HBase的前提条件:
JDK
SSH
Hadoop
JDK:Hadoop和JDK运行的环境,他们的守护进程运行在JVM下。HBase支持JDK 1.6以上的版本。比如: jdk-8u161-linux-x64.rpm。
SSH:实现简单的服务器与主机的通信。在集群中,只有启动sshd后,才可以通过脚本远程操作其他的Hadoop和HBase进程。为了实现自动化操作,需要配置SSH免密码的的登录方式。
Hadoop:HDFS是HBase的底层存储文件系统。
1、HBase的安装与配置
进入HBase官网,下载HBase对应版本:
src和bin版本的区别:
src版本包含源码,主要给高级开发人员准备,可以去修改其中的源码改变或扩展功能。
bin版本主要是一般开发人员或使用者准备,只需要使用其固化功能即可。
HBase 的运行模式包括单机、伪分布式和分布式三种。
1.1 单机模式
单机模式搭建:使用本地文件系统,所有进程运行在一个 JVM 上,单机模式一 般只用于测试,HBase 需要结合 Hadoop 才能展现出其分布式存储的能力。
//单机模式搭建步骤: //1.解压 [root@localhost hbase]# tar zxvf hbase-2.2.3-bin.tar.gz //2.修改hbase/conf/hbase-env.sh,添加java环境变量 [root@localhost conf]# vi hbase-env.sh export JAVA_HOME=/usr/local/java/jdk1.8.0_241/ export HBASE_MANAGES_ZK=true //(使用hbase内置的zookeeper) //3.编辑hbase-site.xml,若是不配置默认是temp 每次启动会被清空 <configuration> <property> <name>hbase.rootdir</name> <value>file:///home/local/hbase-2.2.3-bin/rootDir</value> <description> hbase.rootdir是RegionServer的共享目录,用于持久化存储HBase数据,默认写入/tmp中。如果不修改此配置,在HBase重启时,数据会丢失。此处一般设置的是hdfs的文件目录, 如NameNode运行在namenode.Example.org主机的9090端口,则需要设置为hdfs://namenode.example.org:9090/hbase </description> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/local/hbase-2.2.3-bin/zookeeperDir</value> <description>此项用于设置存储ZooKeeper的元数据,如果不设置默认存在/tmp下,重启时数据会丢失。</description> </property> <property> <name>hbase.master.info.port</name> <value>60010</value> </property> </configuration> //4.添加hbase环境变量 [root@localhost bin]# vi /etc/profile //5.启动hbase [root@localhost bin]# ./hbase shell //6.jps查看,出现HMaster就是启动成功了
1.2 伪分布模式
修改配置文件,修改安装目录下的conf文件夹中的配置文件,主要包括2个文件:hbase-env.sh和hbase-site.xml.
- hbase-env.sh:配置hbase运行时变量,如java路径、regionserver相关参数等.
- hase-site.xml:hbase相关配置,如分布式模式、zookeeper的配置等.
伪分布式模式下,所有进程运行在一个 JVM 上,可以进行小集群的配置,用于测试。在生产环境下,需要在不同机器上的 JVM 中运行守护进程。
//1、下载安装hbase,官网:https://hbase.apache.org/downloads.html
tar xzvf hbase-2.2.4-bin.tar.gz /usr/local
cd /usr/local
mv hbase-2.2.4-bin.tar.gz hbase
ls
//2、修改配置文件,修改安装目录下的conf文件夹中的配置文件:hbase-env.sh和hbase-site.xml,同时分发到集群中的各个regionserver节点.
