摘要:
本文主要讲解了Trie的基本思想和原理,实现了几种常见的Trie构造方法,着重讲解Trie在编程竞赛中的一些典型应用。
- 什么是Trie?
- 如何构建一个Trie?
- Trie在编程竞赛中的典型应用有些?
- 例题解析
什么是Trie?
术语取自retrieval中(检索,收回,挽回)的trie,读作“try”,也叫做前缀树或者字典树,是一种有序的树形数据结构。我们常用字典树来保存字符串集合(但不仅限于字符串),如下图就是一个字典树。
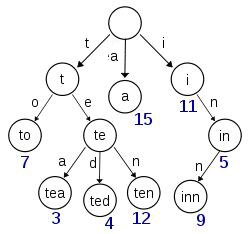
它保存的字符集合是{to,te,tea,ted,ten,a,i,in,inn},可以看出从根结点到单词结点所经过的路径上的所有字母所组成的字符串就是该单词结点对应的字符串。从图中我们可以验证字典树的三条性质:
1.根结点不包含字符,除根结点外,其他结点都只包含一个字符;
2.从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
3.每个节点的所有子节点包含的字符都不相同;
类比查英文字典的过程就是在字典树上查单词的过程,它的核心思想就是利用字符串的公共前缀来减少查询时间,最大限度地减少无谓字字符比较,从而提高效率。
Trie的典型应用是用于统计、排序和保存大量的字符串(不限于字符串),所以经常被用于搜索引擎的文本词频统计,关键词检索。
如何构建一个Trie?
常用的有三种构建方法,分别是转移矩阵法、链表法和左儿子-右兄弟表示法。
转移矩阵法的基本思想和实现
矩阵转移法的思想是将根结点标号为0,其余结点标号为从1开始的正整数,然后用一个二维数组来保存每个结点的所有子节点,用数组下标进行直接存取。具体来说就是用ch[i][j]来表示结点i编号为j的那个子结点(其中编号为j意为该字符在字符集中的编号,比如a在所有的小写字母集合中的编号为0),可以构建如下图所示的转移矩阵(原谅我这不讲究的画图)。
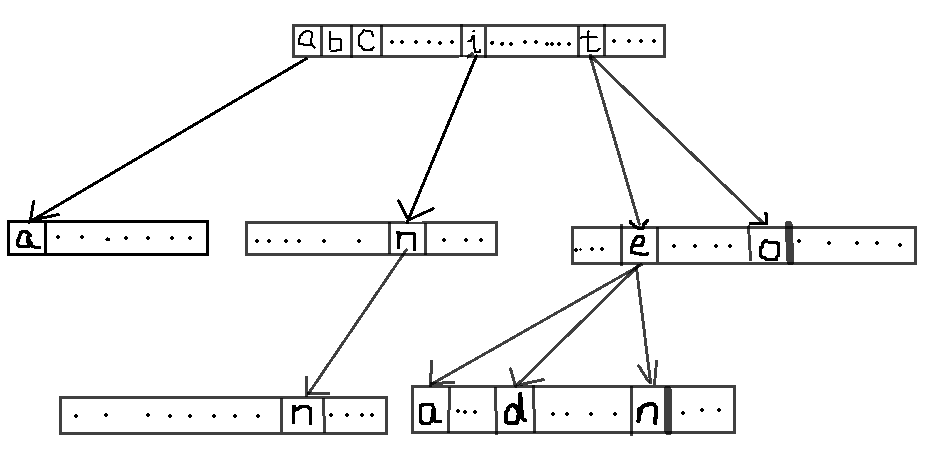
将初始化、插入和查询封装到一个结构体里代码如下:
1 const int maxn = 1001;//模板数 2 const int sigma_size = 26; 3 4 struct Trie { 5 int ch[maxn][sigma_size]; 6 int val[maxn];//规定非单词结点的附加价值为0 7 int sz;//结点总数 8 void init() {//初始化,只有一个根结点并且没有子结点 9 sz = 1; 10 memset(ch[0], 0, sizeof(ch[0])); 11 } 12 int idx(char c) { 13 return c - 'a'; 14 } 15 void insert(char *s, int v) { 16 int n = strlen(s); 17 int u = 0; 18 for(int i = 0; i < n; i++) {//遍历模板串的每一个字母 19 int c = idx(s[i]);//得到该字母的编号 20 if(!ch[u][c]){//该结点不存在 21 memset(ch[sz], 0, sizeof(ch[sz])); 22 val[sz] = 0;//中间结点的附加信息为0 23 ch[u][c] = sz++;//将结点u编号为j的子结点编号为sz 24 } 25 u = ch[u][c];//往下走 26 } 27 val[u] = v; 28 } 29 bool query(char *t) { 30 int m = strlen(t); 31 int u = 0; 32 for(int i = 0; i < m; i++) { 33 int c = idx(t[i]); 34 if(!ch[u][c])//结点u编号为j的子结点为空表示不存在该串 35 return false; 36 u = ch[u][c]; 37 } 38 return true; 39 } 40 };
上述代码中值得注意的是每遇到一个结点才重置二维数组中的一行,看似麻烦,其实可以起到优化内存,防止内存超限的作用,因为如果按照题目要求一次性置零,判题机会直接检测到内存超限,按照上述的方法,有多少单词就用多少内存,只要不是字符集特别大(一般是小写字母集合,如果真的很大采用后面的第三种方法),并不会直接判内存超限。
来看一个具体的问题,输入单词数n和n个单词,查询m个单词是否在之前的单词表中,存在输出Yes,否则输出No。直接套用模板代码如下:


1 #include <cstdio> 2 #include <cstring> 3 const int maxn = 1001;//模板数 4 const int sigma_size = 26; 5 6 struct Trie { 7 int ch[maxn][sigma_size]; 8 int val[maxn];//规定非单词结点的附加价值为0 9 int sz;//结点总数 10 void init() {//初始化,只有一个根结点并且没有子结点 11 sz = 1; 12 memset(ch[0], 0, sizeof(ch[0])); 13 } 14 int idx(char c) { 15 return c - 'a'; 16 } 17 void insert(char *s, int v) { 18 int n = strlen(s); 19 int u = 0; 20 for(int i = 0; i < n; i++) {//遍历模板串的每一个字母 21 int c = idx(s[i]);//得到该字母的编号 22 if(!ch[u][c]){//该结点不存在 23 memset(ch[sz], 0, sizeof(ch[sz])); 24 val[sz] = 0;//中间结点的附加信息为0 25 ch[u][c] = sz++;//将结点u编号为j的子结点编号为sz 26 } 27 u = ch[u][c];//往下走 28 } 29 val[u] = v; 30 } 31 bool query(char *t) { 32 int m = strlen(t); 33 int u = 0; 34 for(int i = 0; i < m; i++) { 35 int c = idx(t[i]); 36 if(!ch[u][c])//结点u编号为j的子结点为空表示不存在该串 37 return false; 38 u = ch[u][c]; 39 } 40 return true; 41 } 42 }; 43 44 Trie trie;//直接使用封装好的结构体 45 int main() 46 { 47 int n; 48 char word[maxn]; 49 trie.init(); 50 printf("输入单词表的个数和单词表: "); 51 scanf("%d", &n); 52 for(int i = 0; i < n; i++) { 53 scanf("%s", word); 54 trie.insert(word, 1); 55 } 56 printf("输入欲查询单词的个数和单词: "); 57 int m; 58 scanf("%d", &m); 59 for(int i = 0; i < m; i++) { 60 scanf("%s", word); 61 if(trie.query(word)) 62 printf("Yes "); 63 else 64 printf("No "); 65 } 66 getchar(); 67 return 0; 68 } 69 70 /*测试样例 71 10 72 asd 73 zxc 74 qwe 75 asdf 76 zxcv 77 qwer 78 asdfgh 79 rewq 80 fdsa 81 vcxz 82 5 83 asdf 84 ghjk 85 zxcv 86 qwer 87 rewq 88 */
测试样例结果:

链表法的基本思想和实现
链表法和转移矩阵法的基本思想是一致的,每个结点都存储有下一个结点的信息,不同的是二维数组使用数组下标方式的方式直接存取,而链表法采用指针指向的方式存取。同样封装到一个结构体中代码如下:
1 struct Node { 2 int cnt;//以当前结点为前缀的单词个数 3 Node* chi[26];//字符集的大小的结点指针数组 4 }; 5 struct Trie { 6 Node* root; 7 void init() {//初始化 8 root = create(); 9 } 10 Node* create() {//新建一个结点 11 Node* tmp = new Node; 12 tmp->cnt = 0; 13 memset(tmp->chi, 0, sizeof(tmp->chi)); 14 return tmp; 15 } 16 void insert(char *s) { 17 Node* u = root; 18 int len = strlen(s); 19 for(int i = 0; i < len; i++) { 20 int c = s[i] - 'a'; 21 if(u->chi[c] == NULL) 22 u->chi[c] = create(); 23 24 u = u->chi[c]; 25 u->cnt ++;//以当前结点为前缀的单词个数++ 26 } 27 } 28 int query(char *t) {//查询 29 int len = strlen(t); 30 Node* u = root; 31 for(int i = 0; i < len; i++) { 32 int c = t[i] - 'a'; 33 if(u->chi[c] == NULL) 34 return 0;//走到字典树的叶子节点该单词还没结束,以该串为前缀的单词数为0 35 36 u = u->chi[c]; 37 } 38 return u->cnt; 39 } 40 void freeTrie(Node* u) {//递归释放内存 41 if(u == NULL) 42 return; 43 for(int i = 0; i < 26; i ++) { 44 if(u->chi[i] != NULL) 45 freeTrie(u->chi[i]); 46 } 47 free(u); 48 } 49 };
