33, 22], (7, 8, 9), 100]
l2: [3, [66, 44, 33, 22], (7, 8, 9, 10, 11)]
如果结果出乎你的意料,来看下面图吧
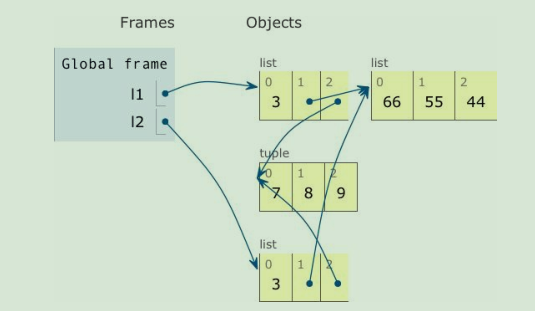
首先,可以很清楚的看到, 按照我们的最初设想,l1和l2 为两个不一样的列表,但是两个数组的第一个和第二个元素却又是对同一个列表和元组的引用,所以在对l1[1]或者l2[2]做更改的时候,会影响到另一个列表。这是最开始两个列表不涉及内部元素是对元组引用的时候的样子,但是也看到了,在下面的的确确是对元组进行进行+=操作了,但是结果也没有出错。
如果你心存疑问,来看下面图。
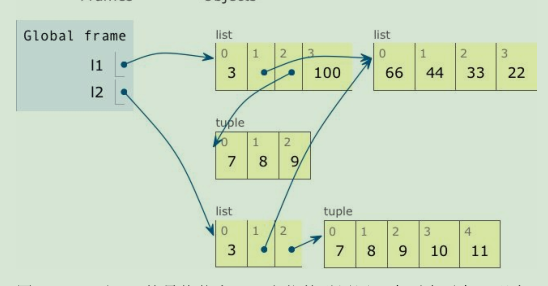
对元组来说,+= 运算符创建一个新元组,然后重新绑定给变量l2[2]。这等同于 l2[2] = l2[2] + (10, 11)。现在,l1 和 l2 中最后位置上的元组不是同一个对象。
注:如果你觉得这里l2[2] += (10, 11) 因为元组的不可变性会出错,那你就像错了,可以参考这篇博主的另一篇博文的小总结部分元组的不可变性
2、深拷贝
上面我们说过了,浅拷贝会带来了问题,副本会共享内部对象的引用,那么相对的我们该如何解决问题?深拷贝即副本不共享内部对象的引用)。copy 模块提供的 deepcopy 和 copy 函数能为任意对象做
深浅拷贝。
import copy
li = [1, 2, [3]]
#lis = list(li) #使用内置类型构造方法
#lis = copy.copy(li) # 使用copy模块内部方法浅拷贝
#lis = copy.deepcopy(li) # 使用copy模块内部方法深拷贝
print(“操作前”,lis)
li[2].append(4)
print(“操作后”,lis)
三种情况会输出
情况一、
操作前:[1, 2, [3]]
操作后:[1, 2, [3, 4]]
情况二和情况一的打印结果一致
情况三、
操作前:[1, 2, [3]]
操作后:[1, 2, [3]]
情况三说明通过深拷贝,lis与是完完全全独立于li的一个列表。
3、补充
在《流畅的Python》中作者关于深浅拷贝给出一个让博主印象深刻的例子,为了演示 copy() 和 deepcopy() 的用法,定义了一个简单的类,Bus。这个类表示运载乘客的校车,在途中乘客会上车或下车。
class Bus:
def __init__(self, passengers=None): # passenagers作为乘客列表
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
def pick(self, name): # 模拟上车
self.passengers.append(name)
def drop(self, name): # 模拟下车
self.passengers.remove(name)
通过调用Bus类的pick和drop方法实现上车与下车,在操纵台中进行操作,Bus类实例化一个bus对象,然后乘客为四个['Alice', 'Bill', 'Claire', 'David'],放在一个列表中,通过drop和append自定义类提供的接口操作之后,查看深浅拷贝的类bus2和bus3的变化
>>> import copy
>>> bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
>>> bus2 = copy.copy(bus1)
>>> bus3 = copy.deepcopy(bus1)
>>> id(bus1), id(bus2), id(bus3)
(4301498296, 4301499416, 4301499752) ➊
>>> bus1.drop('Bill')
>>> bus2.passengers
['Alice', 'Claire', 'David'] ➋
>>> id(bus1.passengers), id(bus2.passengers), id(bus3.passengers)
(4302658568, 4302658568, 4302657800) ➌
>>> bus3.passengers
