Scrapy 和 scrapy-redis的区别
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
pip install scrapy-redis
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
Scheduler
Duplication Filter
Item Pipeline
Base Spider
scrapy-redis架构
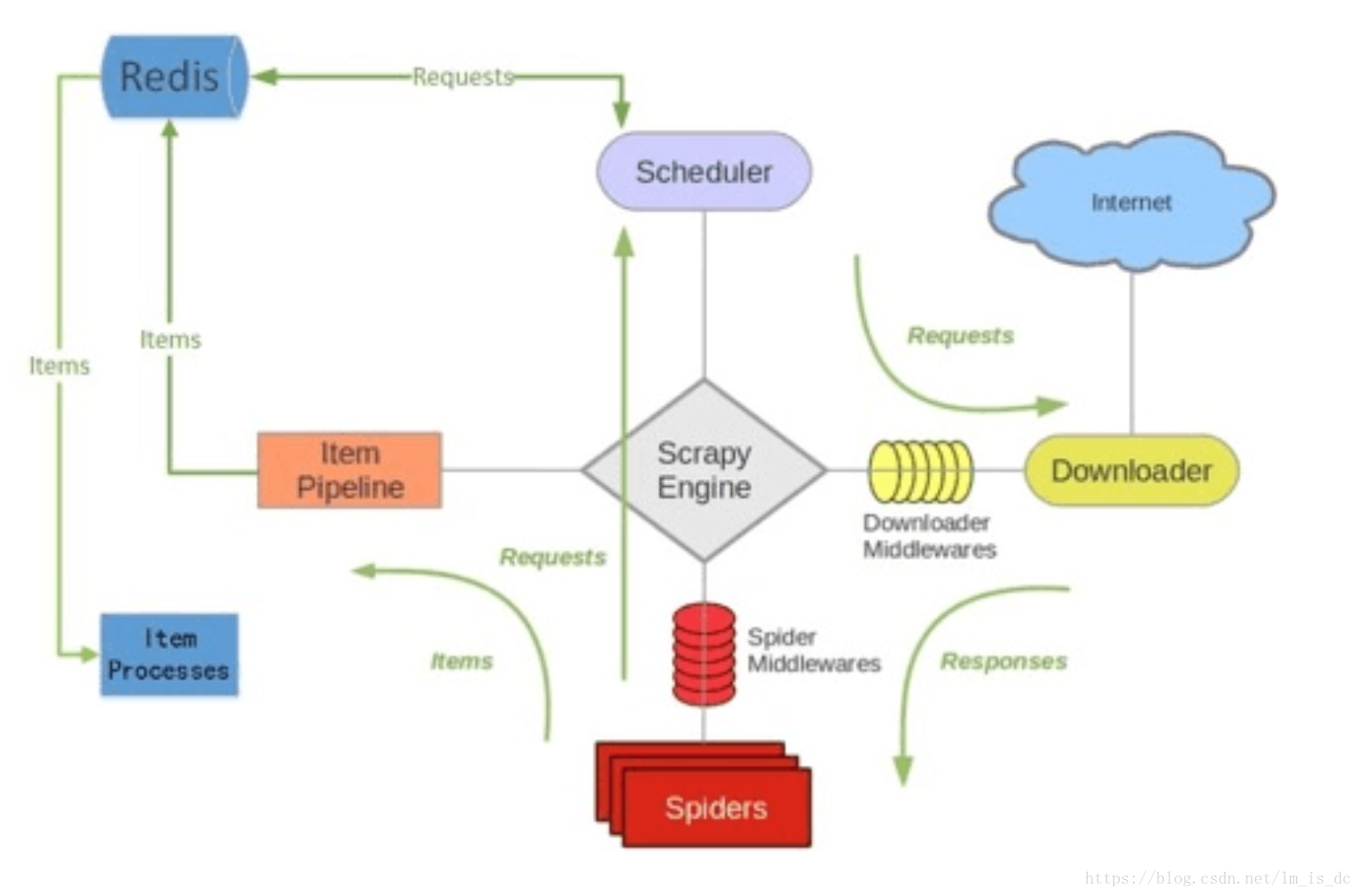
如上图所⽰示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
Scheduler:
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue(https://github.com/scrapy/queuelib/blob/master/queuelib/queue.py)),但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。这个核心的判重功能是这样实现的:
def request_seen(self, request):
# self.request_figerprints就是一个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现items processes集群。
Base Spider
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
Scrapy-Redis分布式策略:
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
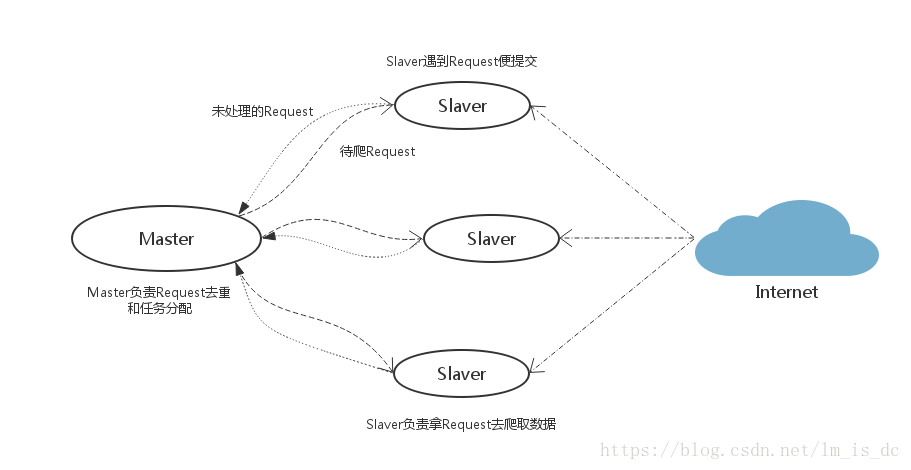
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
一、安装Redis
安装Redis:http://redis.io/download
安装完成后,拷贝一份Redis安装目录下的redis.conf到任意目录,建议保存到:/etc/redis/redis.conf(Windows系统可以无需变动)
二、修改配置文件 redis.conf
#是否作为守护进程运行
daemonize no
#Redis 默认监听端口
port 6379
#客户端闲置多少秒后,断开连接
timeout 300
#日志显示级别
loglevel verbose
#指定日志输出的文件名,也可指定到标准输出端口
logfile redis.log
#设置数据库的数量,默认最大是16,默认连接的数据库是0,可以通过select N 来连接不同的数据库
databases 32
#Dump持久化策略
#当有一条Keys 数据被改变是,900 秒刷新到disk 一次
#save 900 1
#当有10 条Keys 数据被改变时,300 秒刷新到disk 一次
save 300 100
#当有1w 条keys 数据被改变时,60 秒刷新到disk 一次
save 6000 10000
#当dump .rdb 数据库的时候是否压缩数据对象
rdbcompression yes
#dump 持久化数据保存的文件名
dbfilename dump.rdb
########### Replication #####################
#Redis的主从配置,配置slaveof则实例作为从服务器
#slaveof 192.168.0.105 6379
#主服务器连接密码
# masterauth <master-password>
############## 安全性 ###########
#设置连接密码
#requirepass <password>
############### LIMITS ##############
#最大客户端连接数
# maxclients 128
#最大内存使用率
# maxmemory <bytes>
########## APPEND ONLY MODE #########
#是否开启日志功能
appendonly no
# AOF持久化策略
#appendfsync always
