什么是搜索算法
搜索算法是利用计算机的高性能来有目的的穷举一个问题解空间的部分或所有的可能情况,从而求出问题的解的一种方法。现阶段一般有枚举算法、深度优先搜索、广度优先搜索、A*算法、回溯算法、蒙特卡洛树搜索、散列函数等算法。在大规模实验环境中,通常通过在搜索前,根据条件降低搜索规模;根据问题的约束条件进行剪枝;利用搜索过程中的中间解,避免重复计算这几种方法进行优化。
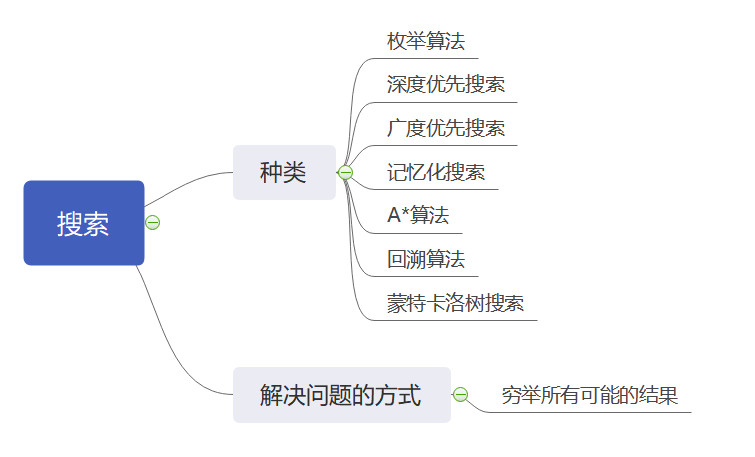
搜索方式
首先给大家扫个盲在搜索中,不仅仅只有常见的递归式搜索,也存在着一部分正向迭代式搜索,但是在真正的使用中递归式搜索占到了绝大多数,基本上所有的递归式搜索用是递归都可以实现只不过代价比较大
比如我们想要求出数字 1 - 3之间所有数字的全排列
这个问题很简单,简单到不想用手写。。还是写一下吧
对于这个问题我们只用三重循环就可以完全搞定它
int n = 3;
for(int i = 1;i <= n ;i ++)
{
for(int j = 1;j <= n ;j ++)
{
for(int k = 1;k <= n; k++)
{
if(i != j && i != k && j != k)
{
printf("%d %d %d
",i ,j ,k);
}
}
}
}
这个时候有同学就会问了,既然用递推就可以实现我们的搜索那么我们为什么还要费劲的去写递归呢?
原因是之前举的哪一个例子规模很小,如果此时我们讲n 换成10 我们需要枚举 1 - 10的全排列那么你用递推的话代码大致式这样的
int n = 3;
for(int i = 1;i <= n ;i ++)
{
for(int j = 1;j <= n ;j ++)
{
for(int k = 1;k <= n; k++)
{
for(int o = 1; 0 <= n ;o++)
{
for(int p = 1;p <= n ; p++)
{
for()
{
for()
.......不写了 我吐了
}
}
}
}
}
}
首先不说你有没有心情实现,光是变量的字母引用 就够你喝一壶了 这里n = 10 还没超过26,那如果超过了26,你岂不是要把汉字搬来了....
这里就暴露出一个问题。我们的迭代式搜索存在着一个很大的局限性,那就是所能够完成的规模有限,而且代码十分冗余。此时就展现出我们递归搜索的强大了
void serch(int now)
{
if(now == n)
{
for(int i = 0;i < n; i++)
printf("%d",a[i]);
return;
}else{
for(int i = 1;i <= n;i ++)
{
if(!vis[i]){
a[now] = i;vis[i] = 1;
dfs(now+1);vis[i] = 0;
}
}
}
}
同样的实现1-10的全排列 我们利用递归很简单的就实现了,但是递推却难以实现。
既然我们已经知道了递归式搜索的好处那么我们就来先了解递归搜索的灵魂递归树
递归树的引入
