完美洗牌问题,给定一个数组a1,a2,a3,...an,b1,b2,b3..bn,把它最终设置为b1,a1,b2,a2,...bn,an这样的。
分析:
首先,有的问题要求把它换成a1,b1,a2,b2,...an,bn。其实也差不多。我们可以:
循环n次交换a1,b1,a2,b2, 把数组变为b1,b2...bn,a1,a2...an,时间复杂度O(n),再用完美洗牌问题的算法。
或者 先用完美洗牌算法,再循环n次交换每组相邻的两个元素,也是O(n)。
所以,我们只研究第一行给出的问题。
为方便起见,我们考虑的是一个下标从1开始的数组,下标范围是[1..2n]。 我们看一下每个元素最终去了什么地方。
前n个元素 a1 -> a2 a2->a4.... 第i个元素去了 第(2 * i)的位置。
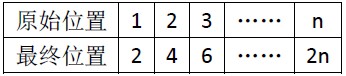
后n个元素a(n + 1)->a1, a(n + 2)->a3... 第i个元素去了第 ((2 * (i - n) ) - 1) = (2 * i - (2 * n + 1)) = (2 * i) % (2 * n + 1) 个位置。

统一一下,任意的第i个元素,我们最终换到了 (2 * i) % (2 * n + 1)的位置,这个取模很神奇,不会产生0。所有最终的位置编号还是从1到2n。
(1) 完美洗牌算法1
于是,如果允许我们再用一个数组的话,我们直接把每个元素放到该放得位置就好了。于是产生了最简单的方法pefect_shuffle1,它的时间复杂度是O(n),空间复杂度也是O(n)。
代码:
// 时间O(n),空间O(n) 数组下标从1开始
void pefect_shuffle1(int *a,int n) {
int n2 = n * 2, i, b[N];
for (i = 1; i <= n2; ++i) {
b[(i * 2) % (n2 + 1)] = a[i];
}
for (i = 1; i <= n2; ++i) {
a[i] = b[i];
}
}
(2) 完美洗牌算法2——分治的力量。
考虑分治法,假设n也是偶数。 我们考虑把数组拆成两半:
我们只写数组的下标:
原始数组(1..2*n)
也就是(1..n)(n + 1.. 2 *n)
前半段长度为n,后半段长度也为n,我们把前半段的后n / 2个元素(n / 2 + 1..n) 与 后半段的前n / 2 个元素 (n + 1..n + n / 2 ) 交换,得到 :
新的前n个元素A : (1..n / 2)(n + 1..n + n / 2 )
新的后n个元素B : (n / 2 + 1.. n) (n + n / 2 + 1..n)
因为n是偶数,我们得到了A,B两个子问题。问题转化为了求解n' = n / 2的两个问题。
当n是奇数怎么办?我们可以把前半段多出来的那个元素先拿出来,后面所有元素前移,再把当时多出的那个元素放到末尾,这样数列最后两个元素已经满足要求了。于是只考虑前2 * (n - 1)个元素就可以了,于是转换成了(n - 1)的问题。
为了说明问题,我们还是用a, b 分别说明一下。假设n = 4是个偶数,我们要做的数列是:
a1, a2,a3,a4,b1,b2,b3,b4

我们先要把前半段的后2个元素(a3,a4)与后半段的前2个元素(b1,b2)交换,得到a1,a2,b1,b2,a3,a4,b3,b4。

于是,我们分别求解子问题A (a1,a2,b1,b2)和子问题B (a3,a4,b3,b4)就可以了。
如果n = 5,是奇数数怎么办?
我们原始的数组是a1,a2,a3,a4,a5,b1,b2,b3,b4,b5