//比如:hbase-env.sh文件修改
export JAVA_HOME=/usr/java/j dkl.8.0_161
export HBASE_MANAGES_ZK=true
ps: ZooKeeper 也可以作为独立的集群来运行,即完全与 HBase 脱离关系,这时需要设置 HBASE_MANAGES_ZK 变量为 false。
1.3分布式模式
分布式模式是一种主从模式,基本由一个Master 节点和多个 Slave 节点组成,均使用 HDFS作为底层文件系统。
//1、分布式集群实例进行hbase-site.xml文件配置,hbase-site.xml配置文件如下:
<configuration>
<property>
<name> hbase.rootdir </name>
<value>hdfs://example0:9000/hbase</value>
<description> hbase.rootdir是RegionServer的共享目录,用于持久化存储HBase数据,默认写入/tmp中。如果不修改此配置,在HBase重启时,数据会丢失。此处一般设置的是hdfs的文件目录,如NameNode运行在namenode.Example.org主机的9090端口,则需要设置为hdfs://namenode.example.org:9090/hbase
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>此项用于配置HBase的部署模式,false表示单机或者伪分布式模式,true表不完全分布式模式。
</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>examplel,example2,example3</value>
<description>此项用于配置ZooKeeper集群所在的主机地址。examplel、 example2、example3是运行数据节点的主机地址,zookeeper服务的默认端口为2181。
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/var/zookeeper</value>
<description>此项用于设置存储ZooKeeper的元数据,如果不设置默认存在/tmp下,重启时数据会丢失。</description>
</property>
</configuration>
//2、修改 conf/regionservers 文件,罗列了所有region服务器的主机名.同时在配置完成后,需要同步这些文件到集群上的其他节点 .
2、hbase的启动和关闭
ps:在master服务器上已经配置了对集群中所有slave机器的无密码登录,使用start-hbase.sh脚本即可启动整个集群.
前提条件:
hdfs处于运行状态,jps命令查看namenode和datanode的服务是否正常启动
hbase启动命令:
//hbase的bin目录下,启动伪分布式集群或分布式集群的执行命令
bin/start-hbase.sh
jps //查看进程,如果是完全分布式模式,则在master节点运行有hmaster和hquorumpeer进程;在slave节点上有hregionserver和hquorumpeer进程.
hbase关闭命令:
//hbase的bin目录下,关闭hbase集群,执行命令
bin/stop-hbase.sh
3、Hbase shell及其常用命令
hbase shell是一个命令行工具。在linux上,输入命令: . /hbase shell
3.1 hbase shell
version:显示当前hbase的版本号
status:显示各主节点的状态,之后可以加入参数
whoami:显示当前用户名
退出shell模式:exit或quit.
[test@cs010 bin]$ ./hbase shell //version显示当前hbase版本号 hbase(main):001:0> version 1.4.12, r6ae4a77408ad35d6a7a4e5cebfd401fc4b72b5ec, Sun Nov 24 13:25:41 CST 2019 //status显示各主节点的状态 hbase(main):002:0> status 1 active master, 0 backup masters, 1 servers, 1 dead, 7.0000 average load //whoami显示当前用户名 hbase(main):003:0> whoami test(auth:SIMPLE) groups: test
3.2 表和列族操作
Hbase的表结构(schema)只有表名和列族两项内容.但列族的属性很多,在修改和建立表结构时,可以对列族的数量和属性进行设定.
HBase Shell操作表命令:
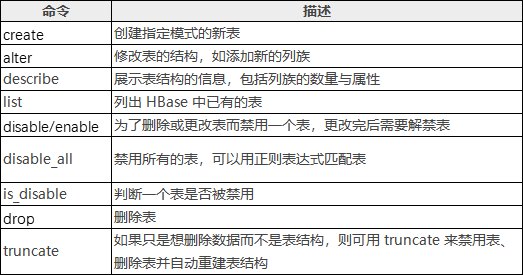
3.2.1 创建表
//创建表,必须指明两个参数:表名和列族的名字 1. create 'table1','basic' //建立表名为table1,含有一个列族basic 2. create 'table1','basic','advanced' //建立表名为table1,建立了2个列族basic,advanced. 3. create 'table2','basic',MAX_FILESIZE=>'134217728' //对表中所有列族设定,所有分区单次持久化的最大值为128MB 4. create 'TABLE1','basic' //hbase区分大小写,与第一个table1是2张不同的表 5. create 'table1',{NAME => 'basic',VERSION => 5,BLOCKCACHE => true} //大括号内是对列族basic进行描述,定义了VERSION=>5,表示对于同一个cell,保留最近的5个历史版本,BLOCKCACHE赋值为true,允许读取数据时进行缓存.其他未指定的参数,采用默认值 //大括号中的语法,NAME和VERSION为参数名,不需要用括号引用. //创建命名空间 create_namespace 'bigdata' //命名空间下创建表 create 'bigdata:student','info' //命名空间下删除表,如果有表,需要先删除表