我们会发现无论是我们的正向穷举算法还是我们的递归式搜索枚举都可以产生一棵搜索树,而这颗搜索树也通常是辅助我们解决问题的关键,当然正向递推枚举会比递归枚举要快的多,其差别之一就是迭代式的搜索算法不会用到系统栈,而递归的搜索会大量的调用系统栈。
在我们写递归搜索算法得时候通常会有一个小问题,我该在什么时候让他自身调用自身去进行深层递归呢
还是我们之前得那个问题 在得出所有1 - 3 的全排列
首先我们思考 既然是 1 - 3 的全部排列那说明所有的位置只能是有三个 :_ _ _ 我们在这三个位置上填充数字即可每一个位置都可以填充 1 - 3这三个数字
于是我们可以得到如下结构的一颗树:
由于画图技术烂没能把树画完望大家谅解
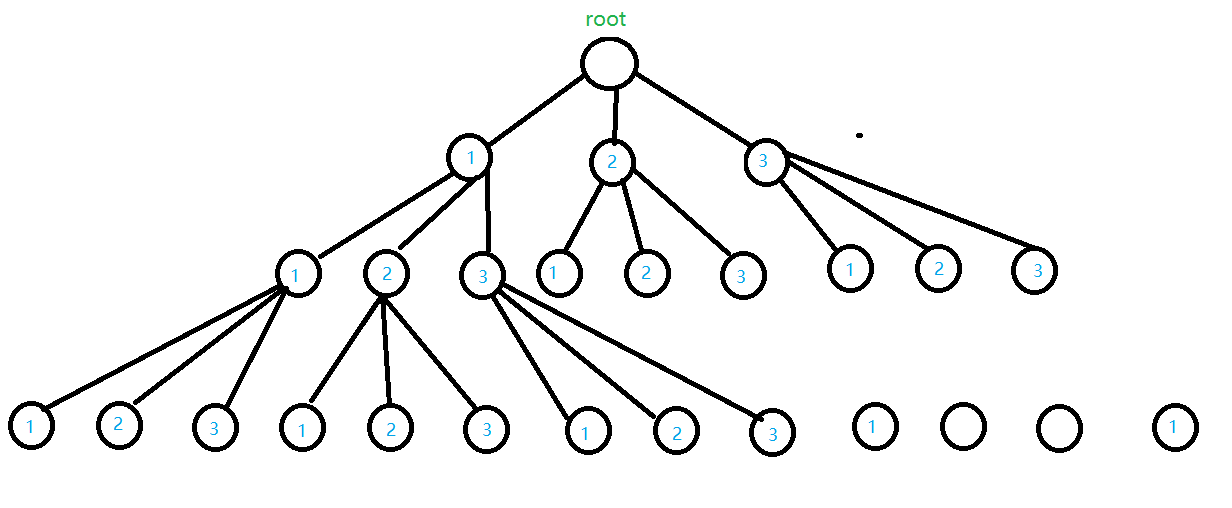
根据上图我们发现虽然上图是一个完整的递归树名单时并不是我们想要的递归树,因为我们需要让一个排列中的树字互相都不重复。那么我们就需要进行一些操作把我们不需要的分支给去掉
于是我们得到
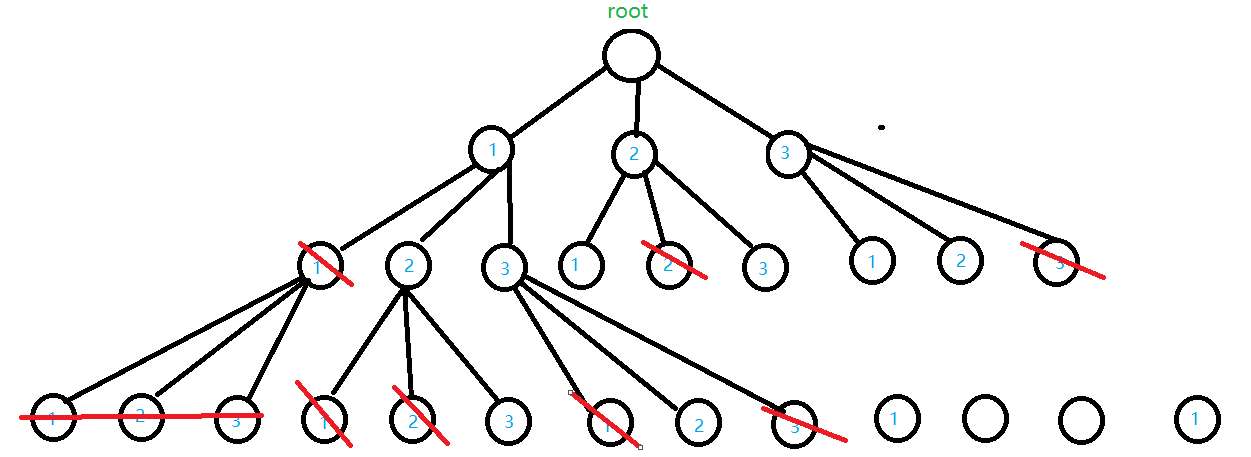
这种将不需要的分支给去掉的操作我们将其称之为剪枝操作
这就是一个简单的递归搜索程序下面把代码贴出来,同学们细心观察一下我们的剪枝操作究竟在哪里体现的呢
#include <iostream>
#include <algorithm>
#include <cstdio>
using namespace std;
const int N = 10;
int n,a[N];bool vis[N];
void dfs(int now)
{
if(now == n)
{
for(int i = 0;i < n; i++)
cout << a[i] << " ";
cout << endl;
}
for(int i = 1;i <= n;i ++)
{
if(!vis[i])
{
a[now] = i;vis[i] = true;
dfs(now+1);vis[i] = false;
}
}
}
int main()
{
cin>> n;dfs(0);
return 0;
}
回溯
一、什么是回溯算法
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
回溯算法实际上一个类似枚举的深度优先搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回(也就是递归返回),尝试别的路径。
二、递归函数的参数的选择,要遵循四个原则
1、必须要有一个临时变量(可以就直接传递一个字面量或者常量进去)传递不完整的解,因为每一步选择后,暂时还没构成完整的解,这个时候这个选择的不完整解,也要想办法传递给递归函数。也就是,把每次递归的不同情况传递给递归调用的函数。
2、可以有一个全局变量,用来存储完整的每个解,一般是个集合容器(也不一定要有这样一个变量,因为每次符合结束条件,不完整解就是完整解了,直接打印即可)。
3、最重要的一点,一定要在参数设计中,可以得到结束条件。一个选择是可以传递一个量n,也许是数组的长度,也许是数量,等等。
