Jmeter的使用
下载与安装
- 官网下载最新的的版本,解压即可使用。
- 前提安装jdk
- jmeter解压目录bin添加到环境变量。
- 检查jmeter安装 jmeter或jmeterw
jmeter详细介绍
jmeter支持哪些测试场景
- Web - HTTP, HTTPS (Java, NodeJS, PHP, ASP.NET, …)
- SOAP / REST Webservices
- FTP
- 通过JDBC连接数据库(支持各种数据库)
- LDAP
- 通过JMS的面向消息的中间件(MOM)
- 邮箱协议 - SMTP(S), POP3(S) and IMAP(S)
- 本机命令或Shell脚本
- TCP
- Java Objects
jmeter实际使用场景
- 接口测试
- 压力测试
- 分布式压力测试
- 测试Restful风格的API
jmeter安装目录说明
基本目录说明
| 文件夹 |
作用 |
| bin |
包含启动、配置等相关命令自己写的脚本默认另存为该目录下 |
| docs |
官方接口文档,二次开发需要了解的一些接口 |
| extras |
辅助库,持续集成会用到(后面讲) |
| lib |
存放各种 Jmeter 核心库的源码 jar 包存放自己二次开发的 jar包 |
| libext |
官方提供的第三方插件 |
| license |
包含 non-ASF 软件的许可证 |
| printable_docs |
离线的帮助文档,可以查看函数等内容 |
| LICENSE |
JMeter 许可说明 |
| NOTICE |
JMeter 简单信息说明 |
| README.md |
JMeter 官方基本介绍 |
重点bin目录
| 文件 |
作用 |
| jmeter.properties |
JMeter 核心配置文件,各种配置基本在这完成 |
| log4j.conf |
JMeter 日志配置管理 |
| jmeter.log |
JMeter 运行日志记录,什么输出信息、警告、报错都在这里进行了记录 |
| jmeter.bat |
windows 下 jmeter 的启动文件,带cmd窗口 |
| jmeterw.cmd |
windows 下 jmeter 的启动文件,不带cmd窗口 |
| shutdown.cmd |
windows 下 jmeter 的关闭文件 |
| stoptest.cmd |
windows 下 jmeter 停止测试的文件 |
| jmeter-server.bat |
windows 下 jmeter 服务器模式的启动文件 |
| jmeter-server |
mac 或者 Liunx 分布式压测使用的启动文件 |
jmeter.properties配置
jmeter的核心配置项文件,官方建议将需要修改的属性值,复制粘贴到同目录下的user.properties,可以避免修改项需要重新应用.
默认语言设置
- language=en:默认英文
- language=zh_CN:默认中文
配置默认编码格式
- sampleresult.default.encoding=ISO-8859-1:默认ISO-8859-1
- sampleresult.default.encoding=UTF-8:可以改成常用的UTF-8
输出测试报告模板格式
jmeter.save.saveservice.output_format=csv
捕捉cookie
Cookies应该存储为变量
- CookieManager.save.cookies=false:默认
- CookieManager.save.cookies=true:将cookie存储为变量
快捷方式
- gui.quick_0=ThreadGroupGui(添加线程组)
- gui.quick_1=HttpTestSampleGui(添加HTTP请求)
- gui.quick_2=RegexExtractorGui(添加正则表达式提取器)
- gui.quick_3=AssertionGui(添加响应断言)
- gui.quick_4=ConstantTimerGui(添加固定定时器)
- gui.quick_5=TestActionGui(添加测试活动)
- gui.quick_6=JSR223PostProcessor(添加JSR223后置处理程序)
- gui.quick_7=JSR223PreProcessor(添加JSR223预处理程序)
- gui.quick_8=DebugSampler(添加调试取样器)
- gui.quick_9=ViewResultsFullVisualizer(添加查看结果树)
默认添加Content-Type
在5.0之前默认是true
- post_add_content_type_if_missing=false:默认
- post_add_content_type_if_missing=true:添加Content-Type: application/x-www-form-urlencoded
配置远程主机host
remote_hosts=127.0.0.1
测试计划面板参数详解
- 用户定义的变量
- 这里用户添加的变量,相当于全局变量,所有线程组都共用
- 一般添加一些系统常用的配置
- 般不建议在测试计划上添加变量,因为不方便启用(disable)和禁用(enable)
- 可以添加用户自定义变量组件来代替
- 独立运行每个线程组(例如在一个组运行结束后启动下一个)
- 默认:不勾选,默认各线程组并行、随机执行
- 作用:勾选后,用于控制测试计划中的多个线程组的执行顺序,保证顺序执行各线程组(注意:相关控制器是可以改变顺序的)
- 添加jar包 当BeanShell脚本需要调用外部的java文件或jar包时,可以把jar包路径添加到这里,然后在BeanShell中直接import进来,并调用jar包中的方法
基础线程组Thread Group
定义
- 线程组是一个测试计划的开始点
- 在一个测试计划中的所有元件都必须在某个线程组下
- 线程组决定 Jmeter 执行测试计划的线程数
作用
- 设置线程数
- Jmeter java进程下启动的线程,用来模拟真实用户数,1线程数 = 1用户数
- windows下,2g的 java内存,1m 的栈空间,最大启动线程数=1000
- Linux下,2g的 java内存,1m 的栈空间,最大启动线程数=2000