我们先把a5拎出来,后面所有元素前移,再把a5放到最后,变为:
a1,a2,a3,a4,b1,b2,b3,b4,b5,a5

可见这时最后两个元素b5,a5已经是我们要的结果了,所以我们只要考虑n=4就可以了。
那么复杂度怎么算?
每次,我们交换中间的n个元素,需要O(n)的时间,n是奇数的话,我们还需要O(n)的时间先把后两个元素调整好,但这步影响总体时间复杂度。所以,无论如何都是O(n)的时间复杂度。
于是我们有 T(n) = T(n / 2) + O(n) 这个就是跟归并排序一样的复杂度式子,最终复杂度解出来T(n) = O(nlogn)。空间的话,我们就在数组内部折腾的,所以是O(1)。(当然没有考虑递归的栈的空间)
代码:
//时间O(nlogn) 空间O(1) 数组下标从1开始
void perfect_shuffle2(int *a,int n) {
int t,i;
if (n == 1) {
t = a[1];
a[1] = a[2];
a[2] = t;
return;
}
int n2 = n * 2, n3 = n / 2;
if (n % 2 == 1) { //奇数的处理
t = a[n];
for (i = n + 1; i <= n2; ++i) {
a[i - 1] = a[i];
}
a[n2] = t;
--n;
}
//到此n是偶数
for (i = n3 + 1; i <= n; ++i) {
t = a[i];
a[i] = a[i + n3];
a[i + n3] = t;
}
// [1.. n /2]
perfect_shuffle2(a, n3);
perfect_shuffle2(a + n, n3);
}
(3) 完美洗牌算法。
这个算法源自一篇文章,文章很数学,可以只记结论就好了……
这个算法的具体实现还是依赖于算法1,和算法2的。
首先,对于每一个元素,它最终都会到达一个位置,我们如果记录每个元素应到的位置会形成圈。
为什么会形成圈?
比如原来位置为a的元素最终到达b,而b又要达到c……,因为每个新位置和原位置都有一个元素,所以一条链
a->b->c->d……这样下去的话,必然有一个元素会指向a,(因为中间那些位置b,c,d……都已经被其它元素指向了)。
这就是圈的成因。
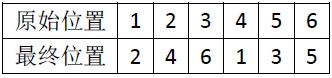
比如 6个元素
原始是(1,2,3,4,5,6), 最终是(4,1,5,2,6,3),我们用a->b表示原来下标为a的元素,新下标为b了。
1->2
2->4
3->6
4->1
5->3
6->5
我们会发现1->2->4->1是个圈,3->6->5->3是另外一个圈。可以表示为(1,2,4) 和(3,6,5),算法1已经告诉我们每个位置i的元素,都变为2 * i % (2 * n + 1),那么我们只要知道圈里的任意一个元素,顺着走一遍就可以了,圈与圈是不相交的,所以这样下来,我们就只走了O(n)步。
我们不能从1开始对每个元素都沿着圈走一圈。这是因为例如上例中(1,2,4)这个圈,我们只能从1,2, 4中的一个开始走一圈,而不能从1走一圈,再从2走一圈,再从4走一圈……因此我们可能还需要O(n)的空间记录哪些元素所在的圈已经处理了,但是这样做的时空复杂度等同于算法1了。、(如果数组元素都是正数,我们可以把处理过的元素标记为负数,最后再取相反数,但是这样做其实也是利用了额外的空间的)。那么我们的关键问题是从每个圈里选择任意一个位置作代表,每个圈从这个位置位置走一圈。而空间复杂度要求我们最好不要提前把每个代表位置存下来。后文一个定理表明,我们在数组长度满足一定条件情况下,每个圈中得最小元素可以简单地表达出来。于是,我们称每个圈的最小的位置叫做圈的头部,用它来作圈的代表位置。如上例中圈(1,2,4)的头部是1,(3,6,5)的头部是3。如果我们知道了一个圈的头部,用它做代表,沿着这个圈走就可以了。沿着圈走得算叫做cycle_leader,这部分代码如下:
//数组下标从1开始,from是圈的头部,mod是要取模的数 mod 应该为 2 * n + 1,时间复杂度O(圈长)
void cycle_leader(int *a,int from, int mod) {
int last = a[from],t,i;
for (i = from * 2 % mod;i != from; i = i * 2 % mod) {
t = a[i];
a[i] = last;
last = t;
}
a[from] = last;
}
那么如何找到每个圈的头部呢?引用一篇论文,名字叫:
A Simple In-Place Algorithm for In-Shuffle.
Peiyush Jain, Microsoft Corporation.
利用数论知识,包括原根、甚至群论什么的,论文给出了一个出色结论(*):
对于2 * n = (3^k - 1),这种长度的数组,恰好只有k个圈,并且每个圈的头部是1,3,9,...3^(k - 1)。
这样我们就解决了这种特殊的n作为长度的问题。那么,对于任意的n怎么办?我们利用算法2的思路,把它拆成两部分,前一部分是满足结论(*)。后一部分再单独算。
为了把数组分成适当的两部分,我们同样需要交换一些元素,但这时交换的元素个数不相等,不能简单地循环交换,我们需要更强大的工具——循环移。
假设满足结论(*)的需要的长度是2 * m = (3^k - 1), 我们需要把n分解成m和n - m两部分,按下标来说,是这样:
原先的数组(1..m) (m + 1.. n) (n + 1..n + m)(n + m + 1..2 * n)
我们要达到的数组 (1..m)(n + 1.. n + m)(m + 1..n)(n + m + 1..2 * n)
可见,中间那两段长度为(n - m)和m的段需要交换位置,这个相当于把(m + 1..n + m)的段循环右移m次,而循环右移是有O(长度)的算法的, 主要思想是把前(n - m)个元素和后m个元素都翻转一下,再把整个段翻转一下。
循环移位的代码:
//翻转字符串时间复杂度O(to - from)
void reverse(int *a,int from,int to) {
int t;
for (; from < to; ++from, --to) {
t = a[from];
a[from] = a[to];
a[to] = t;
}
}
//循环右移num位 时间复杂度O(n)
void right_rotate(int *a,int num,int n) {
reverse(a, 1, n - num);
reverse(a, n - num + 1,n);
reverse(a, 1, n);
}
再用a和b举例一下,设n = 7这样m = 4, k = 2
原先的数组是a1,a2,a3,a4,(a5,a6,a7),(b1,b2,b3,b4),b5,b6,b7。
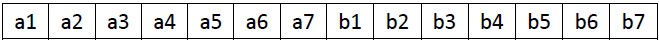
结论(*)是说m = 4的部分可以直接搞定,
也就是说我们把中间加括号的那两段(a5,a6,a7) (b1,b2,b3,b4)交换位置,也就是把(a5,a6,a7,b1,b2,b3,b4)整体循环右移4位就可以得到:
(a1,a2,a3,a4,b1,b2,b3,b4)(a5,a6,a7,b5,b6,b7)