4、要保证递归函数返回后,状态可以恢复到递归前,以此达到真正回溯。
相信大家已经知道了递归树的含义那么,接下来我们来给大家说说回溯的过程。
如果大家仔细观察上面的代码大家可能会疑惑我的搜索的代码中为什么会出现
a[now] = i;
vis[i] = true;
dfs(now+1);
vis[i] = false;
大家可能会疑惑为什么我将vis[i] 设置成为了 true 之后在执行完递归调用后为什么又多了一步又将vis[i] = false,而这看似不起眼的关键的一步就是我们dfs算法中常用的回溯,也叫做恢复现场
其实原来的代码应该本来应该是这样
a[now] = i;
vis[i] = true;
dfs(now+1);
vis[i] = false;
a[now] = 0;
也就是说 我们在进入下一个递归调用之前我们对我们的局部变量或者全局变量进行了某些操作,我们在这个递归嗲用之前我们要保证它恢复至原来的状态
拿我们以上的状态举例
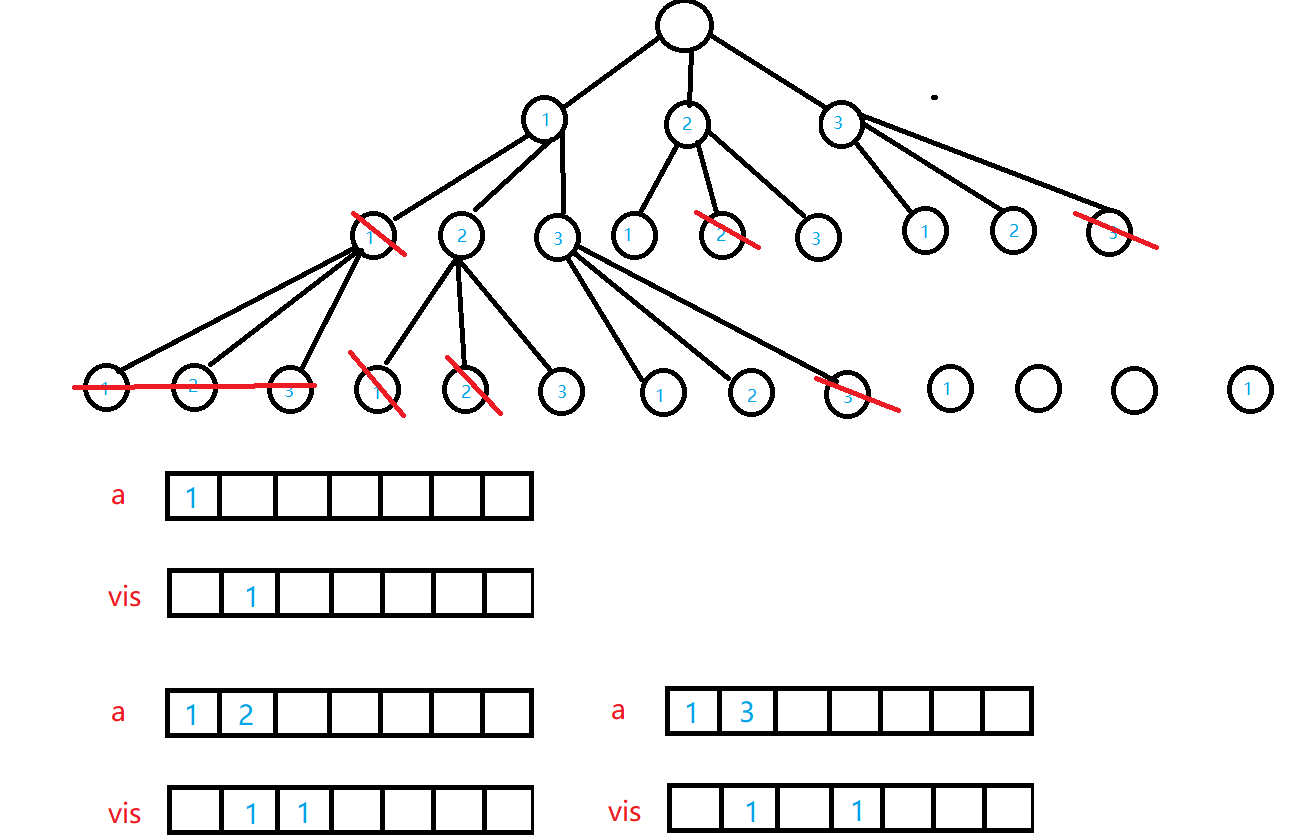
我们从root -> 1的这一个分支看
从1在往下共有两个分支可以走 -->如果我们走了2的话那么势必会对a数组做出改动但是我们3的路径还没走,为了确保我们走了第二个路径的结果对第三个路径的结果不产生影响我们在走完第二个路径分治后密钥将状态恢复为进入2之前的状态,这样才能做到路径之间互不干扰。协同搜索出来所有结果
深度优先搜索(dfs)
掌握了递归树和回溯之后我们就可以来了解深度优先搜索这个概念啦,深度优先搜索大部分时候就是以上两种情况的结合使用(其实回溯就是一个搜索算法)反正本蒟蒻认为以上几种算法大部分时候时候边界模糊,其实dfs就是一个普适的搜索模板所以一定要掌握好。学好搜索你可以解决很多的问题。
深度优先搜索的来源
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。
深度优先搜索框架
下面给出我常用的深度优先搜索算法的模板
void dfs(根据需要传递相应的参数)
{
if(满足条件)退出当前函数
if(剪枝)剪掉该分支
如果以上都不满足就枚举情况进行递归
for(......)
{
状态标记
dfs(...)
状态恢复
}
}
下面从一道题目给大家引入深度优先搜索在图上的应用
题目传送门
我的解法C++
#include <iostream>
using namespace std;
int n, m; //行,列
int t;//障碍总数
int map[6][6];
int zx, zy;//障碍物的坐标
int sx, sy;//起始坐标
int tx, ty;//终点坐标
int step;
int _next[4][2] = { { -1, 0 },{ 0, 1 },{ 0, -1 },{ 1, 0 } };
//判断这个坐标是否在map里
bool inmap(int x, int y)
{
return (x >= 1 && x <= n && y >= 1 && y <= n);
}
void dfs(int x, int y)