- 在Jmeter中,先启动线程,再运行线程,后释放线程【启动线程并运行,释放线程】
- 线程数建议不超过1000
- 设置ramp-up period(代表隔多长时间执行,0表示同时并发,设置100且线程数为10,表示隔10秒执行一次)
- 预期线程组的所有线程从启动-运行-释放的总时间
- ramp up=0时,表示瞬时加压,启动线程的时间无限趋近于0
- 特别注意:在负载测试的时候,尽量把ramp up设置大一些,让性能曲线平缓,容易找到瓶颈点
- 设置执行测试的次数
- 每个线程循环执行的次数,默认一次【便于理解:线程的迭代次数、重复发起请求的次数】
- 如果设置为永远,那么 jmeter 将以最大的可能去发送请求,以此测试出最大并发数
- 调度器Specify Thread Lifetime
控制每个线程组运行的持续时间以及它在多少秒后再启动
- Duration (seconds) :持续时间;线程组运行的持续时间
- Startup Delay (seconds):启动延迟;测试计划开始后,线程组的线程将在多少秒后再启动运行
注意事项
- Ramp-up需要设置足够长的时间来避免在测试刚开始时工作量过大
- Ramp-up还必须足够短,保证最后一个线程在第一个线程完成之前开始运行
- 确定Ramp-up时间
- 首先让初始点击率接近平均点击率,前提是确定合理的访问量
- 初始的 ramp-up period = 平均点击率= 总线程/点击率;假如线程数=100,点击率=10次/s,则ramp-up period = 100/10 = 10s
- 循环次数有固定值且 ≠ -1,持续时间不会生效,以循环次数为准,循环次数设置为永远或 -1 时,持续时间才会生效
- 线程组下不同组件的执行优先级
- 配置元件、监听器
- 前置处理器
- 定时器
- 逻辑控制器
- 取样器
- 后置处理器
- 断言
- 在没有逻辑控制器情况下,取样器是按从上往下的顺序执行的
阶梯加压线程组Stepping Thread Group
特性
- 有预览图显示估计的负载
- 可延迟启动线程组
- 可持续增加线程负载
- 可设置最大负载的持续运行时间
作用
- 减少服务器的瞬时压力,做性能测试应该逐步增加压力,而不是瞬时加压
- 逐步增压越平缓越好,更容易从结果看到多少压力值下,有性能瓶颈
参数详解
- this group will start:表示总共要启动的线程数;若设置为 100,表示总共会加载到 100 个线程
- first,wait for:从运行之后多长时间开始启动线程;若设置为 0 秒,表示运行之后立即启动线程
- then start:初次启动多少个线程;若设置为 0 个,表示初次不启动线程
- next add:之后每次启动多少个线程;若设置为 10个,表示每个梯次启动 10 个线程
- threads every:当前运行多长时间后再次启动线程,即每一次线程启动完成之后的持续时间;若设置为 30 秒,每梯次启动完线程之后再运行 30 秒
- using ramp-up:启动线程的时间;若设置为 5 秒,表示每次启动线程都持续 5 秒(和基础线程组的ramp-up一样意思)
- then hold load for:线程全部启动完之后持续运行多长时间,如图:设置为 60 秒,表示 100 个线程全部启动完之后再持续运行 60 秒
- finally,stop/threads every:多长时间释放多少个线程;若设置为 5 个和 1 秒,表示持续负载结束之后每 1 秒钟释放 5 个线程
- 实际案例(this group will start设置100,first,wait for设置0,then start设置0,next add设置10,threads every设置30,using ramp-up设置5,then hold load for设置60,finally,stop/threads every设置5和1)
- 从第0秒开始启动线程,每 5 秒内启动10个线程并且运行30秒,以此循环,直到一共启动了 100 个线程
- 当已启动 100 个线程后,持续负载运行60秒
- 持续负载运行60秒后,每 1 秒释放五个线程,直到全部线程被释放
- 结合Active Threads Over Time
- 运行Stepping Thread Group需要和Active Threads Over Time结合起来使用,这样能看到动态的阶梯加压效果
- 可以看到和Stepping Thread Group负载预览图基本一致,证明加压效果是正常的
并发式线程组Concurrency Thread Group
跟Stepping Thread Group一样,可以结合Active Threads Over Time使用.
介绍
- Concurrency Thread Group提供了用于配置多个线程计划的简化方法
- 该线程组目的是为了保持并发水平,意味着如果并发线程不够,则在运行线程中启动额外的线程
- 和Standard Thread Group不同,它不会预先创建所有线程,因此不会使用额外的内存
- 对于上篇讲到的Stepping Thread Group来说,Concurrency Thread Group是个更好的选择,因为它允许线程优雅地完成其工作
- Concurrency Thread Group提供了更好的用户行为模拟,因为它使您可以更轻松地控制测试的时间,并创建替换线程以防线程在过程中完成
参数详解
- Target Concurrency:目标并发(线程数)
- Ramp Up Time:启动时间;若设置 1 min,则目标线程在1 imn内全部启动
- Ramp-Up Steps Count:阶梯次数;若设置 6 ,则目标线程在 1min 内分六次阶梯加压(启动线程);每次启动的线程数 = 目标线程数 / 阶梯次数 = 60 / 6 = 10
- Hold Target Rate Time:持续负载运行时间;若设置 6 ,则启动完所有线程后,持续负载运行 2 min,然后再结束
- Time Unit:时间单位(分钟或者秒)
- Thread Iterations Limit:线程迭代次数限制(循环次数);默认为空,理解成永远,如果运行时间到达Ramp Up Time + Hold Target Rate Time,则停止运行线程【不建议设置该值】
- Log Threads Status into File:将线程状态记录到文件中(将线程启动和线程停止事件保存为日志文件);
注意点
