1.Hive的数据库操作
Hive中数据库的概念本质上仅仅是表的一个目录或者命名空间;然而,对于具有很多组和用户的大集群来说,这是非常有用的,因为这样可以避免表命名冲突;
如果用户没有使用use关键字显示指定数据库,那么将会使用默认的数据库default;
1.1 查看数据库
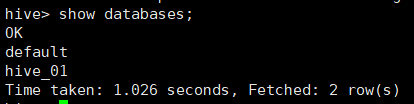
show databases;
使用like关键字实现模糊匹配;
show databases like 'hive_*';

1.2 使用数据库
use 数据库名称;
1.3 创建数据库
create database 数据库名称;
1.4 删除数据库
下面删除,需要将对应数据库中的表全部删除后才能删除数据库;
drop database 数据库名称;
下面删除,是强制删除,自行删除所有表;
drop database 数据库名称 cascade;
1.5 查看数据库的详细描述
desc database hive_01;

2.Hive的数据表操作
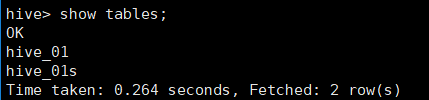
2.1 显示数据库中的表
show tables;

使用like关键字实现模糊匹配;
show tables like 'hive_*';

2.2 显示表的详细信息
desc hive_01;

2.3 创建数据表
create [external] table [if not exists] table_name
[(col_name data_type [comment col_comment], ...)] 声明列
[comment table_comment] 声明表注释
[partitioned by (col_name data_type [comment col_comment], ...)]
[clustered by (col_name, col_name, ...)
[sorted by (col_name [asc|desc], ...)] into num_buckets buckets]
[row format row_format] 声明行的切分
[stored AS file_format] #设置hive表的存储的格式
Textfile orcfile sequenceFile
[location hdfs_path] 构建hive的外部表
上述字段解释说明
create table:创建一个指定名字的表,如果相同名字的表已经存在,则抛出异常;用于可以使用IF NOT EXISTS来规避这个异常;
external:关键字可以让用户创建一个外部表,在建表的同时执行一个指向实际数据的路径;
comment:为表和列添加注释;
partitioned by:创建分区表;
clustered by:创建分桶表;
sorted by:排序;
row format:目前仅仅支持单个字符作为修饰符;
stored as:指定存储文件类型;
location:指定在HDFS上的存储位置;
like:允许用户复制表的结构,但不复制数据;
2.4 查询建表法
通过AS查询语句完成建表:将子查询的结果存在新表里,有数据;
create table 表名 as select 查询语句;
2.5 like建表法
会创建结构完全相同的表,但是没有数据;
create table hive_01s like hive_01;
2.6 删除表
drop table hive_01s;

3.Hive内部表&&外部表
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
(1)内部表数据由hive管理,外部表数据由HDFS管理;
(2)内部表的数据的存储位置时hive.metastore.warehouse.dir,默认为/user/hive/warehousr中,外部表的数据存储位置由自己指定;
(3)删除内部表中的数据会直接删除元数据及存储数据;删除外部表仅仅会删除元数据,HDFS上的数据并不会被删除,metadata同上;
(4)对内部表的修改会将修改直接同步给元数据;而对外部表的表结构和分区进行修改,则需要MSCK REPAIR TABLE table_name(将HDFS上的元数据信息写入到metastore);
3.1 测试
3.1.1 首先创建内部表:
create table t1(id int,name String,hobby array<String>,add map<String,String>)row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':';
3.1.2 查看表的详情:
desc t1;

3.1.3 使用load语句向t1表中装载数据:

1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
将数据上传到hive上:
load data local inpath '/opt/module/hive/data/t1' overwrite into table t1;
3.1.4 查看表数据:
select * from t1;

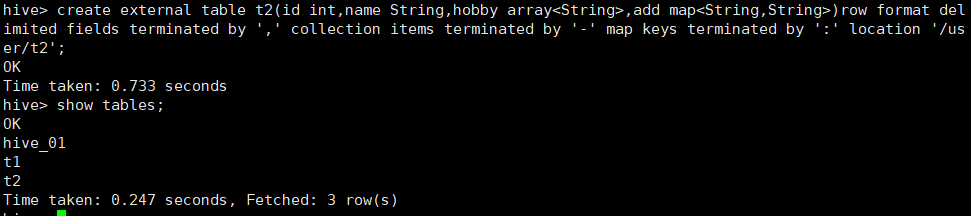
3.1.5 创建外部表:
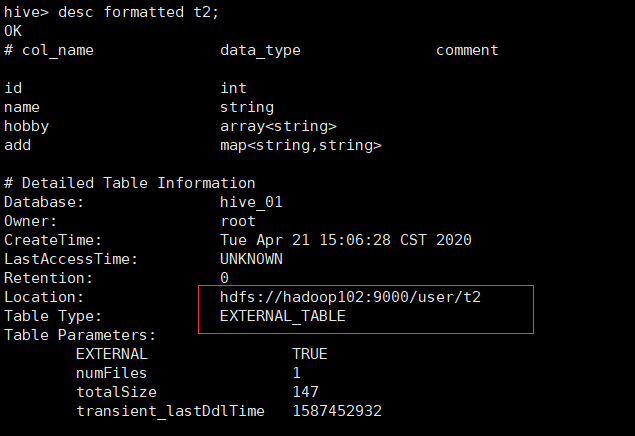
create external table t2(id int,name String,hobby array<String>,add map<String,String>)row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' location '/user/t2';
3.1.6 load装载数据:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
load data local inpath '/opt/module/hive/data/t2' overwrite into table t2;
3.1.7 查看表数据:
select * from t2;