可以看出,前两种方法的基本思想是一致的,只是存取方式略有差异。它们除了都存在稀疏现象严重,空间利用率低的问题之外,当碰上字符集很大题目,比如UVa 11732 “strcmp()” Anyone?,字符集是10个数字和大小写字母,想要遍历整个Trie的时候必须依次枚举字符集各个位置是否为空才行,所以还存在遍历时间开销较大的问题。(需要遍历Trie的问题很多比如计算多个模板的最长公共前缀问题)而第三种构建方式左儿子-右兄弟表示法可以很好的解决时间和空间上的问题。
左儿子-右兄弟表示法的基本思想和实现
左儿子-右兄弟表示法的精髓在于将之前的字典树的多叉树结构转化为了二叉树结构。这里借鉴《算法入门经典 训练指南》中的数组表示法。主要使用了两个数组,一个是head数组表示第i个结点的左儿子编号和next数组表示第i个结点的右兄弟编号。同样封装在一个结构体中代码如下:
1 const int maxw = 1000010; //单词的最大个数 2 const int maxwl = 101;//单词的最大长度 3 const int maxnode = maxw * maxwl + 10; 4 5 struct Trie { 6 int head[maxnode]; //head[i]表示第i个结点的左儿子的编号 7 int next[maxnode]; //next[i]表示第i个结点的右兄弟的编号 8 int val[maxnode]; //以该结点为前缀的单词的个数 9 char ch[maxnode]; //ch[i]表示第i个结点的字符 10 int sz; //结点总数 11 12 void init() { 13 sz = 1; 14 head[0] = next[0] = val[0] = 0; 15 } 16 void insert(char *s) { 17 int u = 0, len = strlen(s), v; 18 for(int i = 0; i < len; i ++) { 19 //在当前u的所有儿子中找s[i] 20 bool found = false; 21 for(v = head[u]; v != 0; v = next[v]) {//遍历当前u的所有儿子 22 if(ch[v] == s[i]) { 23 found = true;//找到 24 break; 25 } 26 } 27 if(!found) {//没有找到则新建一个结点作为当前结点的儿子 28 v = sz++; 29 ch[v] = s[i]; 30 val[v] = 0; 31 32 next[v] = head[u]; //该结点的右兄弟是head[u](当前结点的左儿子) 33 head[u] = v; //v是当前结点u的左儿子 34 head[v] = 0; //v没有左儿子(叶子结点) 35 } 36 37 u = v;//继续往下走 38 val[u]++; //以当前结点为前缀为单词个数++ 39 } 40 } 41 int query(char *t) { 42 int u = 0, len = strlen(t), v; 43 for(int i = 0; i < len; i++) { 44 bool found = false; 45 for(v = head[u]; v != 0; v = next[v]) { 46 if(ch[v] == t[i]) { 47 found = true; 48 break; 49 } 50 } 51 if(!found) 52 return 0; 53 u = v; 54 } 55 return val[u]; 56 } 57 };
为了比较三种写法的优劣,以HDU 1251 统计难题为例,统计以某串为前缀的单词个数,三种写法如下:
转移矩阵表示法:
1 /* 2 关于转移矩阵的使用注意事项,由于二维矩阵存在较大的空间资源浪费,可以利用C语言的特性,变量声明时不申请空间,只有在赋值 3 的时候申请,所以置零可以分成需要的时候再置。 4 */ 5 #include <cstdio> 6 #include <cstring> 7 const int maxw = 1000010; 8 const int sigm_size = 26; 9 10 struct Trie { 11 int ch[maxw][sigm_size]; 12 int val[maxw]; 13 int sz; 14 15 void init() { 16 sz = 1; 17 memset(ch[0], 0, sizeof(ch[0])); 18 } 19 void insert(char *s) { 20 int u = 0, len = strlen(s); 21 for(int i = 0; i < len; i++) {//遍历模板串的每一个字母 22 int c = s[i] - 'a';//得到该字母的编号 23 if(!ch[u][c]) {//该结点不存在 24 memset(ch[sz], 0, sizeof(ch[sz])); 25 val[sz] = 0;//中间结点的附加信息为0 26 ch[u][c] = sz++;//将结点u编号为j的子结点编号为sz 27 } 28 29 u = ch[u][c];//往下走 30 val[u]++;//以该结点为前缀的单词++ 31 } 32 } 33 int