- Target Concurrency只是个期望值,实际不一定可以达到这个并发数,得看上面的配置【电脑性能、网络、内存、CPU等因素都会影响最终并发线程数】
- Jmeter会根据Target Concurrency的值和当前处于活动状态的线程数来判断当前并发线程数是否达到了Target Concurrency;若没有,则会不断启动线程,尽力让并发线程数达到Target Concurrency的值
对比
- 与Stepping Thread Group
- Stepping Thread Group 是手动场景:测试过程,按照设定好的步骤执行
- Concurrency Thread Group 是目标场景:达到某个目标运行场景,测试过程不可控,动态变化
- 对比LR
- Stepping Thread Group :设置并发用户数,持续时间等,每隔多少时间自动增加多少个用户
- Concurrency Thread Group:预设一个目标并发数,每隔一段时间增加一部分并发数,直到 TPS 达到目标并发数,然后持续运行一段时间
取样器http请求 HTTP Request
面板详解
| 字段名 |
作用 |
| 名称 |
不多介绍啦,建议自定义一个识别度高的名称 |
| 注释 |
对于测试没有任何影响,仅记录作用 |
| 协议 |
http或https,大小写不敏感,默认:http |
| 服务器名称或IP |
服务器 host 或者 ip,不包括协议比如:www.baidu.com、192.168.196.128 |
| 端口号 |
目标服务器的端口号,默认:80 |
| 方法 |
发送 http 请求的方法 |
| 路径 |
目标请求的 URL 路径不包括协议、host、ip、端口 |
| 内容编码 |
请求的编码方式,默认:iso8859 |
| 自动重定向 |
发出的请求的响应码是3**,会自动跳转到新目标页面只记录最终页面的返回结果 |
| 跟随重定向 |
和自动重定向唯一不同的是:会记录重定向过程中的的所有请求的响应结果 |
| 使用 KeepAlive |
jmeter 和目标服务器之间使用 Keep-Alive 方式进行 HTTP 通信真正做性能测试强烈建议不勾选 |
| 对POST使用multipart/form-data |
post 请求需要上传文件时勾选 |
| 与浏览器兼容的头 |
当勾选 multipart/form-data 时,勾选此项http请求头中的 Content-Type 和Content-Transfer-Encoding 被忽略而只发送 Content-Disposition 部分 |
参数Parameters
| 字段 |
描述 |
| Name |
参数名 |
| Value |
参数值 |
| URL Encode? |
是否要 URL 编码?重点:如果参数值包含了中文、特殊字符(非数字字母以外),最好勾上,当然全都勾上最稳妥 |
| Content-Type |
参数值的资源类型默认:text/plain |
| Include Equals? |
当你的参数值为空的时候,可以选择不包含=,默认勾选如果参数值不为空,则不可以取消勾选 |
消息体数据 Body Data
- 传 json 字符串就行
- 重点:如果 Parameters 有参数列表的话,是无法切换到 Body Data
文件上传 Files Upload
基本参数
| 字段 |
描述 |
| File Path |
文件的本地路径 |
| Parameter Name |
参数名 |
| MIME Type |
资源媒体类型 |
常见资源媒体类型
| 类型 |
文件后缀 |
格式 |
| 超文本标记语言文本 |
.html |
text/html |
| 普通文本 |
.txt |
text/plain |
| XML 文件 |
.xml |
text/xml |
| PNG 图片 |
.png |
image/png |
| GIF |
.gif |
image/gif |
| JPEG 图片 |
.jpeg、jpg |
image/jpeg |
| 表单中进行文件上传 |
|
multipart/form-data |
| 表单默认提交数据的格式 |
|
application/x-www-form-urlencoded |
| XML 数据格式 |
|
application/xml |
| JSON 数据格式 |
|
application/json |
| PDF 文件 |
.pdf |
application/pdf |
| RTF 文本 |
.rtf |
application/rtf |
| GZIP 文件 |
.gz |
application/x-gzip |
| TAR 文件 |
.tar |
application/x-tar |
| AVI 文件 |
.avi |
video/x-msvideo |
| MPEG 文件 |
.mpg、.mpeg |
video/mpeg |
不同content-type在jmeter中如何输入参数
- 表单提交最常见的例子,Parameters方式传参
- 最终表单的参数列表会拼接到URL中,所以如果包含了中文、特殊字符就要勾选编码
- 这里不可以通过Body Data传递参数哦,会无法识别到参数,已实践过(即使加了 HTTP请求头也不行)
content-type:application/json
- Body Data 方式传参
- 需要添加content-type:application/json
content-type:multipart/form-data
- 重点:用于 post 请求,需要文件上传的场景;记住不是 get 请求
- 如果添加了 HTTP请求头,请务必不要添加 content-type : multipart/form-data
- 如果加了的话:那么所有的请求参数都会被当成文件以二进制形式传输,我们 parameters 里的文本格式参数就不会被识别,接口会提示参数为空
HTTP请求默认值
面板解释
- HTTP 请求默认值可以直接添加到线程组下面,也可以添加到某个 HTTP 请求下面
- 如果是在线程组下的 HTTP 请求默认值,那么它的作用域就是该线程组下的所有 HTTP 请求,包括子级、孙子级、孙孙子级的 HTTP 请求
- 如果实在某个 HTTP 请求下的 HTTP 请求默认值,那么它的作用域就只针对这个 HTTP 请求
- 线程组的 HTTP 请求默认值的优先级小于HTTP 请求下的 HTTP请求默认值
