源表:
create table bak(name string,id string,phone string,card_num bigint,email string,addr string) partitioned by (time string)row format delimited fields terminated by ',';
load data local inpath '/home/xfvm/bak' into table bak partition(time='2017-10-17');
1、创建索引(分区字段自动创建索引)
create index bak_index on table bak(id,name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndex' deferred rebuild in table bak_index_table;

2、显示索引
show formatted index on bak;

3、重建索引(当表中添加新字段且新字段需要创建索引时)
(1)源表添加字段
alter table bak add columns (country string,city string);

(2)索引表重新建
create index bak_index on table bak(id,name,country) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table bak_index_table;
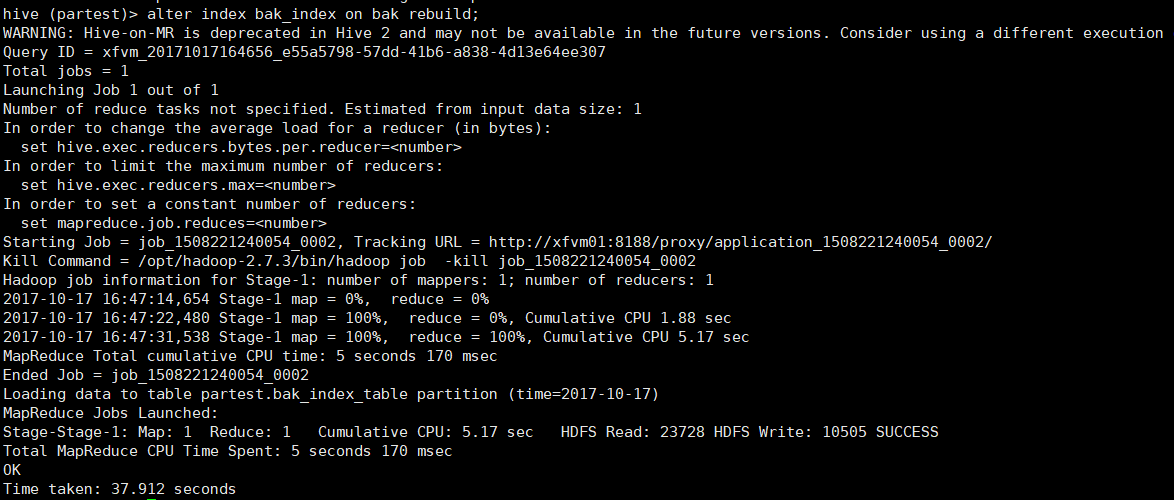
alter index bak_index on bak rebuild;
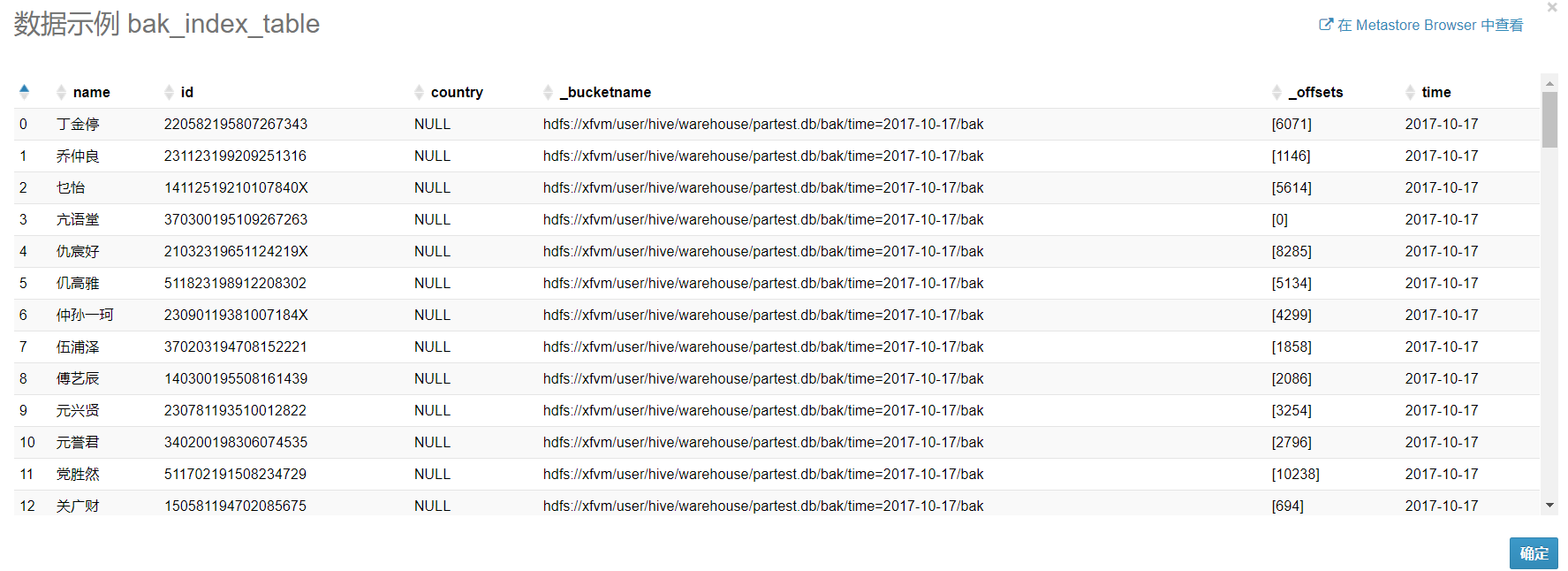
查看索引表的数据
4、删除索引
drop index if exists bak_index on bak;