drop_namespace 'bigdata'
3.2.2 查看表名列表
//list命令查看当前所有表名 list //list命令查看当前命名空间 list_space //exists 命令查看此表是否存在 exists 'table_test1' eg: hbase(main):010:0> list TABLE table_test1 1 row(s) in 0.0060 seconds hbase(main):043:0> list_namespace NAMESPACE default 1 row(s) in 0.0190 seconds hbase(main):011:0> exists 'table_test1' Table table_test1 does exist 0 row(s) in 0.0070 seconds
3.2.3 描述表结构
//描述表结构 describe命令查看指定表的列族信息,包括有多少个列族、每个列族的参数信息 describe 'table_test1'
//描述命名空间下的表结构
describe 'bigdata:table_test1'
eg: hbase(main):013:0> describe 'table_test1' Table table_test1 is ENABLED table_test1 COLUMN FAMILIES DESCRIPTION {NAME => 'test001', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>'65536', REPLICATION_SCOPE => '0'} {NAME => 'test002', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>'65536', REPLICATION_SCOPE => '0'} 2 row(s) in 0.0250 seconds
3.2.4 修改表结构
//修改表结构,alter命令,比如增加列族或修改列族参数. //eg:表table_test1中新增列族test002 1. alter 'table_test1','test001','test002' //新增列族test002 2. alter 'table_test1','test002' //新增列族test002 3. alter 'table_test1','test001',{NAME=> 'test002',IN_MEMORY =>true} //新增列族test002 //修改列族名称,该列族下已存有数据,需要对数据进行修改 4. alter 'table_test1',{NAME=> 'test001',IN_MEMORY =>true} //删除一个列族,以及其中的数据(前提是至少要有一个列族) 5. alter 'table_test1','delete'=>'test001' 6. alter 'table_test1',{NAME=> 'test002',METHOD=>'delete'} eg: [haishu@cs010 bin]$ . /hbash shell hbase(main):001:0> list TABLE table_test1 1 row(s) in 0.1710 seconds hbase(main):002:0> alter 'table_test1','delete'=>'test001' Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 1.9480 seconds hbase(main):003:0> alter 'table_test1',{NAME=>'test002',METHOD=>'delete'} Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 1.8710 seconds
3.2.5 删除表
//先禁用表,再删除表 disable 'table1' //禁用表table1 is_disable 'table1'//查看是否禁用成功 drop 'table1'//删除表 //顺序完成禁用、删除表、删除所有数据、重新建立空表,即清空表中所有的数据 truncate 'table1'
3.3 数据更新
HBase Shell 增删改查命令:

3.3.1 数据插入
//数据插入,参数依次显示为:表名、行键名称、列族:列的名称、单元格的值、时间戳或数据版本号,数值越大表示时间或版本越新,如果省略,默认显示当前时间戳 put 'table_test','001','basic:test001','micheal jordan',1 put 'table_test','002','basic:test002','kobe'
3.3.2 数据更新
//数据更新,put语句行键、列族已存在,但不考虑时间戳。建表时设定VERSIONS=>n,则用户可以查询到同一个cell,最新的n个数据版本 put 'table_test','001','basic:test001','air jordan',2
3.3.3 数据删除
HBase 的删除操作并不会立即将数据从磁盘上删除,删除操作主要是对要被删除的数据打上标记。
当执行删除操作时,HBase 新插入一条相同的 KeyValue 数据,但是使 keytype=Delete,这便意味着数据被删除了,直到发生 Major compaction 操作时,数据才会被真正的从磁盘上删除,删除标记也会从StoreFile删除。