3.1.8 打开HDFS查看对应内容:
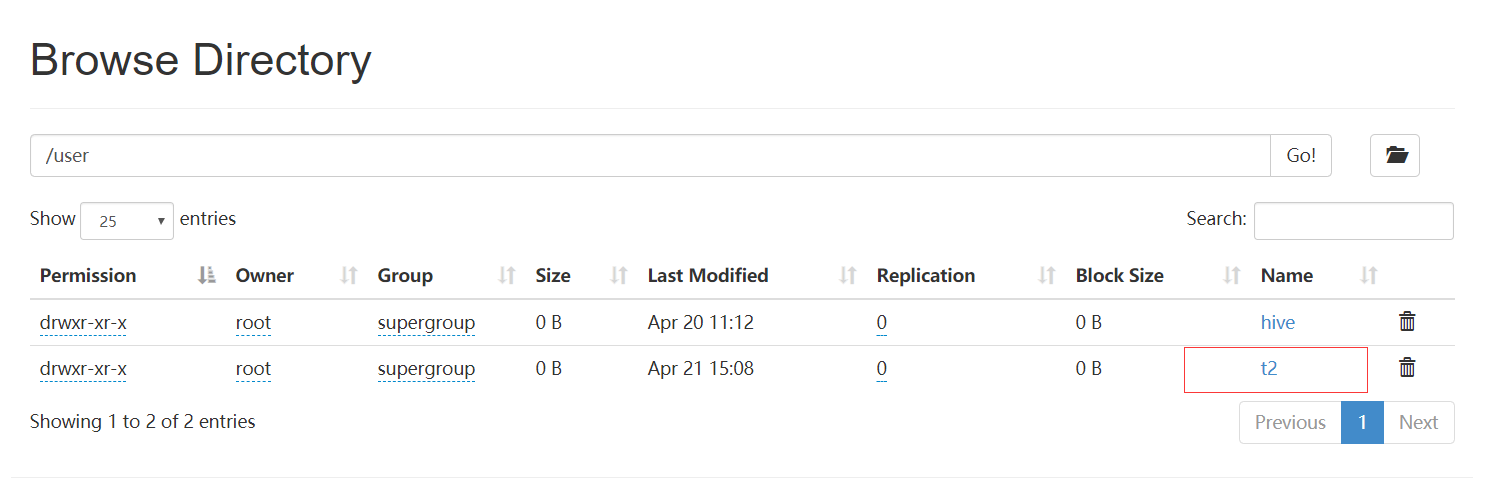
3.1.9 可以通过命令行获取两者的位置信息:
desc formatted t1;
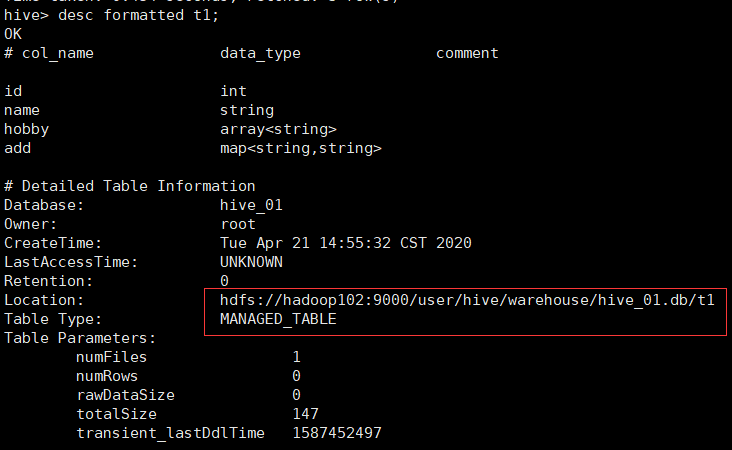
desc formatted t2;