- 所有 HTTP 请求默认值的优先级都比 HTTP 请求低
总结
HTTP 请求所需的各种字段值(host、端口、编码、请求数据等等),取值的顺序(优先级)是:
- HTTP 请求本身设置的值
- HTTP 请求下的 HTTP 请求默认值设置的值
- 线程组下的 HTTP 请求默认值设置的值
HTTP信息头管理器
面板解释
- 如果信息头管理器放到线程组下,那么线程组下所有 HTTP 请求都会共享这些 HTTP 信息头
- 如果信息头管理器放到 HTTP 请求下,那么只有该请求拥有这些 HTTP 信息头
- 这里和 HTTP 请求默认值一样,也有优先级的,而且优先级也一样
- 如果有多个信息头管理器,名称重名的话,会按优先级高的先取
总结
- HTTP 请求下的信息头管理器的优先级高于线程组下的信息头管理器
- 若有重名的信息头名称,则优先取 HTTP 请求下的信息头管理器
用户自定义变量
- 线程组下的用户自定义变量 优先级高于 测试计划里的用户自定义变量
- HTTP 请求下的用户自定义变量 优先级高于 线程组下的用户自定义变量
- 若有重名变量,优先取优先级高的用户自定义变量
- 用户自定义变量在测试计划运行后,是全局生效的且只生成一次,它不是动态生成的;从测试结果可以看到,即使变量的值是随机数(Random),不同用户数循环多次,拿到的用户自定义变量值都是一样的
用户参数
- 线程组下的用户参数 优先级高于 测试计划里的用户自定义变量
- HTTP 请求下的用户参数 优先级高于 线程组下的用户参数
- 若有重名参数,优先取优先级高的用户参数
- 若用户参数和用户自定义变量重名,则优先取用户参数的值;因为配置元件执行完再到前置处理器,所以前置处理器的值会覆盖配置元件的值
- 10个请求的响应内容都是不同;因为每次发送一次 HTTP 请求,都会调用一次用户参数,所以它的值是动态生成的
JSON提取器
功能
- JSON 是目前大多数接口响应内容的数据格式
- 在接口测试中,不同接口之间可能会有数据依赖,在 Jmeter 中可以通过后置处理器来提取接口的响应内容
- JSON 提取器是其中一个可以用来提取响应内容的元件
JSON 提取器的应用场景
- 提取某个特定的值
- 提取多个值
- 按条件取值
- 提取值组成的列表
界面解释
| 字段 |
结果 |
| Apply to |
应用范围,选默认的 main sample only 就行了 |
| Names of created variables |
接收提取值的变量名;多个变量用 ; 分隔 必传 |
| JSON Path expression |
json path 表达式,用来提取某个值 多个表达式用 ; 分隔 必传 |
| Match No.(0 for Random) |
取第几个值,多个值用 ; 分隔 0:随机,默认 -1:所有 1:第一个值 非必传 |
| Compute concatenation var(suffix_ALL) |
如果匹配到多个值,则将它们都连接起来,不同值之间用 , 分隔 变量会自动命名为<variable name>_ALL |
| Default Values |
缺省值,匹配不到值的时候取该值,可写error 多个值用 ; 分隔 非必传 |
值提取与值使用
- 提取某个特定值的方式有两种:绝对路径、相对路径
- 提其他接口可以通过
${var} 这种格式,来获取提取到的值
提取值
{
"ret": 200,
"msg": "V2.5.1 YesApi App.User.GetList",
"data": {
"total": 3,
"err_msg": "",
"err_code": 0,
"users": [
{
"role": "user",
"status_desc": "正常",
"reg_time": "2020-06-22 15:19:51",
"role_desc": "普通会员",
"ext_info": {
"yesapi_nickname": "",
"yesapi_points": 0
},
"uuid": "6D5EDCB459F0917A98106E07D5438C58",
"username": "fangjieyaossb",
"status": 0
},
{
"role": "user",
"status_desc": "正常",
"reg_time": "2020-06-22 14:27:17",
"role_desc": "普通会员",
"ext_info": {
"yesapi_nickname": "",
"yesapi_points": 0
},
"uuid": "0164DC0680F84DCE40D3DD4A36640ECA",
"username": "fangjieyaossa",
"status": 0
},
{
"role": "admin",
"status_desc": "正常",
"reg_time": "2020-03-23 22:48:32",
"role_desc": "管理员",
"ext_info": {
"yesapi_nickname": "",
"yesapi_points": 0
},
"uuid": "079BF6BB82AFCFC7084F96AECAF0519F",
"username": "fangjieyaoss",
"status": 0
}
]
}
}
提取单个值
| Jsonpath |
结果 |
| $.data.total |
3 |
| $..total |
3 |
| $..users[0].role |
user |
| $..uuid |
079BF6BB82AFCFC7084F96AECAF0519F |
| $.data.users[0].ext_info.yesapi_points |
0 |
利用切片提取单个值
| Jsonpath |
结果 |
| $..users[2] |
第三个 users |
| $..users[-2] |
倒数第二个users |
| $..users[0,1] |
前面两个users |
| $..users[:2] |
第一、二个users |
| $..users[1:2] |
第二个users |
| $..users[-2:] |
倒数两个users |
| $..users[1:] |
第二个开始的所有users |
提取多个值
| jsonpath |
解释 |
备注 |
| $.data.users[*].role |