//数据删除,用delete,必须指明表名和列族名称 delete 'table_test','001','basic' delete 'table_test','002','basic:test002' delete 'table_test','002','basic:test002',2 //如果指明了版本,默认删除的是所有版本<=2的数据 //delete命令的最小粒度是cell,且不能跨列族删除。 //删除表中所有列族在某个行键上的数据,即删除一个逻辑行,则需要使用deleteall命令 deleteall 'table_test','001' deleteall 'table_test','002',1 //hbase并不能做实时删除数据,当hbase删除数据时,可以看作为这条数据put了新的版本,有一个删除标记(tombstone)
3.3.4 计数器
//incr命令可以将cell的数值在原值上加入指定数值 incr 'table_test','001','basic:scores',10 //get_counter命令可以查看计数器的当前值 get_counter 'table_test','001','basic:scores'
3.3 数据查询
hbase有2种基本的数据查询方法:
1.get:按行键获取一条数据
2.scan:扫描一个表,可以指定行键范围或使用过滤器限制范围。
3.count:采用count指令计算表的逻辑行数
//get命令的必选参数为表名和行键名 get 'table_test','001' //可选项,指明列族名称、时间戳的范围、数据版本数、使用过滤器 get 'table_test','001',{COLUMN=>'basic'} get 'table_test','001',{COLUMN=>'basic',TIMERANGE=>[1,21]} get 'table_test','001',{COLUMN=>'basic',VERSIONS=>3} get 'table_test','001',{COLUMN=>'basic',TIMERANG=>[1,2],VERSION=>3} get 'table_test','001',{FILTER=>"ValueFilter(=,'binary:Michael Jordan 1')"}
//scan数据扫描,不指定行键,hbase只能通过全表扫描的方式查询数据 scan 'table_test' //指定列族名称 scan 'table_test' ,{COLUMN =>'basic'} //指定列族和列名 scan 'table_test' ,{COLUMN =>'basic:name'} //指定输出行数 scan 'table_test' ,{LIMIT => 1} //指定行键的范围,中间用逗号隔开 scan 'table_test' ,{LIMIT =>'001',LIMIT => '003'} //指定时间戳或时间范围 scan 'table_test' ,{TIMESTAMP => 1} scan 'table_test' ,{TIMESTAMP => [1,3]} //使用过滤器 scan 'table_test' ,FILTER=>"RowFilter(=,substring:0')" //指定对同一个键值返回的最多历史版本数量 scan 'table_test' ,{version=> 1}
//采用count指令可以计算表的逻辑行数 count 'table_test'
3.3 过滤查询
无论是在get方法还是scan方法,均可以使用过滤器(filter)来显示扫描或输出的范围。
//过滤器进行过滤查询,配合比较运算符或比较器共同使用:>、<、=、>=、<=、!= show_filters
比较器:
- BinaryComparator:完整字节比较器,如:binary:001,表示用字典顺序依次比较数据的所有字节。
- BinaryPrefixComparator:前缀字节比较器,如:binaryprefix:001,表示用字典顺序依次比较数据的前3个字节。
- RegexStringComparator:正则表达式比较器,如regexstring:a*c,表示字符串'a'开头,'c'结构的所有字符串。只可以用=或!=两种运算符。
- SubstringComparator:子字符串比较器,如substring:00.只可以用=或!=两种运算符。
- BitComparator:比特位比较器。只可以用=或!=两种运算符。
- NullComparator:空值比较器。
//比较器语法使用,用FILTER=> "过滤器(比较方式)"的方式指明所使用的过滤方法 //在语法格式上,过滤的方法用双引号引用,而比较方式用小括号引用 scan 'table_test',FILTER=>"RowFilter(=,'substring:0')" scan 'table_test',{FILTER=>"RowFilter(=,'substring:0')"}
过滤器的用途:
- 行键过滤器
- 列族和列过滤器
- 值过滤器
- 其他过滤器
行键过滤器:
//行键过滤器,RowFilter:可以配合比较器及运算符,实现行键字符串的比较和过滤。 //需求:显示行键前缀为0开头的键值对,进行子串过滤只能用=或!=两种方式,不支持采用大于或小于 scan 'table_test',FILTER=>"RowFilter(=,'Substring:0')" scan 'table_test',FILTER=>"RowFilter(>=,'BinaryPrefix:0')"
//行键前缀比较器,PrefixFilter:比较行键前缀(等值比较)的命令 scan 'table_test',FILTER=>"PrefixFilter('0')"
