一、 实验目的
编制一个词法分析程序
二、 实验内容和要求
- 输入:源程序字符串
- 输出:二元组(种别,单词本身)
- 待分析语言的词法规则
三、 实验方法、步骤及结果测试
- 1. 源程序名:压缩包文件(rar或zip)中源程序名 cifafenxi.c cifafenxi.exe
- 2. 原理分析及流程图
|
|
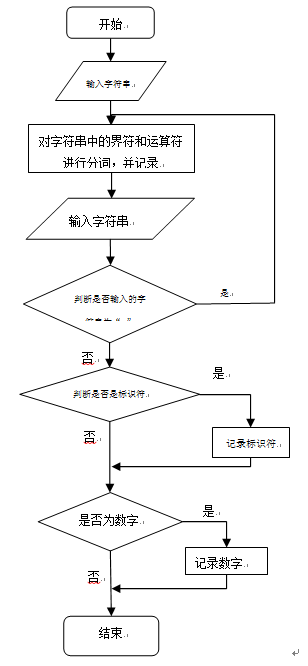
- 3. 主要程序段及其解释:
#include<stdio.h>
#include<string.h>
#include<iostream.h>
char prog[80],token[8];
char ch;
int syn,p,m=0,n,row,sum=0;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner()
{
for(n=0;n<8;n++) token[n]=NULL;
ch=prog[p++];
while(ch==' ')
{
ch=prog[p];
p++;
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
m=0;
while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
token[m++]=ch;
ch=prog[p++];
}
token[m++]='�';
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>='0'&&ch<='9'))
{
{
sum=0;
while((ch>='0'&&ch<='9'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
}
p--;
syn=11;
if(sum>32767)
syn=-1;
}
else switch(ch)
{
case'<':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='>')
{
syn=21;
token[m++]=ch;
}
else if(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case'>':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case':':m=0;token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=18;
token[m++]=ch;
}
else
{
syn=17;
p--;
}
break;
case'*':syn=13;token[0]=ch;break;
case'/':syn=14;token[0]=ch;break;
case'+':syn=15;token[0]=ch;break;
case'-':syn=16;token[0]=ch;break;
case'=':syn=25;token[0]=ch;break;
case';':syn=26;token[0]=ch;break;
case'(':syn=27;token[0]=ch;break;
case')':syn=28;token[0]=ch;break;
case'#':syn=0;token[0]=ch;break;
case'
':syn=-2;break;
default: syn=-1;break;
}
}
int main()
{
p=0;
row=1;
cout<<"please input string:"<<endl;
do
{
cin.get(ch);
prog[p++]=ch;
}
while(ch!='#');
p=0;
do
{
scaner();
switch(syn)
{
case 11: cout<<"("<<syn<<","<<sum<<")"<<endl; break;
case -1: cout<<"Error in row "<<row<<"!"<<endl; break;
case -2: row=row++;break;
default: cout<<"("<<syn<<","<<token<<")"<<endl;break;
}
}
while (syn!=0);
}
- 4. 运行结果及分析
一般必须配运行结果截图,结果是否符合预期及其分析。
(截图需根据实际,截取有代表性的测试例子)

四、 实验总结
这个实验一开始不是很懂,感觉非常困难,在同学的帮助,参考了网上的一些资料,渐渐有了一些了解。这个实验需要为不同的关键词分配不同的种别码,再一一输出,我的代码相比别人还不够完善,以后需要多多努力。