Tensorflow2.0笔记
本博客为Tensorflow2.0学习笔记,感谢北京大学微电子学院曹建老师
3.MNIST数据集(手写体数字识别)
3.1 简介
MNIST 数据集一共有 7 万张图片,是 28×28 像素的 0 到 9 手写数字数据集, 其中 6 万张用于训练,1 万张用于测试。每张图片包括 784(28×28)个像素点, 使用全连接网络时可将 784 个像素点组成长度为 784 的一维数组,作为输入特征。数据集图片如下所示。
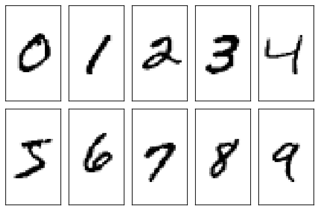
3.1 导入数据集
keras 函数库中提供了使用 mnist 数据集的接口,代码如下所示,可以使用load_data()直接从 mnist 中读取测试集和训练集。
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
输入全连接网络时需要先将数据拉直为一维数组,把 784 个像素点的灰度值作为输入特征输入神经网络。
tf.keras.layers.Flatten()
使用 plt 库中的两个函数可视化训练集中的图片。
plt.imshow(x_train[0],cmap=’gray’)
plt.show()
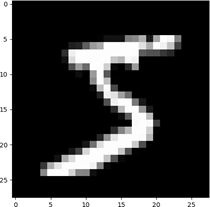
使用 print 打印出训练集中第一个样本以二位数组的形式打印出来,如下所示。
print(“x_train[0]:”,x_train[0])

打印出第一个样本的标签,为 5。
print("y_train[0]:",y_train[0]) y_train[0]:5
打印出测试集样本的形状,共有 10000 个 28 行 28 列的三维数据。
print(“x_test.shape:”x_test.shape) x_test.shape:(10000,28,28)
3.3训练MNIST数据集
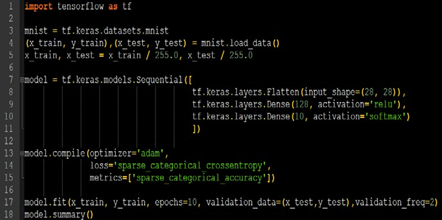
使用 Sequential 实现手写数字识别
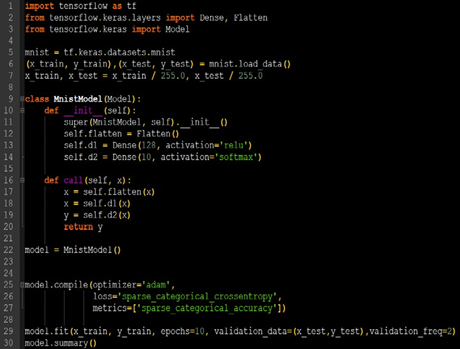
使用 class 实现手写数字识别
值得注意的是训练时需要将输入特征的灰度值归一化到[0,1]区间,这可以使网络更快收敛。
训练时每个 step 给出的是训练集 accuracy 不具有参考价值,有实际评判价值的是 validation_freq 中设置的隔若干轮输出的测试集 accuracy。如下图所示