{
if (x == tx && y == ty)
{
step++;return;
}
for (int i = 0; i < 4; i++)
{
int nx = x + _next[i][0];
int ny = y + _next[i][1];
if (inmap(nx, ny) == 1 && map[nx][ny] != 1 && map[nx][ny] != 2)
{
map[nx][ny] = 2;
dfs(nx, ny);
map[nx][ny] = 0; // 恢复现场
}
}
}
int main()
{
cin >> n >> m >> t;
cin >> sx >> sy;//输入起始坐标
cin >> tx >> ty;//输入终点坐标
for (int i = 0; i < t; i++)
{
cin >> zx >> zy;
map[zx][zy] = 1;//障碍物设置成一
}
map[sx][sy] = 2;
dfs(sx, sy);
cout << step << endl;
}
我的解法Java
import java.util.Scanner;
public class Main{
static int n , m , t ,zx ,zy,sx,sy,tx,ty,step;
static int map[][] = new int[6][6];
static int dir[][] = { { -1, 0 },{ 0, 1 },{ 0, -1 },{ 1, 0 } };
public static boolean inmap(int x,int y) {
return (x >= 1 && x <= n && y >= 1 && y <= n);
}
public static void dfs(int x,int y) {
if(x == tx && y == ty){
step++;return;
}
for(int i = 0;i < 4 ;i ++) {
int nx = x + dir[i][0];
int ny = y + dir[i][1];
if(inmap(nx,ny) && map[nx][ny] != 1 && map[nx][ny] != 2){
map[nx][ny] = 2;
dfs(nx, ny);
map[nx][ny] = 0;
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();m = sc.nextInt();t = sc.nextInt();
sx = sc.nextInt();sy = sc.nextInt();
tx = sc.nextInt();ty = sc.nextInt();
for(int i = 0;i < t;i ++) {
zx = sc.nextInt();zy = sc.nextInt();
map[zx][zy] = 1;
}
map[sx][sy] = 2;
dfs(sx,sy);
System.out.println(step);
}
}