Data preparation
Audio data
自己创建数据集:
10个不同的说话人
每个人说10句话
每句话包含3个词
总共300个词,(数字0~9)
Task
kaldi-trunk/egs/digits创建digits_audio 文件夹,然后digits_audio,再创建train and test两个文件夹。
以说话人的ID命名文件夹,存放该说话人的数据,选出1个说话人的数据作为测试数据,其它9人作为训练数据。
Acoustic data
创建一些文本文件与音频数据关联。每个文件包含很多字符串,这些字符串需要被排序的。当遇到排序问题时,可以用checking (utils/validate_data_dir.sh) and fixing (utils/fix_data_dir.sh) ,保证有序,另外,将utils文件夹添加到工程目录里面。
Task
kaldi-trunk/egs/digits ,创建一个data文件夹,然后再创建test和train两个子文件夹再data里面。
a.) spk2gender
Pattern: <speakerID> <gender>
cristine f dad m josh m july f # and so on...
b.)wav.scp
Pattern: <uterranceID> <full_path_to_audio_file>
dad_4_4_2 /home/{user}/kaldi-trunk/egs/digits/digits_audio/train/dad/4_4_2.wav
july_1_2_5 /home/{user}/kaldi-trunk/egs/digits/digits_audio/train/july/1_2_5.wav
july_6_8_3 /home/{user}/kaldi-trunk/egs/digits/digits_audio/train/july/6_8_3.wav
# and so on...
c.) text
Pattern: <uterranceID> <text_transcription>
dad_4_4_2 four four two july_1_2_5 one two five july_6_8_3 six eight three # and so on...
d.)utt2spk
Pattern: <uterranceID> <speakerID>
dad_4_4_2 dad july_1_2_5 july july_6_8_3 july # and so on...
e.)corpus.txt
Pattern: <text_transcription>
one two five six eight three four four two # and so on...
每个文件对应1个发音,包含3个数字,因此100个发音,对应100行。
Language data
Task
kaldi-trunk/egs/digits/data/local,创建dict文件夹。
a.) lexicon.txt
'phone transcriptions' (taken from /egs/voxforge). 发音词典
Pattern: <word> <phone 1> <phone 2> ...
!SIL sil <UNK> spn eight ey t five f ay v four f ao r nine n ay n one hh w ah n one w ah n seven s eh v ah n six s ih k s three th r iy two t uw zero z ih r ow zero z iy r ow
b.)nonsilence_phones.txt
This file lists nonsilence phones that are present in your project.
Pattern: <phone>
ah ao ay eh ey f hh ih iy k n ow r s t th uw w v z
c.) silence_phones.txt
This file lists silence phones.
Pattern: <phone>
sil spn
d.) optional_silence.txt
This file lists optional silence phones.
Pattern: <phone>
sil
Project finalization
Tools attachment
Task
From kaldi-trunk/egs/wsj/s5 copy two folders (with the whole content) - utils and steps - and put them in your kaldi-trunk/egs/digits directory. You can also create links to these directories. You may find such links in, for example, kaldi-trunk/egs/voxforge/s5.
拷贝wsj/s5里面两文件夹utils and steps到本工程里
Scoring script
This script will help you to get decoding results.
SRILM installation
You also need to install language modelling toolkit that is used in my example - SRI Language Modeling Toolkit (SRILM).
安装语言模型工具包SRILM
Task
For detailed installation instructions go to kaldi-trunk/tools/install_srilm.sh (read all comments inside).
安装脚本kaldi-trunk/tools/install_srilm.sh
Configuration files
It is not necessary to create configuration files but it can be a good habit for future.