//KeyOnlyFilter:只对cell的键进行过滤和显示,不显示值,扫描效率比RowFilter高 scan 'table_test',{FILTER=>"KeyOnlyFilter()"} //FirstKeyFilter:只扫描相同键的第一个cell,其键值对都会显示出来,如果有重复的行键则跳过。可以用来实现对行键(逻辑行)的计数,和其他计数方式相比。 scan 'table_test',{FILTER=>"FirstKeyFilter()"} //InclusiveStopFilter:使用STARTROW和ENDROW进行设定范围的scan时,结果会包含STARTROW行,但不包括ENDROW,使用该过滤器替代ENDROW条件 scan 'table_test',{STARTROW=>'001',ENDROW=>'002'} scan 'table_test',{STARTROW=>'001',FILTER=>"InclusiveStopFilter ('binary:002')",ENDROW=>'002'}
列族和列过滤器:
//列族和列过滤器 //列族过滤器:FamilyFilter scan 'table_test',FILTER=>"FamilyFilter(=,'substring:test001')" //列名(列标识符)过滤器:QualifierFilter scan 'table_test',FILTER=>"QualifierFilter(=,'substring:test001')" //列名前缀过滤器:ColumnPrefixFilter scan 'table_test',FILTER=>"ColumnPrefixFilter('f')" //指定多个前缀的ColumnPrefixFilter:MultipleColumnPrefixFilter scan 'table_test',FILTER=>"MultipleColumnPrefixFilter('f','l')" //时间戳过滤器:TimestampsFilter scan 'table_test',{FILTER=>"TimestampsFilter(1,2)"} //列名范围过滤器:ColumnRangeFilter scan 'table_test',{FILTER=>"ColumnRangeFilter('f',false,'lastname',true)"} //参考列过滤器:DependentColumnFilter,设定一个参考列(即列名),如果某个逻辑行包含该列,则返回该行中和参考列时间戳相同的所有键值对 //过滤器参数中,第一项是需要过滤数据的列族名,第二项是参考列名,第三项是false说明扫描包含"basic:firstname",如果是true则说明在basic列族的其他列中进行扫描。 scan 'table_test',{FILTER=>"DependentColumnFilter('basic','firstname',false)"}
值过滤器:
//ValueFilter:值过滤器,get或者scan方法找到符合值条件的键值对,变量=值:Michael Jordan
get 'table_test','001',{FILTER=>"ValueFilter(=,'binary:Michael Jordan')"}
scan 'table_test',{FILTER=>"ValueFilter(=,'binary:Michael Jordan')"}
//SingleColumnValueFilter:在指定的列族和列中进行比较的值过滤器,使用该过滤器时尽量在前面加上一个独立的列名限定
scan 'table_test',{ COLUMN => 'basic:palyername' , FILTER => "SingleColumnValueExcludeFilter('basic','playername',=,'binary:Micheal Jordan 3')"}
//SingleColumnValueExcludeFilter:和SingleColumnValueFilter类似,但功能正好相反,即排除匹配成功的值
scan 'table_test', FILTER => "SingleColumnValueExcludeFilter( 'basic' , 'playername' ,=,'binary:Micheal Jordan 3')"
SingleColumnValueFilter和SingleColumnValueExcludeFilter区别: Value = "Micheal Jordan "的键值对,或者返回除此之外的其他所有键值对。
//其他过滤器
1. ColumnCountGetFilter:限制每个逻辑行最多返回多少个键值对(cell),一般用get,不用scan.
2. PageFilter:对显示结果按行进行分页显示
3. ColumnPaginationFilter:对显示结果按列进行分页显示
4. 自定义过滤器:hbase允许采用Java编程的方式开发新的过滤器
eg: scan 'table_test', FILTER => "ColumnPrefixFilter( 'first' ) AND ValueFilter(=, 'substring:kobe')"
eg:
hbase(main):012:0> get 'Test','002',{FILTER=>"ValueFilter(=,'binary:test004')"}
COLUMN CELL
zhangsan:wendy001 timestamp=1587208488702, value=test004
zhangsan:wendy002 timestamp=1587208582262, value=test004
1 row(s) in 0.0100 seconds
hbase(main):013:0> scan 'Test',{FILTER=>"ValueFilter(=,'binary:test004')"}
ROW COLUMN+CELL
001 column=zhangsan:wendy001, timestamp=1587208452109, value=test004
002 column=zhangsan:wendy001, timestamp=1587208488702, value=test004
002 column=zhangsan:wendy002, timestamp=1587208582262, value=test004
