测试faster-rcnn时,cpu计算速度较慢,调整代码改为gpu加速运算
- 将 with tf.Session() as sess: 替换为
1 gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.9) 2 with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,log_device_placement=True),graph=detection_graph) as sess: 3 with tf.device("/gpu:0"):
之后出现显存占满、而GPU利用率为0的情况,经查阅官方文档得知“在GPU上,tf.Variable操作只支持实数型(float16 float32 double)的参数。不支持整数型参数”
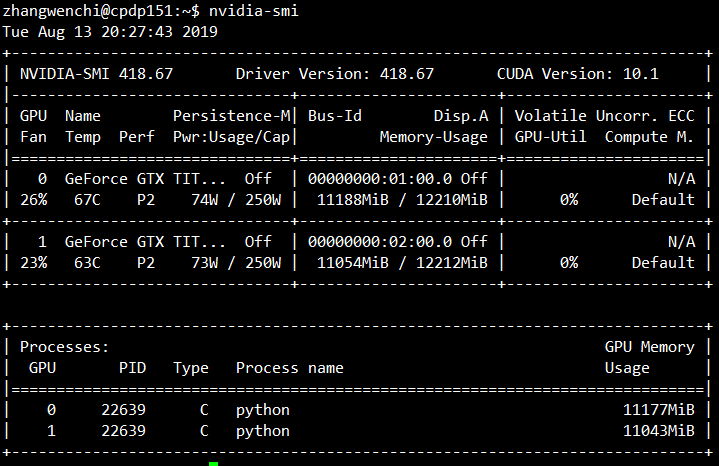

CPU计算几乎占满,可见tensorflow的运行空间在显存上,而计算实际是在cpu上执行的
用如下代码可检测tensorflow的能使用设备情况:
1 from tensorflow.python.client import device_lib 2 print(device_lib.list_local_devices())
Tensorflow程序可以通过tf.device函数来指定运行每一个操作的设备,这个设备可以是本地CPU或GPU,也可以是某一台远程服务器。
tf.device函数可以通过设备的名称来指定执行运算的设备。
如CPU在tensorflow中的名称为/cpu:0。在默认情况下,即使机器有很多个CPU,tensorflow也不会区分它们,所有的CPU都使用/cpu:0作为名称。
而一台机器上不同GPU的名称是不同的,第n个GPU在tensorflow中的名称为/gpu:n。
tensorflow提供了一个会计的方式来查看运行每一个运算的设备。在生成会话时,可以通过设置log_device_placement参数来打印运行每一个运算的设备。
1 import tensorflow as tf 2 a=tf.constant([1.0,2.0,3.0],shape=[3],name='a') 3 b=tf.constant([1.0,2.0,3.0],shape=[3],name='b') 4 c=a+b 5 #通过log_device_placement参数来输出运行每一个运算的设备 6 sess=tf.Session(config=tf.ConfigProto(log_device_placement=True)) 7 print (sess.run(c))
在以上代码中,tensorflow程序生成会话时加入了参数log_device_placement=True,所以程序会将运行每一个操作的设备输出到屏幕。
在配置好GPU的环境中,如果操作没有明确指定运行设备,那么tensorflow会优先选择GPU。但是,尽管有4个GPU,在默认情况下,tensorflow只会将运算优先放到/gpu:0上。如果需要将某些运算放到不同的GPU或CPU上,就需要通过tf.device来手工指定。
1 import tensorflow as tf 2 3 a=tf.Variable(0,name='a') 4 with tf.device('/gpu:0'): 5 b=tf.Variable(0,name='b') 6 #通过allow_soft_placement参数自动将无法放在GPU上的操作放回CPU上 7 sess=tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True)) 8 sess.run(tf.initialize_all_variables()
在以上代码中可以看到生成常量a和b的操作被加载到CPU上,而加法操作被放到第二个GPU上。在tensorflow中,不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,程序就会报错。
在GPU上,tf.Variable操作只支持实数型(float16 float32 double)的参数。不支持整数型参数。tensorflow在生成会话时可以指定allow_soft_placement参数。当这个参数设置为True时,如果运算无法由GPU执行,那么tensorflow会自动将它放到CPU上执行。
改进方式未完待续......
ref:https://blog.csdn.net/VioletHan7/article/details/82769531