['Alice', 'Bill', 'Claire', 'David'] ➍
❶ 使用 copy 和 deepcopy,创建 3 个不同的 Bus 实例。
❷ bus1 中的 'Bill' 下车后,bus2 中也没有他了。
❸ 审查 passengers 属性后发现,bus1 和 bus2 共享同一个列表对象,因为 bus2 是 bus1 的浅复制副本。
❹ bus3 是 bus1 的深复制副本,因此它的 passengers 属性指代另一个列表。
注:这里指的一提的是bus2和bus3是都是bus1的副本,而乘客列表则作为被共享的列表,而不是想上面那样复制的列表对象本身。
四、函数的参数作为引用的时候
既然变量引用对象的时候有这么多坑,python又支持共享传参,(共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名。)
函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识(即不能把一个对象替换成另一个对象)。下面实例中有个简单的函数,它在参数上调用 += 运算符。分别把数字、列表和元组传给那个函数,实际传入的实参会以不同的方式受到影响
>>> def f(a, b):
... a += b
... return a
...
>>> x = 1
>>> y = 2
>>> f(x, y)
3
>>> x, y ➊
(1, 2)
>>> a = [1, 2]
>>> b = [3, 4]
>>> f(a, b)
[1, 2, 3, 4]
>>> a, b ➋
([1, 2, 3, 4], [3, 4])
>>> t = (10, 20)
>>> u = (30, 40)
>>> f(t, u)
(10, 20, 30, 40)
>>> t, u ➌
((10, 20), (30, 40))
❶ 数字 x 没变。 对于整型没影响
❷ 列表 a 变了。 然而对于可变容器类型的列表,问题就出现了
❸ 元组 t 没变。 不可变容器类型元组,没有影响
1、不要使用可变类型作为参数的默认值
为了说明这一问题,拿流畅的python中的另个例子说明(其实是对上面bus类的改写),
class HauntedBus:
"""备受幽灵乘客折磨的校车"""
def __init__(self, passengers=[]): ➊
self.passengers = passengers ➋
def pick(self, name):
self.passengers.append(name) ➌
def drop(self, name):
self.passengers.remove(name)
这样看来是没有什么问题,初始化passagers,如果passerager为空,则使用一个空的列表。drop和pick依旧作为对passeager列表的remover和append内置方法的封装实现上车与下车。
来看操纵台的操作
>>> bus1 = HauntedBus(['Alice', 'Bill'])
>>> bus1.passengers
['Alice', 'Bill']
>>> bus1.pick('Charlie')
>>> bus1.drop('Alice')
>>> bus1.passengers ➊
['Bill', 'Charlie']
>>> bus2 = HauntedBus() ➋
>>> bus2.pick('Carrie')
>>> bus2.passengers
['Carrie']
>>> bus3 = HauntedBus() ➌
>>> bus3.passengers ➍
['Carrie']
>>> bus3.pick('Dave')
>>> bus2.passengers ➎
['Carrie', 'Dave']
>>> bus2.passengers is bus3.passengers ➏
True
>>> bus1.passengers ➐
['Bill', 'Charlie']
❶ 目前没什么问题,bus1 没有出现异常。
❷ 一开始,bus2 是空的,因此把默认的空列表赋值给self.passengers。
❸ bus3 一开始也是空的,因此还是赋值默认的列表。
❹ 但是默认列表不为空!