query(char *t) { 34 int len = strlen(t); 35 int u = 0; 36 for(int i = 0; i < len; i++) { 37 int c = t[i] - 'a'; 38 if(!ch[u][c])//结点u编号为j的子结点为空表示不存在该串 39 return 0; 40 u = ch[u][c]; 41 } 42 return val[u]; 43 } 44 }; 45 46 Trie trie; 47 int main() 48 { 49 char word[11]; 50 trie.init(); 51 while(gets(word) != NULL) { 52 int len = strlen(word); 53 if(len == 0) break; 54 trie.insert(word); 55 } 56 while(gets(word) != NULL) { 57 printf("%d ", trie.query(word)); 58 } 59 return 0; 60 }
左儿子-右兄弟表示法:
1 #include <cstdio> 2 #include <cstring> 3 const int maxw = 1000010; //单词的最大个数 4 const int maxwl = 101;//单词的最大长度 5 const int maxnode = maxw * maxwl + 10; 6 7 struct Trie { 8 int head[maxnode]; //head[i]表示第i个结点的左儿子的编号 9 int next[maxnode]; //next[i]表示第i个结点的右兄弟的编号 10 int val[maxnode]; //以该结点为前缀的单词的个数 11 char ch[maxnode]; //ch[i]表示第i个结点的字符 12 int sz; //结点总数 13 14 void init() { 15 sz = 1; 16 head[0] = next[0] = val[0] = 0; 17 } 18 void insert(char *s) { 19 int u = 0, len = strlen(s), v; 20 for(int i = 0; i < len; i ++) { 21 //在当前u的所有儿子中找s[i] 22 bool found = false; 23 for(v = head[u]; v != 0; v = next[v]) {//遍历当前u的所有儿子 24 if(ch[v] == s[i]) { 25 found = true;//找到 26 break; 27 } 28 } 29 if(!found) {//没有找到则新建一个结点作为当前结点的儿子 30 v = sz++; 31 ch[v] = s[i]; 32 val[v] = 0; 33 34 next[v] = head[u]; //该结点的右兄弟是head[u](当前结点的左儿子) 35 head[u] = v; //v是当前结点u的左儿子 36 head[v] = 0; //v没有左儿子(叶子结点) 37 } 38 39 u = v;//继续往下走 40 val[u]++; //以当前结点为前缀为单词个数++ 41 } 42 } 43 int query(char *t) { 44 int u = 0, len = strlen(t), v; 45 for(int i = 0; i < len; i++) { 46 bool found = false; 47 for(v = head[u]; v != 0; v = next[v]) { 48 if(ch[v] == t[i]) { 49 found = true; 50 break; 51 } 52 } 53 if(!found) 54 return 0; 55 u = v; 56 } 57 return val[u]; 58 } 59 }; 60 61 Trie trie; 62 int main() 63 { 64 char word[maxwl]; 65 trie.init();//记得初始化 66 while(gets(word) != NULL) { 67 int len = strlen(word); 68 if(len == 0) break; 69 trie.insert(word); 70 } 71 while(gets(word) != NULL) { 72 printf("%d ", trie.query(word)); 73 } 74 return 0; 75 }
链表法:
1 //c++ AC G++MLE 2 #include <cstdio> 3 #include <cstring> 4 #include <cstdlib> 5 struct Node { 6 int cnt;//以当前结点为前缀的单词个数 7 Node* chi[26];//字符集的大小的结点指针数组 8 }; 9 struct Trie { 10 Node* root; 11 void init() {//初始化 12 root = create(); 13 } 14 Node* create() {//新建一个结点 15 Node* tmp = new Node; 16 tmp->cnt = 0; 17 memset(tmp->chi, 0, sizeof(tmp->chi)); 18 return tmp; 19 } 20 void insert(char *s) { 21 Node* u = root; 22 int len = strlen(s); 23 for(int i = 0; i < len; i++) { 24 int c = s[i] - 'a'; 25 if(u->chi[c] == NULL) 26 u->chi[c] = create(); 27 28 u = u->chi[c]; 29 u->cnt ++;//以当前结点为前缀的单词个数++ 30 } 31 } 32 int query(char *t) {//查询 33 int len = strlen(t); 34 Node* u = root; 35 for(int i = 0; i < len; i++) { 36 int c = t[i] - 'a'; 37 if(u->chi[c] == NULL) 38 return 0;//走到字典树的叶子节点该单词还没结束,以该串为前缀的单词数为0 39 40 u = u->chi[c]; 41 } 42 return u->cnt; 43 } 44 void freeTrie(Node* u) {//递归释放内存 45 if(u == NULL) 46 return; 47 for(int i = 0; i < 26; i ++) { 48 if(u->chi[i] != NULL) 49 freeTrie(u->chi[i]); 50 } 51 free(u); 52 } 53 }; 54 55 Trie trie; 56 int main() 57 { 58 char word[11]; 59 trie.init(); 60 while(gets(word) != NULL) { 61 int len = strlen(word); 62 if(len == 0) break; 63 trie.insert(word); 64 } 65 while(gets(word) != NULL) { 66 printf("%d ", trie.query(word)); 67 } 68 trie.freeTrie(trie.root); 69 return 0; 70 }
对应运行结果如下图所示:

可以看到,运行结果时间最长,内存占用最大的是链表法,转移矩阵法虽然占用内存大,但是在时间上表现优异,而左儿子-右兄弟表示法完美的解决了前两种的结构存在的问题,占用内存小、效率高。
Trie在编程竞赛中有哪些典型的应用呢?
1、前缀统计
给出单词表后问一个串是多少个单词的前缀。例题HDU 1251 统计难题。
2、串的快速检索
给出单词表,问一个单词是否存在在之前的单词表里。例题 HDU 1277 全文检索。当然对于单词检索问题,也可以用STL中的map集合求解,但有时不光是解决存在问题,还需要解决其他问题,比如和前缀有关的问题和效率问题,就应该考虑Trie。
3、串的排序问题
给出许多单词,将其按字典序输出。当然对于字符串排序,使用STL中sort一下也可,但是对于单词量巨大的时候,Trie有其独有的优势:占用空间少,效率又高。
4、计算最长公共前缀。
给出几个字符串,问它们的最长公共前缀是多少。或者像UVa11732 strcmp() Anyone?求解两两串的公共前缀。
5、作为其他算法的数据结构,比如AC自动机。
例题解析
围绕上述Trie在编程竞赛中的典型应用,例题有:
HDU 1251 统计难题(前缀统计),上面给出了三种写法,大致思想都是用单词表构建字典树的时候,每走过一个结点都标记一下,最后以查询串的最后一单词为结点的值就是以该串为前缀的单词的数量。
HDU 1277 全文检索(串的快速检索问题),题意描述是给出一段数字串,再给出关键词,问哪些关键词在上面的数字串里。题意很明显,先根据关键词构建个位数字集合的字典树,然后分割数字文本串,查找到最长前缀就输出,有些同学可能会想,以某个开头的关键词不止一个怎么办,题中说了前四个数字不同,意味着没有前缀相同的关键词,所以就不用考虑了。其实这道题是AC自动机的模板问题,只不过这里使用了复杂度较高的方法。代码如下:
1 #include <cstdio> 2 #include <cstring> 3 #include <vector> 4 using namespace std; 5 6 const int maxl = 60010; 7 char txt[maxl]; 8 const int maxk = 10010; 9 char key[maxk/100];//每个关键词的长度 10 const int maxnode = maxk * 60 + 10;//最大化结点个数 11 12 struct Trie { 13 int ch[maxnode][10]; 14 int val[maxnode]; 15 int sz; 16 17 void init() { 18 sz = 1; 19 memset(ch[sz], 0, sizeof(ch[sz])); 20 } 21 void insert(char *s, int v) {//将每个关键词的序号作为附加信息 22 int u = 0, len = strlen(s); 23 for(int i = 0; i < len; i++) { 24 int c = s[i] - '0';//注意字符集的使用 25 if(!ch[u][c]) { 26 val[sz] = 0; 27 memset(ch[sz], 0, sizeof(ch[sz])); 28 29 ch[u][c] = sz++; 30 } 31 u = ch[u][c]; 32 } 33 val[u] = v; 34 } 35 int query(char *t) { 36 int u = 0, len = strlen(t); 37 for(int i = 0; i < len; i++) { 38 int c = t[i] - '0'; 39 if(!ch[u][c]) 40 break; 41 u = ch[u][c]; 42 } 43 return val[u]; 44 } 45 }; 46 47 Trie trie; 48 int main() 49 { 50 int n,m; 51 while(scanf("%d%d", &n, &m) != EOF) { 52 trie.init(); 53 int len = 0; 54 for(int i = 0; i < n; i++) { 55 scanf("%s", txt+len); 56 len = strlen(txt); 57 } 58 for(int i = 1; i <= m; i++) { 59 int v; 60 scanf("%*s%*s%d%*c%s", &v, key); 61 trie.insert(key, i); 62 } 63 64 vector<int> p;//保存存在的关键词的编号 65 for(int i = 0; i < len; i++) { 66 int num = trie.query(txt+i); 67 if(num) p.push_back(num); 68 } 69 if(!p.empty()) { 70 printf("Found key:"); 71 for(int i = 0; i < p.size(); i++) 72 printf(" [Key No. %d]", p[i]); 73 puts(""); 74 } 75 else 76 puts("No key can be found ! "); 77 } 78 return 0; 79 }
LA 3942 Remember the word(与DP结合的前缀串查询问题),题意描述是给出一个字符串和单词数n和n个单词,问可以重复使用n个单词,组成该字符串的方法有几种?例如有4个单词a、b、cd、ab,组成abcd有两种方法:a+b+cd和ab+cd。
直觉告诉我们这是一个DP题,关键是定义状态,找到转移方程,我们可以这样定义d[i]为第i个字符开始的字符串(即后缀s[i..L])的分解方法。如果单词x是s[i...L]的前缀的话,那么d[i] = 1*d[i + len(x)],单词x个数1和之后的组合方案书相乘,不要忘了,这道题没有说前几个单词前缀不同,也就是存在多个单词x,那么d[i] = sum{d[i + len(x)]}就可以了。现在问题变成了怎么寻找是串s[i..L]的前缀的单词,一个一个枚举显然不是什么好办法,可以使用Trie,每次枚举s[i..L并]记录它有哪些前缀单词,直接一遍就可以找出全部的前缀单词。代码如下:
1 #include <cstring> 2 #include <vector> 3 using namespace std; 4 5 const int maxn = 4010 * 100 + 10; 6 struct Trie { 7 int ch[maxn][26]; 8 int val[maxn]; 9 int sz; 10 11 void clear() { 12 sz = 1; 13 memset(ch[0], 0, sizeof(ch[0])); 14 } 15 void insert(char *s, int v) { 16 int u = 0; 17 int n = strlen(s); 18 for(int i = 0; i < n; i++) { 19 int c = s[i] - 'a'; 20 if(!ch[u][c]){ 21 memset(ch[sz], 0, sizeof(ch[sz])); 22 val[sz] = 0; 23 ch[u][c] = sz++; 24 } 25 u = ch[u][c]; 26 } 27 val[u] = v; 28 } 29 //查询长度不超过len的前缀单词并记录序号到p中 30 void query(char *t, int len, vector<int>& p) { 31 int u = 0; 32 for(int i = 0; i < len; i++) { 33 if(t[i] == '�') 34 break; 35 int c = t[i] - 'a'; 36 if(!ch[u][c]) 37 break; 38 39 u = ch[u][c]; 40 if(val[u] != 