深度学习学习记录一
1.学习路线
我这里的规划是,李宏毅的深度学习课程,然后林轩田的机器学习基石,机器学习技法,最后我们苏老师的计算机视觉。后面就读论文,复现程序了。
2.Kaggle 介绍
竞赛,作业平台
3.定义
让机器自己学习来生产复杂的程序。如语音识别,图像分类等。
Regression: 输出一个数值的程序
Classification : 从设定好的信息中,选择一个输出,例子alaf go,从19*19的棋盘中选择一个最好的位置。
Structured Learning:让机器学会创作。(黑暗大陆)
4.Training过程
1.Function with unknown Parameters
y = b + wx
b: bias
w: weight
2.Define Loss from Training Data
L(b,W)
3.Optimization
Gradient Descent :have local minima 局部最优解
η:learning rate
w = η * dL/dw
5.讲课的实例
5.1.linear models
李宏毅老师,这里使用自己的2017-2020的youtube数据来预测第二天的观看人数。用一个w来预测,等于用前一天预测,效果不好。发现曲线是七天一个循环,所以使用7个w预测。然后效果优化到极限,还是有误差。所以线性函数(linear models)不够用来预测。piecewise linear curves(分段线性函数),曲线也可以用piecewise linear curves来逼近。
5.2.Sigmoid Function
y = c * (1 / 1 + e ^ -(b + wx1))
w:改变斜率
b:左右移动
c:改变高度
- 神经网络原理
y = b + ∑c * (1 / 1 + e ^ -(b + wx1)) ci,bi,wi (通过多个sigmoid函数来相加生成piecewise linear curves )
y = b + ∑c * (1 / 1 + e ^ -(b + ∑wx)) ci,bi,wij,xj (通过多个sigmoid函数来相加生成piecewise linear curves ) 这个式子可以推出神经网络 - 根据式子推到神经网络