❺ 登上 bus3 的 Dave 出现在 bus2 中。
❻ 问题是,bus2.passengers 和 bus3.passengers 指代同一个列表。
❼ 但 bus1.passengers 是不同的列表。问题在于,没有指定初始乘客的 HauntedBus 实例会共享同一个乘客列表。并且这种问题很难发现。
实例化 HauntedBus 时,如果传入乘客,会按预期运作。但是不为 HauntedBus 指定乘客的话,奇怪的事就发生了,这是因为 self.passengers 变成了 passengers 参数默认值的别名。出现这个问题的根源是,默认值在定义函数时计算(通常在加载模块时),因此默认值变成了函数对象的属性。因此,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
可变默认值导致的这个问题说明了为什么通常使用 None 作为接收可变值的参数的默认值。
2、防御可变参数
但是如果 passengers 不是 None,正确的实现会把 passengers 的副本赋值给 self.passengers。那会出现什么问题呢?
class TwilightBus:
"""让乘客销声匿迹的校车"""
def __init__(self, passengers=None):
if passengers is None:
self.passengers = [] ➊
else:
self.passengers = passengers ➋
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name) ➌
❶ 这里谨慎处理,当 passengers 为 None 时,创建一个新的空列表。
❷ 然而,这个赋值语句把 self.passengers 变成 passengers 的别名,而后者是传给 init 方法的实参的别名。
❸ 在 self.passengers 上调用 .remove() 和 .append() 方法其实会修改传给构造方法的那个列表
>>> basketball_team = ['Sue', 'Tina', 'Maya', 'Diana', 'Pat'] ➊
>>> bus = TwilightBus(basketball_team) ➋
>>> bus.drop('Tina') ➌
>>> bus.drop('Pat')
>>> basketball_team ➍
['Sue', 'Maya', 'Diana']
❶ basketball_team 中有 5 个学生的名字。
❷ 使用这队学生实例化 TwilightBus。
❸ 一个学生从 bus 下车了,接着又有一个学生下车了。
❹ 下车的学生从篮球队中消失了
而真正的幽灵其实是我们自己的不正当操作
在bus类的init中,self.passengers = passengers,仍旧是对同一个对象传进来对象的引用,如果对passager操作,也会隐式的修改basketball_team这个列表。这就是学生消失的原因。
解决方案:那就是使用为basketball_team创建一个副本而不是添加一个引用。
重写intit方法如下
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
这样经过一波三折,校车就可以正常运行了!
五、del和垃圾回收
我们为了完成自己的功能,会在内存空间中创建多个对象,并为对象添加引用,每个对象又占有空间并且不会自己主动的销毁,释放内存。显然,一旦我们用不到某个对象的时候,它对于我们来说就是垃圾,只会白白的占用内存
python为了解决这一问题提供了三种垃圾回收机制即引用计数,标记清除和分代回收,而目前主要用引用计数和分代回收两种,请参考博主的另一篇博文python 的垃圾回收机制中有详细的介绍
六、一点补充
元组构建的问题
>>> t1 = (1, 2, 3)
>>> t2 = tuple(t1)
>>> t2 is t1 ➊
True
>>> t3 = t1[:]
>>> t3 is t1 ➋
True
上面例子说明使用另一个元组构建元组,得到的其实是同一个元组,对元组 t 来说,t[:] 不创建副本,而是返回同一个对象的引用。此外,tuple(t) 获得的也是同一个元组的引用。事实上,str、bytes 和 frozenset 实例也有这种行为。
字符串字面量可能会创建共享的对象
>>> t1 = (1, 2, 3)
>>> t3 = (1, 2, 3) # ➊
>>> t3 is t1 # ➋
False
>>> s1 = 'ABC'
>>> s2 = 'ABC' # ➌
>>> s2 is s1 # ➍
True
❶ 新建一个元组。
❷ t1 和 t3 相等,但不是同一个对象。
❸ 再新建一个字符串。
❹ 奇怪的事发生了,a 和 b 指代同一个字符串。
共享字符串字面量是一种优化措施,称为驻留(interning)。CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字。假如说这个数字是 1 ,也即是说内存全局之后一个 1 ,所以变量赋值为1,都是对同一个对象的引用。但这不是你使用“is”而不是用“==”的理由。比较字符串或整数是否相等时,应该使用 ==,而不是 is。
另外,None作为一个特殊的对象,全局也只有一个。