Task
In kaldi-trunk/egs/digits create a folder conf. Inside kaldi-trunk/egs/digits/conf create two files (for some configuration modifications in decoding and mfcc feature extraction processes - taken from /egs/voxforge):
修改解码配置和mfcc特征提取配置文件
a.) decode.config
first_beam=10.0 beam=13.0 lattice_beam=6.0
b.) mfcc.conf
--use-energy=false
Running scripts creation
两种训练方法:1.单音素训练 2.简单的3音素训练。从解码结果可以看到这两种方法的区别。
Task
In kaldi-trunk/egs/digits directory create 3 scripts:
a.) cmd.sh
本地机器跑

b.) path.sh
添加路径

c.) run.sh
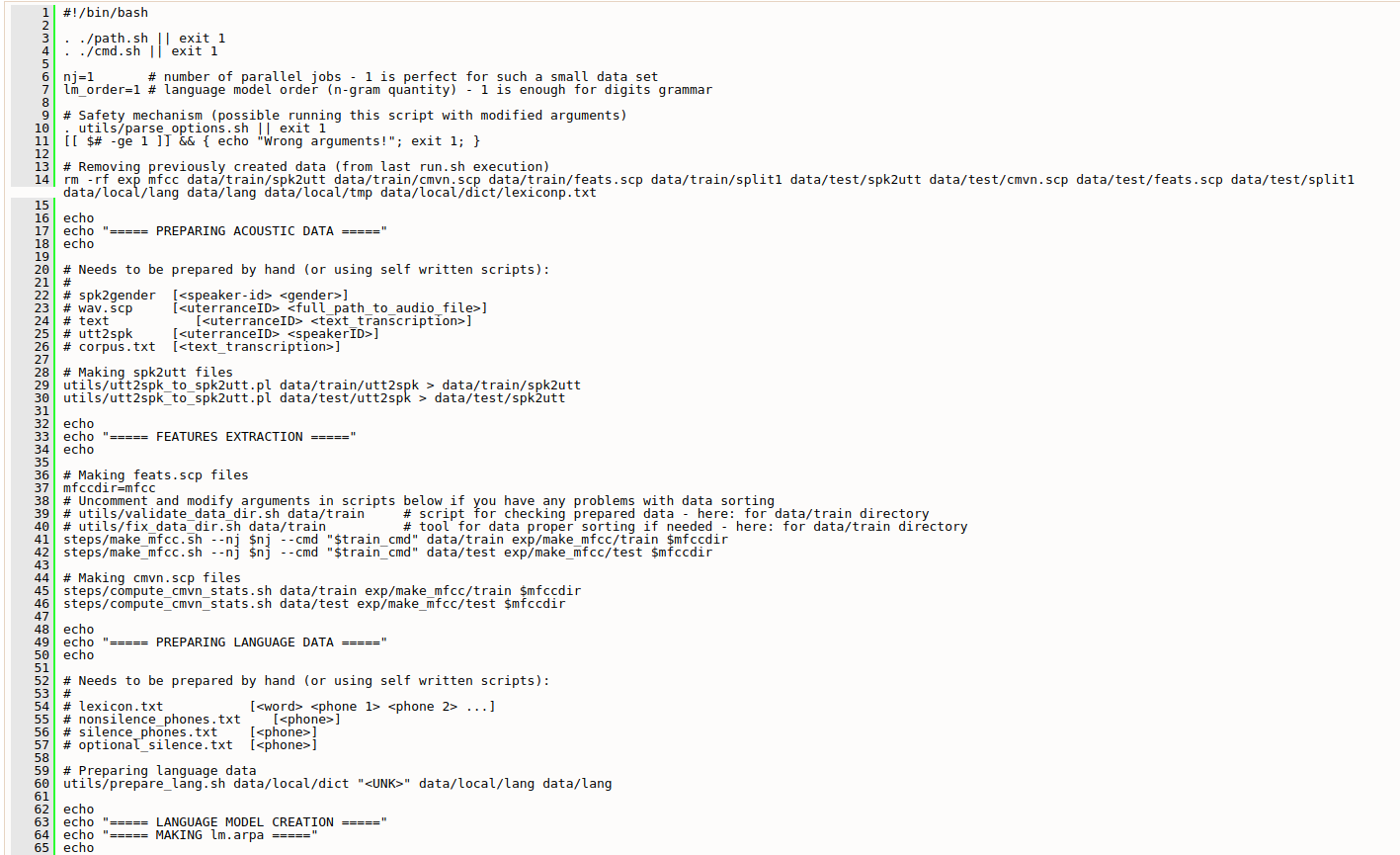
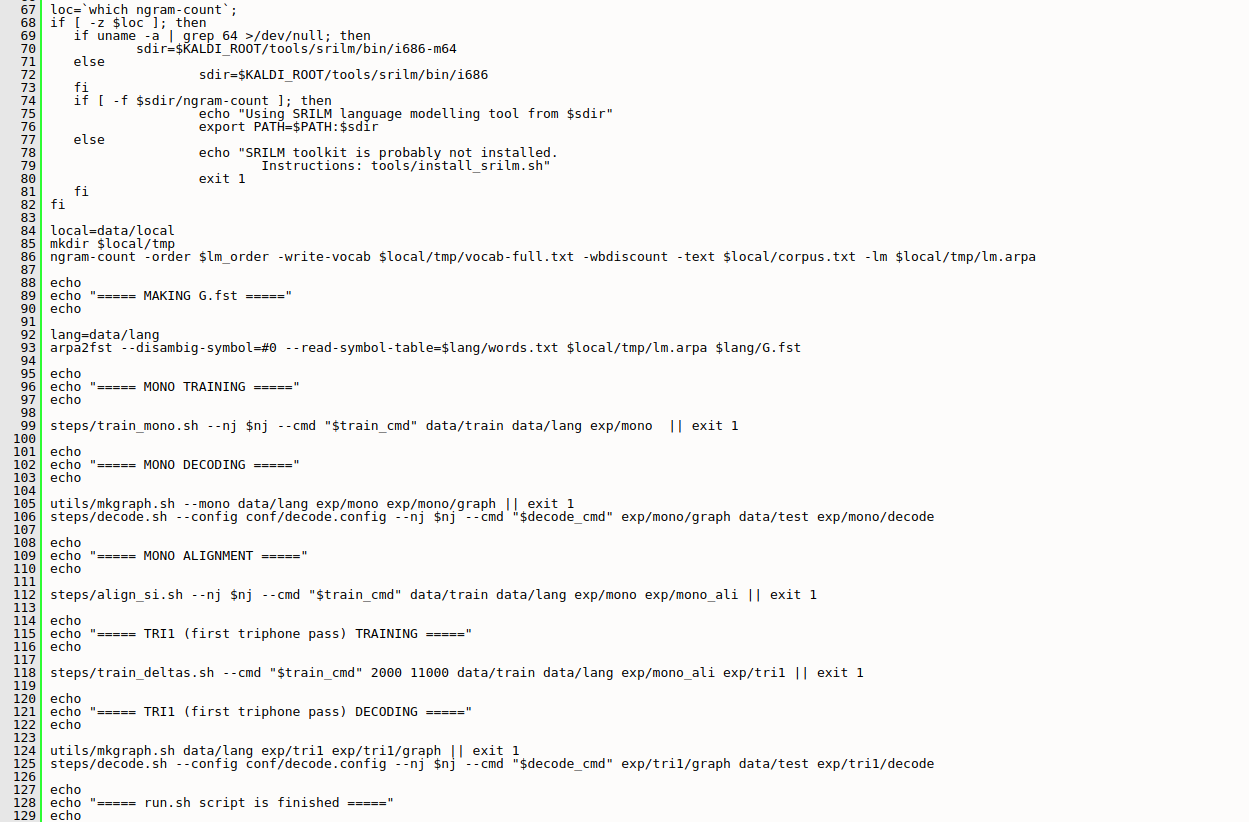
Getting results
Now all you have to do is to run run.sh script.
go to newly made kaldi-trunk/egs/digits/exp. You may notice there folders with mono and tri1 results as well - directories structure are the same.
Go to mono/decode directory. Here you may find result files (named in a wer_{number} way)
Summary
This is just an example. The point of this short tutorial is to show you how to create 'anything' in Kaldi and to get a better understanding of how to think while using this toolkit. Personally I started with looking for tutorials made by the Kaldi authors/developers. After succesful Kaldi installation I launched some example scripts (Yesno, Voxforge, LibriSpeech - they are relatively easy and have free acoustic/language data to download - I used these three as a base for my own scripts).
Make sure you follow http://kaldi-asr.org/- official project website. There are two very useful sections for beginners inside:
a.) Kaldi tutorial - almost 'step by step' tutorial on how to set up an ASR system; up to some point this can be done without RM dataset. It is good to read it,
b.) Data preparation - very detailed explaination of how to use your own data in Kaldi.
More useful links about Kaldi I found:
https://sites.google.com/site/dpovey/kaldi-lectures - Kaldi lectures created by the main author
http://www.superlectures.com/icassp2011/category.php?lang=en&id=131 - similar; video version
http://www.diplomovaprace.cz/133/thesis_oplatek.pdf - some master diploma thesis about speech recognition using Kaldi
This is all from my side. Good luck!