0) 41 p.push_back(val[u]); 42 } 43 } 44 }trie; 45 46 #include <cstdio> 47 const int maxwl = 100 + 10; 48 const int maxl = 300010; 49 const int MOD = 20071027; 50 const int maxw = 4000 + 10; 51 52 char txt[maxl]; 53 char word[maxwl]; 54 int len[maxw]; 55 int d[maxl]; 56 57 int main() 58 { 59 int n; 60 int kase = 0; 61 while(scanf("%s", txt) != EOF) { 62 scanf("%d", &n); 63 trie.clear();//多样例,记得初始化 64 for(int i = 1; i <= n; i++) { 65 scanf("%s", word); 66 trie.insert(word, i); 67 len[i] = strlen(word);; 68 } 69 70 int L = strlen(txt); 71 memset(d, 0, sizeof(d)); 72 d[L] = 1; 73 for(int i = L - 1; i >= 0; i --) { 74 vector<int> p; 75 trie.query(txt+i, L - i, p); 76 for(int j = 0; j < p.size(); j++) 77 d[i] = (d[i] + d[i + len[p[j]]]) % MOD; 78 } 79 printf("Case %d: %d ", ++kase, d[0]); 80 } 81 return 0; 82 }
串的排序问题,就是字符串的排序,就不找题了,关键是使用字典树进行排序,也不能说是用字典树排序,应该是构造字典树,前序遍历输出的问题。关于前序遍历,主要是递归遍历,需要记录进入子树之前的字符串,用于回溯的时候恢复状态。代码如下:
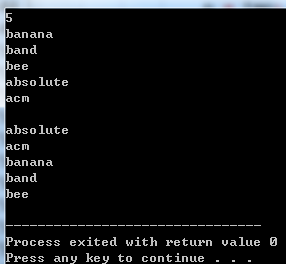
1 #include <cstdio> 2 #include <cstring> 3 #include <vector> 4 #include <iostream> 5 using namespace std; 6 7 struct Node { 8 bool f;//单词结点标志位 9 Node* chl[26]; 10 }; 11 struct Trie { 12 Node* root; 13 string p;//保存单词便于输出 14 void init() {//初始化只有一个结点和清空单词字符串 15 root = cret(); 16 memset(root->chl, 0, sizeof(root->chl)); 17 p.clear(); 18 } 19 Node* cret() { 20 Node* tmp = new Node; 21 tmp->f = false; 22 memset(tmp->chl, 0, sizeof(tmp->chl)); 23 return tmp; 24 } 25 void insert(char *s) { 26 int len = strlen(s); 27 Node* u = root; 28 for(int i = 0; i < len; i++) { 29 int c = s[i] - 'a'; 30 if(u->chl[c] == NULL) 31 u->chl[c] = cret(); 32 33 u = u->chl[c];//往下走 34 } 35 u->f = true;//标记该结点为单词结点 36 } 37 void print(Node* u) { 38 if(u->f)//如果是单词结点就输出当前单词字符串 39 cout<<p<<endl; 40 41 for(int i = 0; i < 26; i++) { 42 if(u->chl[i]) { 43 string tmp = p; 44 char tmpch = ('a' + i); 45 p = p + tmpch;//字符串+时不能直接+('a' + i) 46 print(u->chl[i]); 47 48 p = tmp;//恢复成进入子树之前的状态 49 } 50 } 51 } 52 }trie; 53 54 int main() 55 { 56 int n; 57 char word[111]; 58 //printf("输入待排序单词的个数: "); 59 scanf("%d", &n); 60 trie.init(); 61 while(n--) { 62 scanf("%s", word); 63 trie.insert(word); 64 } 65 puts(""); 66 trie.print(trie.root); 67 return 0; 68 } 69 70 /*测试样例 71 5 72 banana 73 band 74 bee 75 absolute 76 acm 77 */
样例结果如下:
UVa 11732 "strcmp()" Anyone? 计算公共前缀问题,给出n个单词,问这些单词两两调用strcmp函数共比较了多少次?C/C++中的strcmp函数源码如下:
1 int strcmp(char *s, char *t)
2 {
3 int i;
4 for (i = 0; s[i] == t[i]; i++)
5 if(s[i] == '�')
6 return 0;
7 return s[i] - t[i];
8 }
比如aaa和aaa比较,两者相等s[i] == t[i] 和 s[i] == '�'各用了四次,共比较了8词,再比如题中所给的than 和that最后一次比较是s[i] == t[i]失败,之前相同的各两次,所以共比较7次,由此可以发现比较次数和公共前缀有关,那就有了字典树的用武之地,建立字典树,采用深度优先搜索,计算每个结点之前的比较次数,按失败的计算,最后遍历到叶结点时,根据相同个数再加上最后一次比较即可。代码如下:
1 #include <cstdio> 2 #include <cstring> 3 4 const int maxw = 4010; 5 const int maxwl = 1100; 6 const int maxnode = maxw * maxwl + 10; 7 8 struct Trie { 9 int head[maxnode];//第i个结点的儿子 10 int next[maxnode];//第i个结点兄弟 11 char ch[maxnode];//第i个结点的字符 12 int tot[maxnode];//以该结点为根结点的子树的数目,跟前缀相同的单词数一样 13 int sz; 14 long long ans; 15 16 void init() { 17 sz = 1; 18 head[0] = next[0] = tot[0] = 0; 19 } 20 void insert(const char *s) { 21 int u = 0, len = strlen(s), v; 22 tot[0]++; 23 24 for(int i = 0; i <= len; i++) {//是 <= 为了表示出相同字符串的数目,注意将'�'也加入 25 bool found = false; 26 for(v = head[u]; v != 0; v = next[v]) { 27 if(ch[v] == s[i]) { 28 found = true; 29 break; 30 } 31 } 32 if(!found) { 33 v = sz++; 34 ch[v] = s[i]; 35 tot[v] = 0; 36 37 next[v] = head[u]; 38 head[u] = v; 39 head[v] = 0; 40 } 41 u = v; 42 tot[u]++; 43 } 44 } 45 //统计最长公共前缀为u的所有串的比较次数 46 void dfs(int depth, int u) { 47 if(head[u] == 0) //叶结点,如果该叶结点没有相同的串,tot[u] == 1对答案没有影响,如果有那么 48 ans += tot[u] * (tot[u] - 1) * depth; 49 else { 50 int sum = 0; 51 for(int v = head[u]; v != 0; v = next[v])//统计当前结点之前的比较次数 52 sum += tot[v] * (tot[u] - tot[v]);//子树v中选择一个,其他子树中选一个 53 //除以2因为统计了两次,所有串的比较次数乘以当前的深度等于总的比较次数 54 //乘以2倍的深度加1是都先按不相等处理,最后到叶子结点再加 55 ans += sum / 2 * (2 * depth + 1); 56 for(int v = head[u]; v != 0; v = next[v])//统计当前结点的所有子节点的比较次数 57 dfs(depth+1, v); 58 } 59 } 60 long long count(){ 61 ans = 0; 62 dfs(0, 0); 63 return ans; 64 } 65 }trie; 66 67 int main() 68 { 69 int n, kase = 0; 70 char word[maxwl]; 71 while(scanf("%d", &n) == 1 && n) { 72 trie.init(); 73 for(int i = 0; i < n; i++) { 74 scanf("%s", word); 75 trie.insert(word); 76 } 77 printf("Case %d: %lld ",++kase, trie.count()); 78 } 79 return 0; 80 }
Trie做为AC自动机的数据结构的应用就在AC自动机中具体解释。
到此,有关Trie的解析就结束了,本文主要讲述了Trie在编程竞赛中的一些典型应用,想掌握它并不难,关键是配合一些具体的应用和例题帮助自己更具实践性的掌握,可以根据具体的提示和问题,自己实现以下相关的程序,达到活学活用的效果。(原创不易,转载请注明出处哦)