2 row(s) in 0.0100 seconds
hbase(main):018:0> scan 'Test',{ COLUMN => 'zhangsan:wendy002' , FILTER => "SingleColumnValueExcludeFilter('zhangsan','wendy002',=,'binary:test004')"}
ROW COLUMN+CELL
0 row(s) in 0.0040 seconds
hbase(main):019:0> scan 'Test',{COLUMN=>'zhangsan:wendy002',FILTER=>"SingleColumnValueFilter('zhangsan','wendy002',=,'binary:test004')"}
ROW COLUMN+CELL
002 column=zhangsan:wendy002, timestamp=1587208582262, value=test004
1 row(s) in 0.0060 seconds
3.4 快照操作
快照:一种不复制数据就能建立表副本的方法,可以用于数据恢复,构建每日、每周或每月的数据报告,并在测试中使用等。
快照前提:Hbase的配置文件hbase-site.xml中配置hbase.snpashot.enabled属性为true。一般情况下,HBase的默认选项即为true。
//建立表的快照p1 snapshot 'test001','p1' //显示快照列表 List_snapshots //删除快照 delete_snapshot 'p1' PS:注意删除快照后,原表的数据仍然存在。删除原表,快照的数据也仍然存在。 //通过快照生成新表play_1,注意用此种方法生成新表,不会发生数据复制,只会进行元数据操作 clone_snapshot 'p1','play_1' //快照恢复原表格,将抛弃快照之后的所有变化 restore_snapshot 'p1' //利用快照实现表改名,方法:制作一个快照,再将快照生成为新表,最后将不需要的旧表和快照删除 snapshot 'player','p1' clone_snapshot 'p1','play_1' disable 'player' drop 'player' delete_snapshot 'p1'
3.5 批量导入导出
场景:put方法用于逐条采集数据,但如果需要将大量数据一次性写入HBase,则需要进行批量操作。此外,如果需要将数据备份到HDFS等位置,也需要进行批量操作,基于hadoopde的MapReduce方法实现,而数据的导入源头和备份目的,通常是在HDFS之上。
3.5.1 批量导入数据
批量导入数据,有两种方式:
1、第一种是并行化的数据插入,利用MapReduce等方式将数据发给多个RegionServer。
2、第二种是根据表信息直接将原始数据转换成HFile,并将数据复制到HDFS的相应位置,再将文件中的数据纳入管理。
方法1,利用ImportTsv类方法:将存储在HDFS上的文本文件导入到HBase的指定表,TXT文件当中应当有明确的列分隔符,比如利用' '(TAB键)分割的TSV格式,或逗号分割的CSV格式。
原理:执行机制是扫描整个文件,逐条将数据写入。使用MapReduce方法在多个节点上启动多个进程,同时读取多个HDFS上的文件分块。数据根据所属分区不同,被发向不同的Regionserver,利用分布式并行读写的方式,加快数据导入的速度。
//在linux的命令行通过HBase指令调用ImportTsv类 //player为表名,hdfs://namenode:8020/input/为导入文件所在的目录,这里不需要指定文件名,导入时会遍历目录中的所有文件。
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns= HBASE_ROW_KEY,basic:playername,advance:scores -Dimporttsv.skip.bad.lines =true player hdfs://namenode:8020/input/
//-Dimporttsv.columns=HBASE_ROW_KEY,参数依次为:第一个关键字HBASE_ROW_KEY是指定文本文件中的行键,第二个是写入列族basic下名为playername的列,第三个是写入advance列族下的scores列,这一参数一般为必选项。
//-Dimporttsv.skip.bad.lines=true表示略过无效的行,如果设置为false,则遇到无效行会导入报告失败
//可选参数
//-Dimporttsv.separator=',',用逗号作为分隔符,也可以指定为其他形式的分隔符,例如'�',默认情况下分隔符为' '。
//-Dimporttsv.timestamp =1298529542218,导入时使用指定的时间戳,如果不指定则采用当前时间。
方法二,利用bulk-load方法:直接将原始数据转换成HFile,并将数据复制到HDFS的相应位置,再将文件中的数据纳入管理,分为2个步骤。
//前提:表结构已经建立好,并且在命令中指定了表名,因为要根据表结构和分区状况准备文件 //第一步:利用ImportTsv生成文件 //第二步:复制 //第一步:利用ImportTsv生成文件 hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns= HBASE_ROW_KEY,basic:playername,advance:scores -Dimporttsv.skip.bad.lines =true -Dimporttsv.bulk.output=hdfs://namenode:8020/bulkload/ player hdfs://namenode:8020/input/ //-Dimporttsv.bulk.output 参数,设定了HDFS路径,准备好HFile文件的存放地址:hdfs://namenode:8020/bulkload/,由于MapReduce的特性,该路径不能提前存在