于是前m = 4个由算法cycle_leading算法直接搞定,n的长度减小了4。
所以这也是一种分治算法。算法流程:
输入数组 a[1..2 * n]
step 1 找到 2 * m = 3^k - 1 使得 3^k <= 2 * n < 3^(k +1)
step 2 把a[m + 1..n + m]那部分循环移m位
step 3 对每个i = 0,1,2..k - 1,3^i是个圈的头部,做cycle_leader算法,数组长度为m,所以对2 * m + 1取模。
step 4 对数组的后面部分a[2 * m + 1.. 2 * n]继续使用本算法,这相当于n减小了m。
时间复杂度分析:
(1) 因为循环不断乘3的,所以时间复杂度O(logn)
(2) 循环移位O(n)
(3) 每个圈,每个元素只走了一次,一共2*m个元素,所以复杂度omega(m), 而m < n,所以 也在O(n)内。
(4) T(n - m)
因此 复杂度为 T(n) = T(n - m) + O(n) m = omega(n) 解得:总复杂度T(n) = O(n)。
算法代码:
//时间O(n),空间O(1)
void perfect_shuffle3(int *a,int n) {
int n2, m, i, k,t;
for (;n > 1;) {
// step 1
n2 = n * 2;
for (k = 0, m = 1; n2 / m >= 3; ++k, m *= 3)
;
m /= 2;
// 2m = 3^k - 1 , 3^k <= 2n < 3^(k + 1)
// step 2
right_rotate(a + m, m, n);
// step 3
for (i = 0, t = 1; i < k; ++i, t *= 3) {
cycle_leader(a , t, m * 2 + 1);
}
//step 4
a += m * 2;
n -= m;
}
// n = 1
t = a[1];
a[1] = a[2];
a[2] = t;
}