提取所有 role 字段值 |
[*] 表示取数组的所有元素 |
| $..users..role_desc |
提取所有 role_desc 字段值 |
|
| $..reg_time |
提取所有 reg_time 字段值 |
|
| $..[*].username |
提取所有 username 字段值 |
|
按条件提取值
| Jsonpath |
结果 |
| $..users[?(@.uuid)] |
提取 users 里面包含 uuid 字段的记录 |
| $..users[?(@.reg_time > '2020-06-01')] |
提取 reg_time 字段大于 2020-06-01 的记录 |
| $..users[?(@.role_desc =~ /.会员.?/i)] |
提取 role_desc 字段包含会员的记录 |
| $..users[?(@.status == 0)] |
提取 status 字段等于 0 的记录 |
注意点
- 如果有多个 Jsonpath 的时候,每个字段都必填值,且字段值的数量要一,多个字段以分号隔开
- 勾不勾 Compute concatenation var 都行
- 字段值数量不一致则无法提取值
正则提取器
- JSON 提取器只针对接口返回的响应内容
- 如果想提取的是响应头、请求头的值,而非响应内容的值呢?
- 这个时候正则提取器的作用就出来了,它可以提取请求任一部分的值
面板解释
| 字段 |
含义 |
| Apply to |
应用范围,选默认的 main sample only 就行了 |
| Field to check |
可提取的字段 |
| Names of created variables |
接收提取值的变量名必传 |
| Regular Expression |
正则表达式 |
| Template |
从找到的匹配项中创建字符串的模板 |
| Match No.(0 for Random) |
取第几个值0:随机,默认-1:所有1:第一个值非必传 |
| Default Value |
缺省值,匹配不到值的时候取该值非必传 |
| Use empty default value |
勾选后,提取不到值时,则返回空字符串 |
Template
- 如果一条正则表达式有多个提取结果,则提取结果是数组形式
- 模板 (1)、(2).....表示把解析到的第几个值赋给变量,从 1 开始匹配
- (0) 表示整个表达式匹配的内容
- 若只有一个结果,只能是(1)
Field to check
| 属性 |
含义 |
| Body |
响应体,不包括响应头;最常用 |
| Body (unescaped) |
响应体,替换了所有HTML转义符;不建议使用 |
| Body as a Document |
从不同类型的文件中提取文本;影响性能 |
| Request Headers |
请求头 |
| Response Headers |
响应头 |
| URL |
URL |
| Response Code |
响应码 |
| Response Message |
响应信息 |
提取值
- 提取 "token":"(.*?)"
- 提取他接口可以通过 ${var} 这种格式,来获取提取到的值
- ( ) 里面写匹配规则,用于解析正则表达式
- .*? 表示匹配任意长度的任意字符,这也是最常用的正则表达式
- 一般 (.+?) 和 (.*?) 能够满足我们 80%的使用场景
多个()总结
- 如果其中一个 ( ) 匹配不到元素,那也无法获取到值
- 引用名称、匹配数字、缺省值三个字段也只需要填一个值即可,不需要跟 ( ) 的数量一致
- 多个模板(
$1$,$2$)的时候,可以用空格、, 、. 、 - 连接模板,最终会显示在变量上,如:info4
JDBC Connection Configuration
发起 jdbc 请求前,需要有 JDBC 连接配置,即先连上数据库,才能查询数据库
面板解释
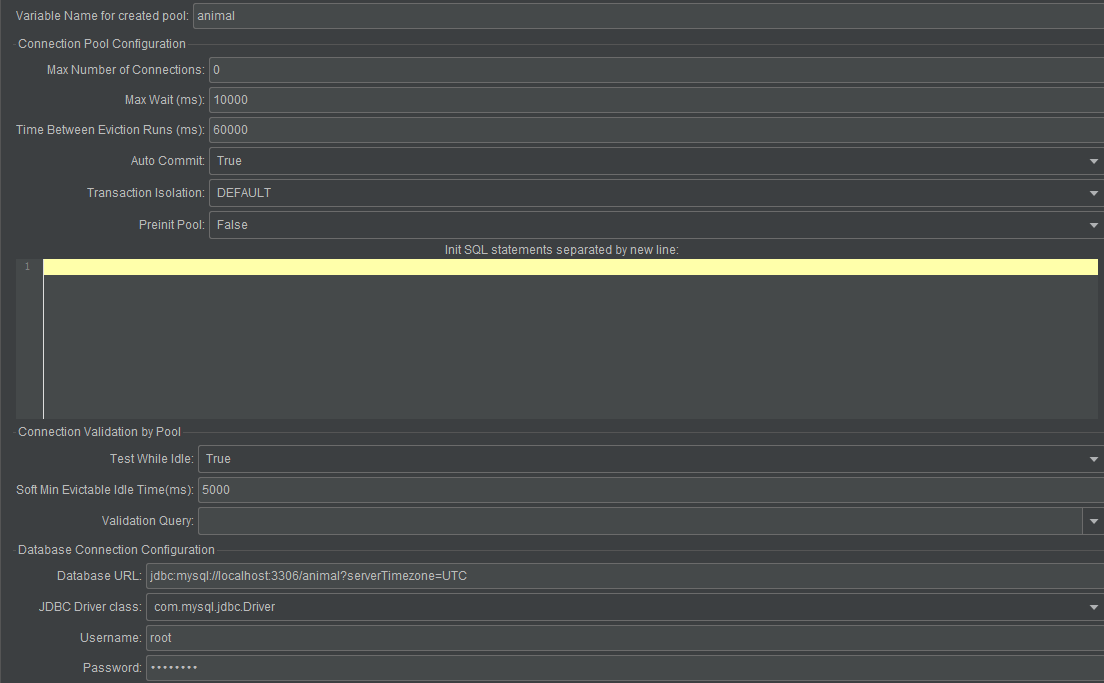
Variable Name for created pool
- JDBC Connection Configuration 算是一个数据库连接池配置
- Variable Name :数据库连接池的名称
- 一个测试计划可以有多个 JDBC Connection,只要名称不重复就行
Connection pool Configuration
连接池参数配置,基本保持默认就行了
| 字段 |
含义 |
| Max Number of Connections |
最大连接数;做性能测试时,建议填 0如果填了10,则最大连接10个线程 |
| Max Wait(ms) |
在连接池中取回连接最大等待时间,单位毫秒 |
| Time Between Eviction Runs(ms) |
线程可空闲时间,单位毫秒如果当前连接池中某个连接在空闲了 time Between Eviction Runs Millis 时间后任然没有使用,则被物理性的关闭掉 |
| Auto Commit |
自动提交sql语句,如:修改数据库时,自动 commit |
| Transaction isolation |
事务隔离级别 |
| Preinit Pool |
立即初始化连接池如果为 False,则第一个 JDBC 请求的响应时间会较长,因为包含了连接池建立的时间 |
Connection Validation by Pool
验证连接池是否可响应
| 字段 |
含义 |
| Test While Idle |
当连接空闲时是否断开 |
| Soft Min Evictable Idle Time(ms) |
连接在池中处于空闲状态的最短时间 |
| Validation Query |
一个简单的查询,用于确定数据库是否仍在响应默认为jdbc驱动程序的 isValid() 方法,适用于许多数据库 |
Database Connection Configuration
| 字段 |
含义 |
| Database URL |
数据库连接 URL |
| JDBC Driver class |
数据库驱动 |
| Username |
数据库登录用户名 |
| Password |
数据库登录密码 |
| Connection Properties |
建立连接时要设置的连接属性 |
url实例