//第二步:复制,利用MapReduce实现,参数为HFile文件所在路径和表名。 hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles hdfs://namenode:8020/bulkload player
方法三,从关系型数据库中导入数据到HBase:Hadoop系列组件中,有名为Sqoop的组件可以实现Hadoop、Hive、HBase等大数据工具与关系型数据库(例如MySQL、Oracle)之间的数据导入、导出。
Sqoop分为1和2两个版本,Sqoop1使用较为简单,Sqoo2则继承了更多功能,架构也更复杂。
//以sqoop1为例,其安装过程基本为解压。 //访问MySQL等数据库,则需要自行下载数据库连接组件(mysql-connector-java-x.jar),并复制到其lib目录中。 sqoop import --connect jdbc:mysql://node1:3306/database1 --table table1 --hbase-table player --column-family f1 --hbase-row-key playername --hbase-create-table --username 'root' -password '123456' //从mysql中导入数据(import),之后指明了作为数据源的mysql的访问地址(node1)、端口(3306)、数据库名(database1)、表名(table1)。 //数据导入名为player的HBase表,并存入名为f1的列族,列名则和MySQL中保持一致,行键为MySQL表中名为playername的列。 //--hbase-create-table :HBase中建立这个表,最后指明了访问mysql的用户名和密码。
3.5.2 备份和恢复
HBase支持将表或快照复制到HDFS,支持将数据复制到其他HBase集群,以实现数据备份和恢复功能。有四种方式:
//Export、Import、ExportSnapshot、CopyTable //Export:将HBase的数据导出到HDFS。目的;备份,文件并不能直接以文本方式查看。 //参数中<tablename>为表名,<outputdir>为HDFS路径。 hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> //Import:导出的数据可以恢复到HBase。 hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <outputdir> //ExportSnapshot hbase org.apache.hadoop.hbase.mapreduce.ExportSnapshot -snapshot <snapshot name> -copy-to <outputdir> //snapshot 快照名 ;outputdir为HDFS路径,导出的快照文件可以利用Import方法恢复到表中。 //CopyTable:可以将一个表的内容复制到新表中,新表和原表可以在同一个集群内,也可以在不同的集群上。复制过程利用MapReduce进行。 //前提:新表已经建立起来 hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=<NEW_TABLE_NAME> -peer.adr=<zookeeper_peer:2181:/hbase> <TABLE_NAME> //--new.name=<NEW_TABLE_NAME>参数描述新表的名字,如果不指定则默认和原表名相同。 //-peer.adr=<zookeeper_peer:2181:/hbase>参数指向目标集群Zookeeper服务中的hbase数据入口(包括meta表的地址信息等) //CopyTable帮助 hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help
5、phoenix工具
phoenix核心功能:HBase提供SQL语言支持和JDBC接口。基于协处理器等功能,仿照关系型数据库的常见功能,对HBase进行了功能扩展:
- 事务机制:目的是通过一个处在孵化中(incubator)的开源软件Tephra,实现分布式全局事务机制
- 二级索引:利用写核处理器等级制实现二级索引,并通过SQL语句操作索引
- 用户自定义函数(UDFs),在使用SQL语句时调用用户自行开发的函数
- 游标(cursor):指示当前行,方便基于当前行开展下一步查询
- 批量导入(Bulkdataloading):可以采用单线程和多线程两种方式导入CSV或JSON格式的数据
- 视图(views):关系型数据库中的视图概念
- 抽样:利用SQL语句
- 定义存储格式(storage formats):该功能类似于在OpenTSDB中使用偏移量和编码等方式降低行键和列族的存储空间占用
- 多租户(multi-tenancy):即为不同用户提供不同的视图。
4.1 phoenix 配置
squirrel-sql客户端下载:http://squirrel-sql.sourceforge.net/#installation
phoenix下载:http://mirror.bit.edu.cn/apache/phoenix/
配置方法:
1.下载相应的phoenix软件包,将其中的Jar包复制到regionserver下、HBase安装目录下的lib文件夹,并重启HBase
2.SQL客户端(如squirrel-sql)配置连接到phoenix的JDBCdriver.在命令行执行命令:java -jar squirrel-sql-<version>-install.jar
PS:On Windows, execute the file squirrel-sql.bat to run the application. On Unix, the file is squirrel-sql.sh.