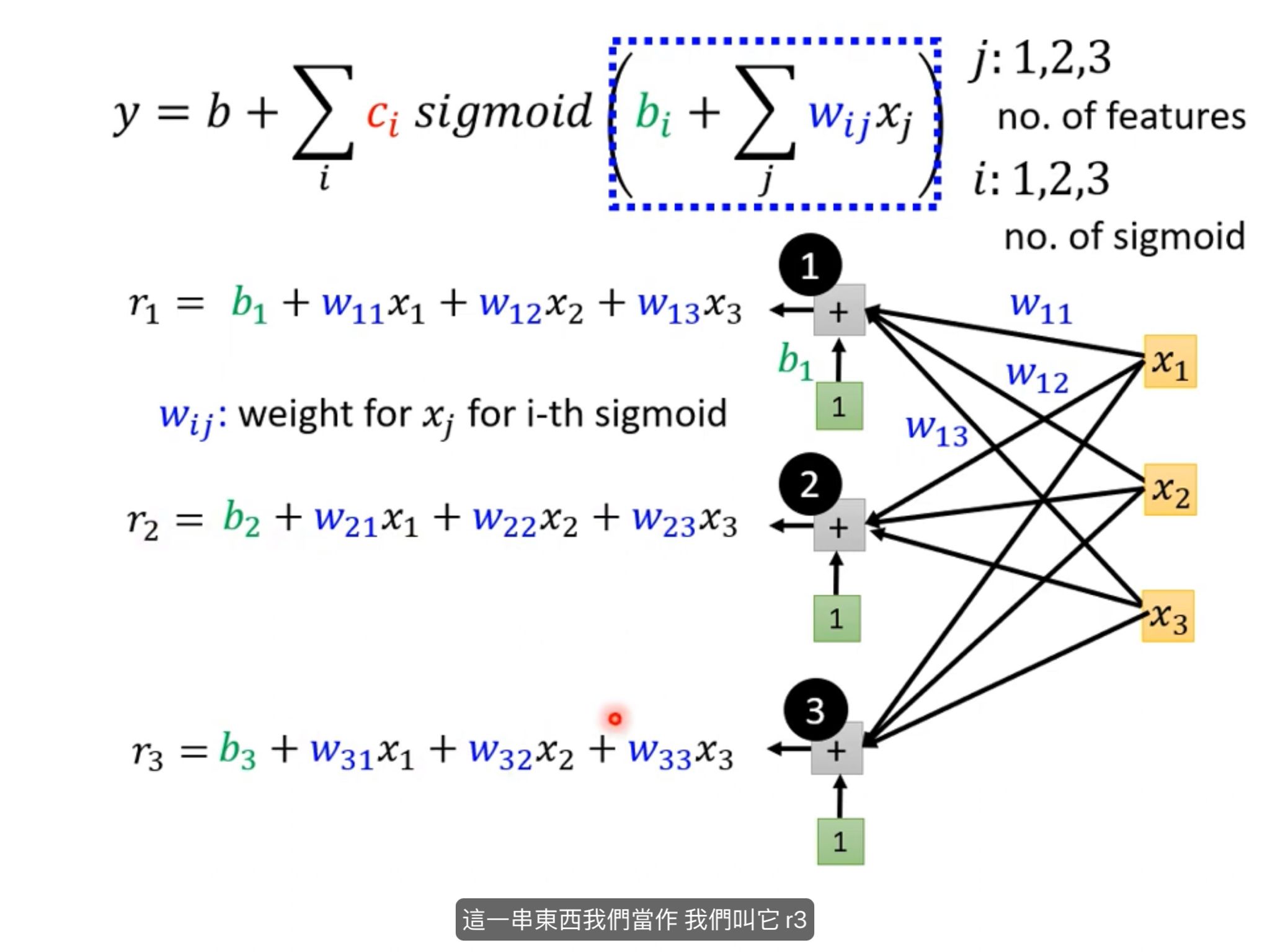
- 将式子矩阵化1

- 将式子矩阵化2

5.2.1Training过程 矩阵版
1.Function with unknown Parameters
上图的矩阵式子
2.Define Loss from Training Data
L(θ) θ 是所有的 Unknown parameters
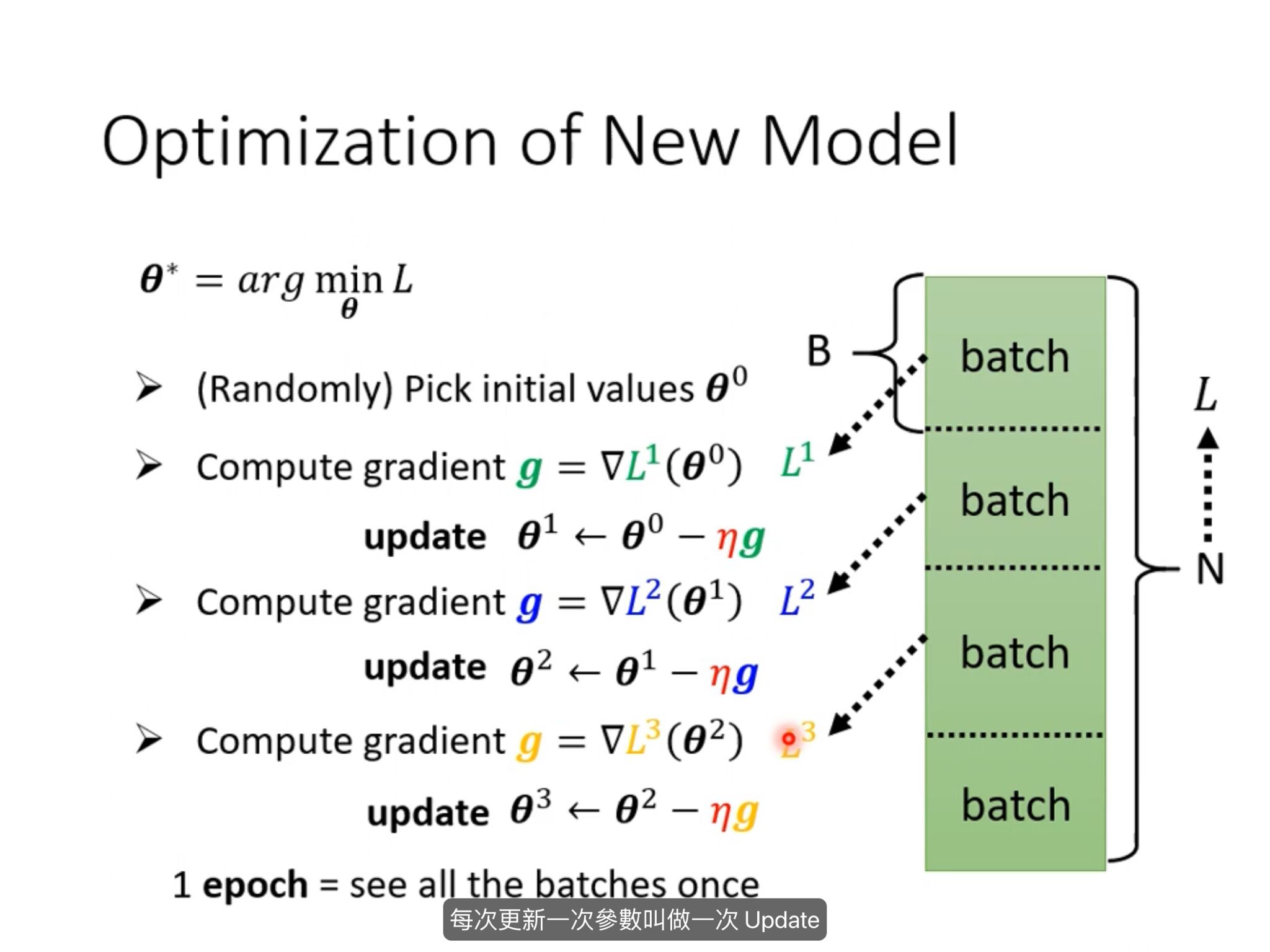
3.Optimization
.png)
g :gradient : 梯度
batch 把资料分为多个batch,用小batch 来更新参数。一个epoch是把所有的batch过一遍的结果。
5.3RelU
这个是hard sigmoid。
y = b + ∑c * max(0,b + ∑wx) ci,bi,wij,xj
5.4多层网络
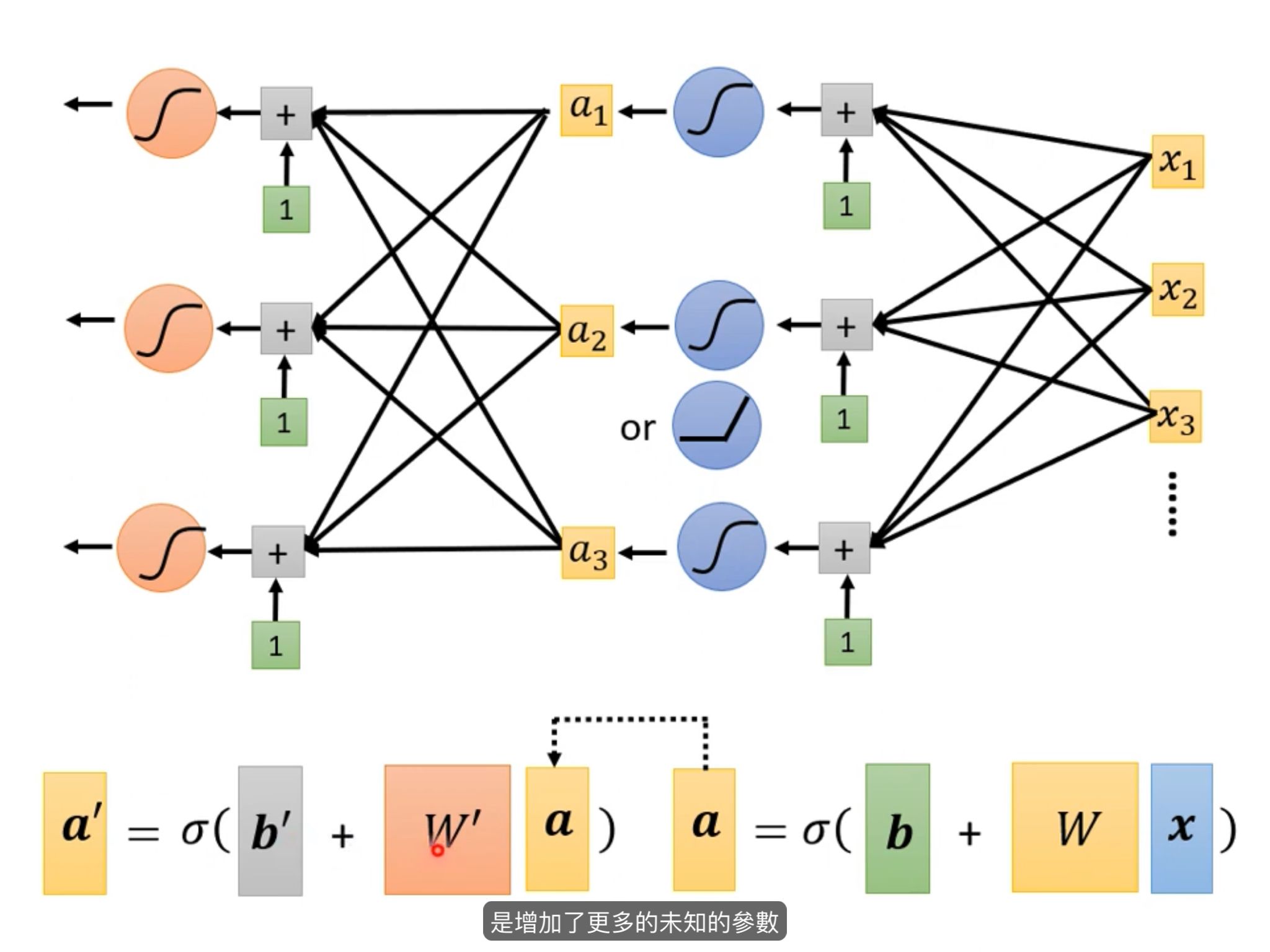
效果比两层多神经元好很多。所以叫深度学习。括弧笑
论文收集 alexnet vgg googlenet residualnet