聚集(clustered)索引
数据行的的物理顺序与列值(一般主键事务那一列)的逻辑顺序相同,一个表中只能有一个聚集索引。
一个表就像以前用的新华字典,聚集索引就像拼音目录,而每个字存放的页码就是数据的物理地址,如果查询一个字,只需查询该字对应在字典拼音目录对应的页码,就可以查询到这个字所在的位置,而拼音目录对应的A-Z的字顺序,和新华字典实际存储的字的顺序A-Z也是一样的。数据行的物理顺序与列值的顺序相同,如果查询的id比较靠后的数据,那么这行数据的地址在磁盘中的物理地址也会比较靠后。而且由于物理地址排列方式与聚集索引的顺序相同,所以就只能建立聚集索引。
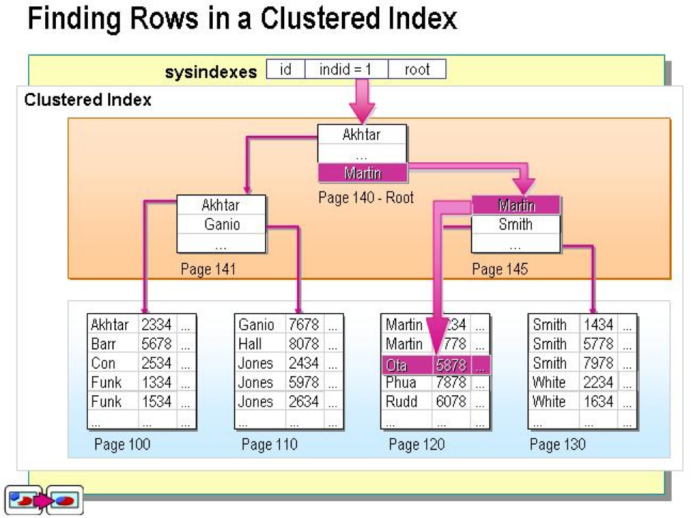
聚集索引的好处是索引的叶节点就是对应的数据节点,可以直接获取到对应的全部列的数据,而非聚集索引在索引没有覆盖到对应的列的时候需要进行二次查询,因此在查询方面,聚集索引的速度往往会更占优势。
非聚集索引
该索引中索引的逻辑顺序与磁盘上的物理存储顺序不同,一个表中可以有多个非聚集索引。
非聚集索引就像字典中的偏旁字典,它的结构顺序与实际存放顺序不一定一致。
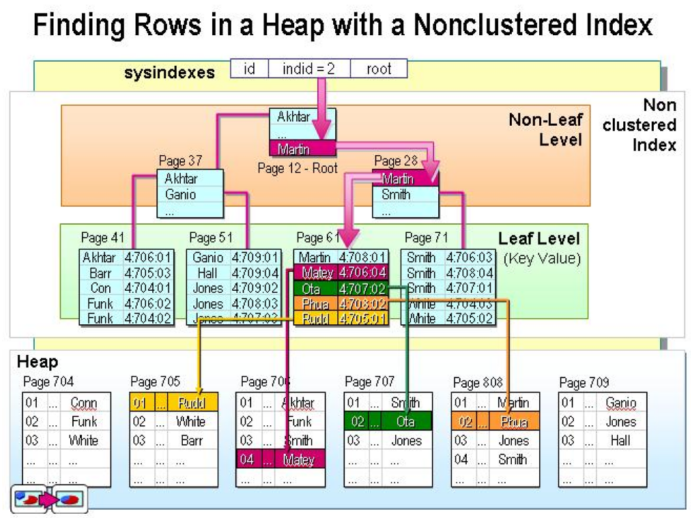
非聚集索引的叶节点 仍然是索引节点,只是有一个指针指向对应的数据块,如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么还要进行第二次查询,查询节点上对应的数据行的数据。
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行 的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此 类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。