阿里搜索离线大数据平台架构
首先我们来看一张离线数据处理系统(Offline System)的是一部图,以此来思考什么是搜索离线?
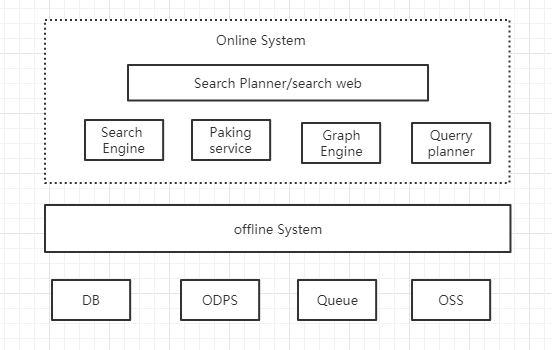
什么是离线?在阿里搜索工程体系中我们把搜索引擎、在线算分、SearchPlanner等ms级响应用户请求的服务称之为“在线”服务;与之相对应的,将各种来源数据转换处理后送入搜索引擎等“在线”服务的系统统称为“离线”系统。商品搜索的业务特性(海量数据、复杂业务)决定了离线系统从诞生伊始就是一个大数据系统,
大数据系统有以下的特点,任务模型上区分全量和增量、需要支持多样化的输入和输出数据源、需要提供一定能力的数据处理能力,全量是指将搜索业务数据全部重新处理生成,并传送给在线引擎,一般是每天一次,增量是指将上游数据源实时发生的数据变化更新到在线引擎中,性能方面有较高要求。全量需要极高吞吐能力,确保数以亿计的数据可以在数小时内完成。增量则需要支持数万TPS秒级的实时性,还需要有极高的可用性。
阿里商品搜索体系从使用hadoop+habase的淘宝搜索阶段到组件化开发的离线平台阶段,整个搜索离线系统的演进是沿着性能和效率两条主线,以业务和技术为双驱动,一步一步走到今天。这是一个技术与业务高度融合互动,互相促进发展的典型样例 离线平台的技术架构展开,主要分为平台流程以及计算和存储架构等几个方面。离线平台技术组件结构的组件主要分为几个方面,分布式任务调度平台Maat,执行引擎,Flink的阿里内部版本Blink等,阿里采用基于hbase的存储结构和基于flink的计算架构,采用hbase做为离线系统的内部数据存储,成功解决了每天全量时对上游Mysql造成很大压力的问题,大幅度的提升了整体系统的吞吐,采用blink可以直接完成生成HFile的任务,调度可以大幅的节省计算资源,提高集群效率。
搜索离线数据处理是一个典型的海量数据处理的模型,他将批次处理和实时计算,搜索内部技术结合开源大数据存储和计算系统,针对自身业务和技术特点构建了搜索离线平台,提供复杂业务场景下单日批次处理千亿级数据,秒级实时百万TPS吞吐的计算能力。离线平台目前支持不同业务线的搜索业务需求,大幅度提高业务执行的效率成为了搜索平台中的重要组成部分