jdbc:mysql://localhost:3306/animal?serverTimezone=UTC
useUnicode=true&characterEncoding=UTF8&autoReconnect=true&allowMultiQueries=true(允许执行多条 sql)
常见数据库的连接 URL和驱动
| 数据库 |
驱动 |
URL |
| MySQL |
com.mysql.jdbc.Driver |
jdbc:mysql://host:port/{dbname} |
| PostgreSQL |
org.postgresql.Driver |
jdbc:postgresql:{dbname} |
| Oracle |
oracle.jdbc.driver.OracleDriver |
jdbc:oracle:thin:user/pass@//host:port/service |
| sqlServer |
com.microsoft.sqlserver.jdbc.SQLServerDriver |
jdbc:sqlserver://host:port;databaseName=databaseName |
引入jar包
下载
- 进入:https://dev.mysql.com/downloads/connector/j/
- 下载解压出jar包
引入
- 引入方式一:将下载好的jar包直接放到 jmeter 的 lib 目录下,然后重新启动就行了
- 引入方式二:在测试计划底部添加 jar 包即可
JDBC Request
- JDBC Request 主要是向数据库发送一个 JDBC 请求(sql 语句),并获取返回的数据集
- 它需要和数据库连接池配置(JDBC Connection Configuration)一起使用
面板解释
| 字段 |
含义 |
| Variable Name Bound to Pool |
数据库连接池配置的名称 |
| Query Type |
sql 语句的类型 |
| SQL Query |
sql 语句语句结尾不需要添加 ; 变量用 ? 占位 |
| Parameter values |
需要传递的变量值,多个变量用 , 分隔 |
| Parameter types |
变量类型 |
| Variable Names |
保存sql语句返回的数据和返回数据的总行数用 , 分隔跳过列用空 |
| Result Variable Name |
一个 Object 变量存储所有返回值 |
| Query timeout(s) |
超时时间;默认0,代表无限时间 |
| Limit ResultSet |
和 limit 类似作用,限制 sql 语句返回结果集的行数 |
| Handle ResultSet |
如何定义 callable statements 返回的结果集;默认是存储为字符串 |
操作实例
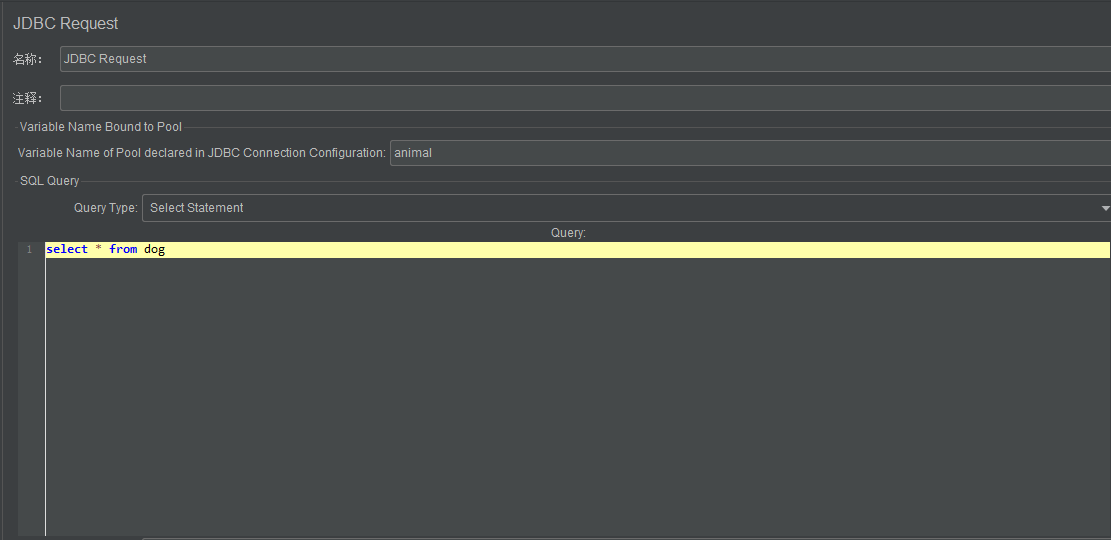
只有sql语句实例
- 先引入jar包到lib
- 设置JDBC Connection Configuration
- 设置JDBC request
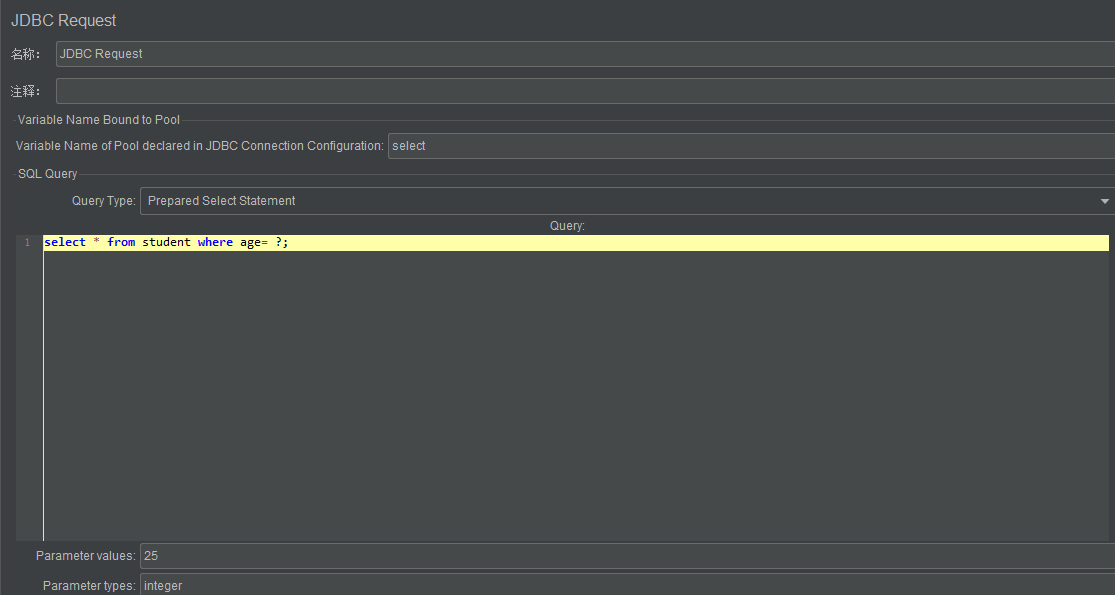
参数化实例
注意点
- 有几个问号,Parameter value、Parameter type 填写值的数量要保持一致,用,分隔
- 问号其实是占位符,如果学过编程的童鞋应该也知道这种写法,可以避免 SQL 注入的问题
- sql 中使用占位符时,Query Type 必须选择 Prepared Select Statement 或者 Prepared Update Statement
- 可以用 Jmeter 变量去赋值
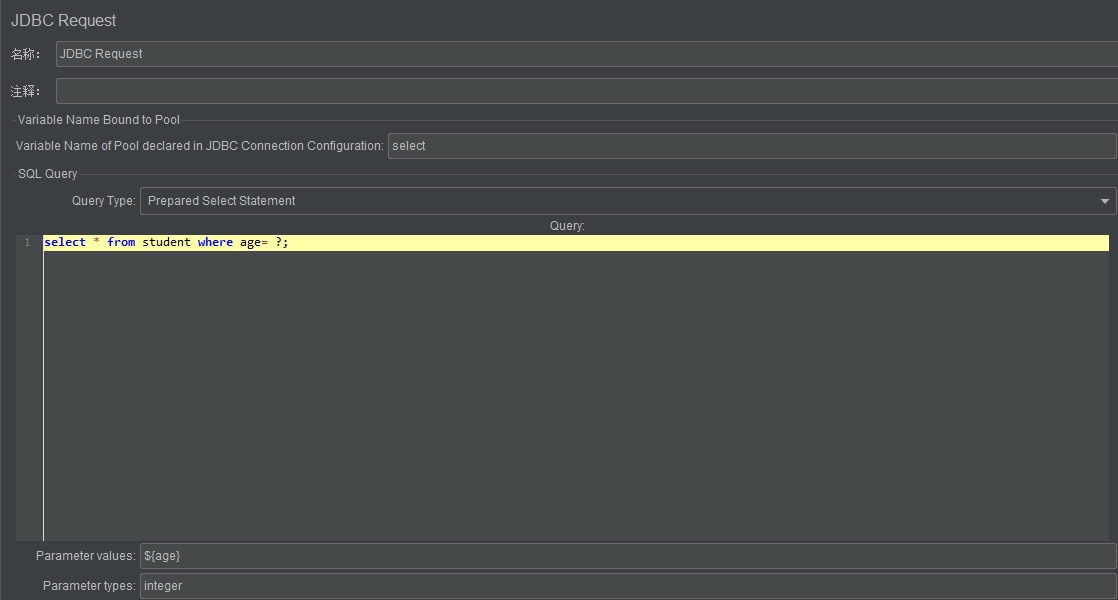
参数化+变量
注意点
- 如果在 sql 语句中使用变量,且是字符串类型,需要加上引号(前提是变量值没有加引号),如 '${name}'
- 如果在 Parameter values 中使用变量,且是字符串类型,不需要加上引号,只需要在 Parameter types 里写明为 varchar 即可
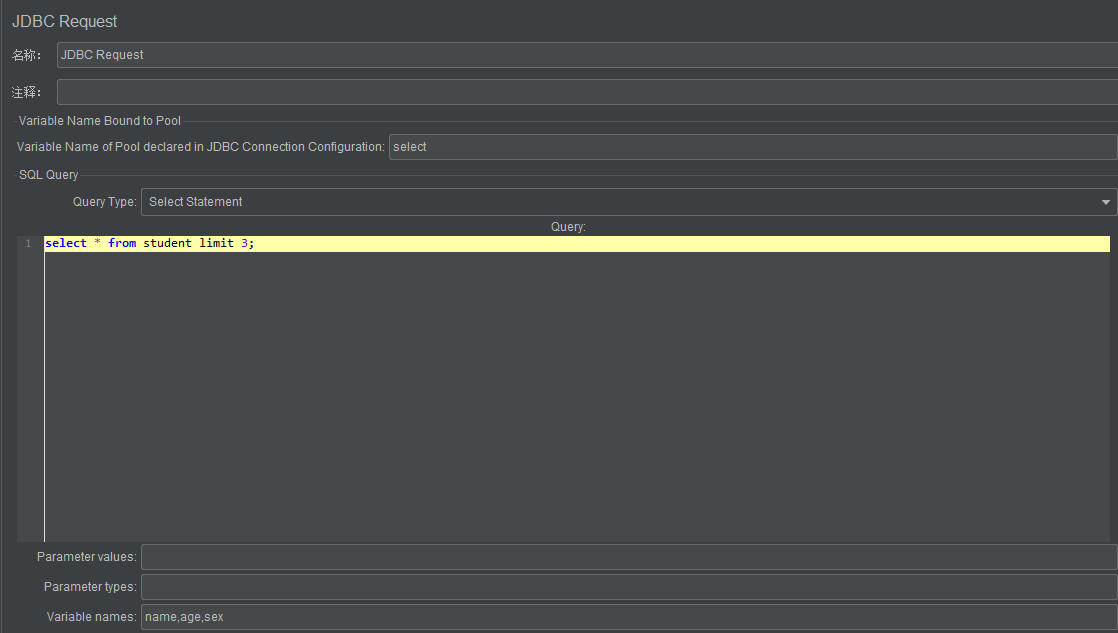
使用variable Names实例
一般结合Debug Sampler(调试取样器)使用,通常variable Names设置为查询语句的所有字段,字段间用逗号隔开
使用Result variable name实例
同样一般也是结合Debug Sampler使用
调试取样器返回的结果是一个数组的形式,每个元素代表一条记录
使用Limit ResultSet实例
- Limit ResultSet 是对 sql 语句返回的结果集限制行数
- limit 10 限制只返回了 10 条数据,然后 Limit ResultSet = 6 限制结果集最终只返回 6 条数据
获取与使用JDBC Request返回的数据
- JDBC Request 的具体使用,一般是通过 Variable names 和 Result variable name 来获取返回的数据
- 同样也可以将获取的数据提取出来,赋予HTTP请求使用
Variable names+ForEach控制器
- 将调试取样器放到ForEach控制器下
- 设置调试取样器
- 设置名称:name:${name}
- 其他值不变
- 设置ForEach控制器
- 输入变量前缀(在查看结果树的结果中前缀就是以自己输入的值为开头,一般与Variable names设置的一致)
- 开始循环字段(0表示从第1个开始)
- 结束循环字段(100表示第101个结束)
- 输出变量名称(表示获取结果之后的变量名是什么,一般与Variable names一致)
Variable names+循环控制器
- 将调试取样器放到循环控制器下
- 设置调试器
- 设置名称 name:({__V(name_){num},)}
- 其他不变
- 将计数器放到循环控制器下
- 设置计数器
- 设置开始值为0
- 递增为1
- 结束值为2(有几条数据设置2-1)
- 引用名称(可以使用num)
Result variable name+循环控制器
- 将调试取样器放到循环控制器下
- 将计数器和用户参数放到循环控制器下
- 设置循环控制器(一般有几个参数就循环几次)
- 设置计数器(设置开始值和结束值,递增1,引用名称随意)
- 设置用户参数
- 设置参数名称 result