#appendfsync everysec
#appendfsync no
################ VIRTUAL MEMORY ###########
#是否开启VM 功能
#vm-enabled no
# vm-enabled yes
#vm-swap-file logs/redis.swap
#vm-max-memory 0
#vm-page-size 32
#vm-pages 134217728
#vm-max-threads 4
打开你的redis.conf配置文件,示例:
非Windows系统:sudo vi /etc/redis/redis.conf
Windows系统:C:IntelRedisconf edis.conf
Master端redis.conf里注释bind 127.0.0.1,Slave端才能远程连接到Master端的Redis数据库。
daemonize no表示Redis默认不作为守护进程运行,即在运行redis-server /etc/redis/redis.conf时,将显示Redis启动提示画面;
daemonize yes
则默认后台运行,不必重新启动新的终端窗口执行其他命令,看个人喜好和实际需要。
三、测试Slave端远程连接Master端
测试中,Master端Windows 10 的IP地址为:192.168.199.108
Master端按指定配置文件启动redis-server,示例:
非Windows系统:sudo redis-server /etc/redis/redis.conf
Windows系统:命令提示符(管理员)模式下执行redis-server C:IntelRedisconf
edis.conf读取默认配置即可。
Master端启动本地redis-cli:
slave端启动redis-cli -h 192.168.199.108,-h 参数表示连接到指定主机的redis数据库
注意:Slave端无需启动redis-server,Master端启动即可。只要 Slave 端读取到了 Master 端的 Redis 数据库,则表示能够连接成功,可以实施分布式。
源码自带项目说明:
使用scrapy-redis的example来修改
先从github上拿到scrapy-redis的示例,然后将里面的example-project目录移到指定的地址:
clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git
直接拿官方的项目范例,改名为自己的项目用(针对懒癌患者)
mv scrapy-redis/example-project ~/scrapyredis-project
我们clone到的 scrapy-redis 源码中有自带一个example-project项目,这个项目包含3个spider,分别是dmoz, myspider_redis,mycrawler_redis。
一、dmoz (class DmozSpider(CrawlSpider))
这个爬虫继承的是CrawlSpider,它是用来说明Redis的持续性,当我们第一次运行dmoz爬虫,然后Ctrl + C停掉之后,再运行dmoz爬虫,之前的爬取记录是保留在Redis里的。
分析起来,其实这就是一个 scrapy-redis 版CrawlSpider类,需要设置Rule规则,以及callback不能写parse()方法。
执行方式:scrapy crawl dmoz
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoz.org']
start_urls = ['http://www.dmoz.org/']
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
二、myspider_redis (class MySpider(RedisSpider))
这个爬虫继承了RedisSpider, 它能够支持分布式的抓取,采用的是basic spider,需要写parse函数。
其次就是不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider_redis'