- 设置值 ({__BeanShell(vars.getObject("result").get(){num}).get("name"))} result是Result variable name,num是计数器的引用名称,name是jdbc request的name列值
- 设置调试器
- 名称 name:${user_name} user_name引用的是用户参数名称
- 其他不变
CSV数据文件设置
CSV前言
- 为了实现简单的数据存储,是一个纯文本的文件
- 最通用的一种文件格式,它可以非常容易地被导入各种PC表格及数据库中
- CSV 文件可以用记事本、excel打开;用记事本打开的话,每一列数据都用逗号隔开
面板介绍
| 字段 |
含义 |
| Filename |
文件名 |
| File encoding |
文件编码 |
| Variable Names |
变量名称多个变量用 , 分隔 |
| Ignore first line |
忽略首行只在设置了变量名称后才生效(一般首行都是字段名称) |
| Delimiter |
分隔符默认 , |
| Allow quoted data? |
是否允许带引号 |
| Recycle on EOF? |
遇到文件结束符EOF 后再次循环 |
| Stop thread on EOF? |
遇到文件结束符EOF 后停止运行线程? |
| Sharing mode |
线程共享模式 |
跨平台运行Jmeter,设置CSV文件路径
- 通常,我们编写、调试脚本都是在 Window 机器上,而真正性能测试时,脚本几乎都在 Linux 下运行
- 使用 CSV 数据文件做参数化时,是需要指定文件路径的
- 这里就有个问题:Window 下写的文件路径到了 Linux 下是不正确的,导致无法正常读取 CSV 文件
- 具体方法
- 文件名 ({__P(user.dir,)}){__p(file.separator,)}test.txt __P函数()用来获取Jmeter的属性
- 然后只要把CSV文件上传到Linux系统Jmeter下的bin目录,这个脚本就可以跨平台执行
Jmeter属性
- 查看 非测试元件里面的属性显示
- file.separator的值是,这也是window特有的路径分隔符
- user.dir的值是Jmeter安装路径下的bin目录
总结
- ({__P(user.dir,)}){__P(file.separator,)}test.txt 可以根据不同的系统,不同的 Jmeter 安装路径,自动获取 Jmeter 路径,然后再获取不同系统下的文件路径分隔符,最后加上文件名称拼成文件路径
- 这样就可以解决使用 CSV 数据文件做参数化时,跨平台导致路径不一致的问题
- 重点前提:CSV 文件放在 Jmeter 的 bin 目录下,且通过 bin 目录运行 Jmeter
counter计数器
介绍
- 计数器的作用:循环递增生成数字
- 计数器使用 long 来存储值,因此取值范围是 -2 ^ 63 到 2 ^ 63-1
- 可以在线程组任意地方添加计数器
面板介绍
| 字段 |
含义 |
| Starting value |
初始值,long 整型,默认 0 |
| Increment |
每次迭代的递增值,默认 0,表示不增加 |
| Maximum value |
最大值,包含此值 |
| Number format |
数字可选格式 |
| Exported Variable Name |
引用名称 |
| Track counter independently for rach user |
每个用户都有一个独立的计数器 |
| Reset counter on each Thread Group Iteration |
每次线程组迭代时计数器将重置为初始值 |
注意事项
使用计数器生成的变量,值的类型为 string,所以有比较之类的操作时,需要带 "" 操作
ServerAgent监控服务器
下载安装
- JMeterPlugins-Extras.jar
- JMeterPlugins-Standard.jar
- ServerAgent-2.2.3.zip
客户端
- 如果通过官网下载的话,九江JmeterPlugins-Extras.jar和JmeterPlugins-Standard.jar放到D:apache-jmeter-5.2.1libext
- 然后通过 PerfMon Metrics Collector 监听器进行服务器性能数据显示
服务端
- 将 ServerAgent-2.2.3.zip 放到任意目录下,解压
- 进入 ServerAgent 目录,直接运行 ./startAgent.sh(如果无法运行,授权)
- 如果想监控window,则将ServerAgent放到window电脑的目录下,然后直接双击运行startAgent.bat即可
- 注意的是在启动ServerAgent的前提是系统已安装配置好Java环境
循环控制器
- 就一个需要了解的字段:循环次数,可以填具体的次数,也可以勾选永远
- 如果勾了永远,即使线程组的循环次数设置了次数,也会一直循环
- 如果填了 5 次,线程数 = 5,所以总共发出去的请求为 5 * 5 = 25
ForEach控制器
前言
- ForEach 控制器一般和用户自定义变量/JDBC结果变量一起使用,用于可以遍历读取相关的返回值
- 该控制器下的 Samplers 和控制器都会被执行一次或多次,每次读取不同的变量值
- ForEach 控制器和正则提取器是个好搭档,因为正则提取出来的变量值会用_分隔,而 ForEach 可以省略 _
面板介绍
| 字段 |
含义 |
| Input Variable Prefix |
输入变量名的前缀,默认为一个空字符串作为前缀。 |
| Start index for loop(exclusive) |
循环开始的索引不包括此值默认从 1 开始填 0 则起始索引是 1,填 1 则是 2 |
| End index for loop(inclusive) |
循环结束的索引包括此值填 100 则结束索引是 100 |
| Output variable |
输出的变量名在后续循环中,samplers 可使用的变量名 |
| Add”_”before number |
输入变量名和索引之间是否有 _ 间隔不勾选的话,则输入变量名和索引直接相连 |
jmeter分布式测试
为什么需要做分布式?
- 一台压力机的 Jmeter 默认最大支持 1000 左右的并发用户数(线程数),再大的话,容易造成卡顿、无响应等情况,这是受限于 Jmeter 其本身的机制和硬件配置(内存、CPU等)
- 由于 Jmeter 是 Java 应用,对 CPU 和内存的消耗较大,在需要模拟大量并发用户数时,单机很容易出现 JAVA 内存溢出的错误,导致测试脚本本身就有瓶颈
- 怎家java堆内存来满足测试的要求,但是单机无法支撑数以万计大并发,此时,需要多个压力机进行分布式压力测试,这样性能瓶颈就不会是压力机.
联想场景
- 测试 5000 并发的场景,但单机只能支持 1000 并发无法达到 5000
- 通过分布式(5 台机器起)可以模拟 5000 并发
分布式的最终目的
- 确保压力机不会出现性能瓶颈
- 在后面进行性能分析时,不需要考虑压力机是否会导致性能瓶颈的主要原因之一
实现分布式的条件
- 控制机和压力机的 jmeter 要一致
- jmeter 版本要一致
- jdk 主版本要一致(1.7、1.8...)
- jmeter 脚本中,csv 文件要一致(数据与路径要一致)
- jmeter 的插件要一致
- 同一局域网,防火墙开放端口
分布式配置
压力机配置
- 进入bin目录,修改jmeter.properties
- 修改server_port端口(默认1009),可以修改任意端口,但不能被占用
- 修改server.rmi.port端口(和server_port一致)
- 设置server.rmi.ssl.disable(默认false,代表需要认证,设置为true,减少不必要的麻烦)
- 启动jmeter-server服务,仍然在bin目录下
- linux或mac,执行命令 ./jmeter-server -Djava.rmi.server.hostname=压力机ip
- window,执行命令 jmeter-server.bat -Djava.rmi.server.hostname=压力机ip
- 检查防火墙
- 检查防火墙是否被关闭,防火墙会影响脚本执行和测试结构收集
- 确认 server_port 的端口没有被占用以及需要对外开放,端口占用会导致压力机报错
控制机配置
- 修改jmeter.properties
- 修改remote_hosts,remote_hosts=压力机ip1,压力机ip2
- 多个压力机之间用,隔开
- 不同压力机端口可以不一样,不需要全部都一致
- 如果控制机也测试则加 127.0.0.1:port ,然后修改 server_port 和 server.rmi.port (和压力机一样步骤)
- 设置 server.rmi.ssl.disable=true
- 设置 mode=Standard
- 启动远程服务器
注意事项
- 如果并发较高,建议将控制机设置为只启动测试脚本和收集汇总测试结果
- 分布式测试中,如果 1S 发送 100 个模拟请求,有 5 个压力机,那么需要将脚本的线程数设置为 20,否则模拟请求数会变成 500,和预期结果相差太大
- 只需要修改控制机的脚本,启动压力机之后,压力机执行的就是最新的脚本
分布式测试中可能会遇到的问题
缺少rmi_keystore.jks,也就是证书问题
- 方式一:在 jmeter.properties 中设置 server.rmi.ssl.disable=true
- 方式二:在 bin 目录下,执行 create_create-rmi-keystore.sh
最后会在bin目录下生成rmi_keystore.jks证书
jmeter CLI模式
介绍
- CLI = Command Line,命令行模式,我们常说的 NON GUI 模式,无界面模式
- 真正做负载测试时,应该使用 CLI 模式运行,而不是 GUI
官方提醒
- 负载测试不要用 GUI 模式,GUI模式仅用于创建测试计划和调试脚本
- 增加 Java 堆空间来满足你的测试环境
CLI模式可选参数
| 字段 |
含义 |
| -n |
指定 JMeter 将在 cli 模式下运行 |
| -t |
包含测试计划的 jmx 文件名称 |
| -l |
记录测试结果的 jtl 文件名称 |
| -j |
记录 Jmeter 运行日志的文件名称 |
| -g |
输出报告文件( .csv 文件) |
| -e |
生成 html 格式的测试报表 |
| -o |
生成测试报表的文件夹;文件夹不存在或为空 |
服务器相关参数
| 字段 |
含义 |
| -H |
代理服务器的 host 或 ip |
| -P |
代理服务器的 port |
| -r |
指定所有远程服务器中运行测试 |
| -R |
在指定的远程服务器中运行测试 |
| -X |
服务器运行完脚本后自动停止 jmeter-server |
属性参数
java系统属性和jmeter属性可以直接通过以下命令进行覆盖,而不用手动修改jmeter.properties
| 字段 |
含义 |
| -D[prop_name]=[value] |
定义一个 Java 系统属性值 |
| -J[prop_name]=[value] |
定义本地 JMeter 属性 |
| -G[prop_name]=[value] |
定义要发送到所有远程服务器的 JMeter 属性 |
| -G[propertyfile] |
定义一个包含 JMeter 属性的文件,该文件将发送到所有远程服务器 |
| -L[category]=[priority] |
覆盖日志记录设置,将特定类别设置为给定的优先级;设置根日志记录级别 |
实例
- 执行 FlaskDemo.jmx 脚本,并在 result 目录下生成 report.jtl 报告 jmeter -n -t FlaskDemo.jmx -l result/report.jtl(report.jtl存在也没关系,可以自动覆盖)
- 执行 FlaskDemo.jmx 脚本,在 result 目录下生成 report.jtl 报告,最后在 report 目录下生成测试报表 jmeter -n -t FlaskDemo.jmx -l result/report.jtl -e -o report(report.jtl必须不存在,report目录必须不存在或者为空)
- 将 .jtl 文件转换为 .html 文件,并保存到 report 文件夹中 jmeter -g report.jtl -o report(类似于第2条,只不过跳过执行,jmx文件的步骤,直接将.jtl文件转换为.html文件)
- jmeter GUI中也有转换的功能 tools→Generate HTML report,选好jtl文件,properties配置文件,存放HTML报告的文件夹.
- 启动所有远程slave机执行FlaskDemo.jmx,并在 result 目录下生成 report.jtl jmeter -n -t FlaskDemo.jmx -r -l result/report.jtl(会执行jmeter.properties的remote_hosts填的所有远程slave机)
- 启动指定的远侧还给你slave机执行FlaskDemo.jmx,并在result目录下生成report.jtl,和-r不一样,-R 是指定slave机的,并不是所有slave机 jmeter -n -t FlaskDemo.jmx -l result/report.jtl -R 172.20.72:38:1234,127.0.0.1:1234
- 跟6一样,只是加了-X,让远程服务器在执行完脚本后自动退出 jmeter-server jmeter -n -t FlaskDemo.jmx -l result/report.jtl -R 172.20.72:38:1234 -X,如果想默认设置为结束后停止,可以将属性jmeterengine.remote.system.exit 设置为 true(默认值为false),则jmeter将在测试结束后停止RMI之后调用System.exit(0),不过不建议.