# 注意redis-key的格式:
redis_key = 'myspider:start_urls'
# 可选:等效于allowd_domains(),__init__方法按规定格式写,使用时只需要修改super()里的类名参数即可
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
# 修改这里的类名为当前类名
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
注意:
RedisSpider类 不需要写allowd_domains和start_urls:
scrapy-redis将从在构造方法__init__()里动态定义爬虫爬取域范围,也可以选择直接写allowd_domains。
必须指定redis_key,即启动爬虫的命令,参考格式:redis_key = 'myspider:start_urls'
根据指定的格式,start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
执行方式:
通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider myspider_redis.py
在Master端的redis-cli输入push指令,参考格式:
$redis > lpush myspider:start_urls http://www.dmoz.org/
Slaver端爬虫获取到请求,开始爬取。
lrange mycrawler:start_url 0 -1
三、mycrawler_redis (class MyCrawler(RedisCrawlSpider))
这个RedisCrawlSpider类爬虫继承了RedisCrawlSpider,能够支持分布式的抓取。因为采用的是crawlSpider,所以需要遵守Rule规则,以及callback不能写parse()方法。
同样也不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
class MyCrawler(RedisCrawlSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'mycrawler_redis'
redis_key = 'mycrawler:start_urls'
rules = (
# follow all links
Rule(LinkExtractor(), callback='parse_page', follow=True),
)
# __init__方法必须按规定写,使用时只需要修改super()里的类名参数即可
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
# 修改这里的类名为当前类名
super(MyCrawler, self).__init__(*args, **kwargs)
def parse_page(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
注意:
同样的,RedisCrawlSpider类不需要写allowd_domains和start_urls:
scrapy-redis将从在构造方法__init__()里动态定义爬虫爬取域范围,也可以选择直接写allowd_domains。
必须指定redis_key,即启动爬虫的命令,参考格式:redis_key = 'myspider:start_urls'
根据指定的格式,start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
执行方式:
通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider mycrawler_redis.py
在Master端的redis-cli输入push指令,参考格式:
$redis > lpush mycrawler:start_urls http://www.dmoz.org/
爬虫获取url,开始执行。
总结:
如果只是用到Redis的去重和保存功能,就选第一种;
如果要写分布式,则根据情况,选择第二种、第三种;
通常情况下,会选择用第三种方式编写深度聚焦爬虫。