函数(二)
-
函数—局部变量


1 #案例1: 2 name = "Black girl" #全局变量 3 def change_name(): 4 name = "黑色的姑娘" #局部变量 5 print("在",name,"里面...",id(name)) 6 change_name() 7 print(name,id(name)) 8 #结果为: 9 # 在 黑色的姑娘 里面... 2219085489840 10 #Black girl 2219086385264 11 12 13 #案例2(局部变量的优先级高于全局变量): 14 name = "Black girl" #全局变量 15 def change_name(): 16 print("在",name,"里面...",id(name)) 17 change_name() 18 print(name,id(name)) 19 #结果为: 20 # 在 Black girl 里面... 2219085489840 21 #Black girl 2219086385264 22 23 24 #小结 25 #定义在函数外部一级代码的变量,叫全局变量,全局能用,但遵循“从上到下”的顺序。 26 # 局部变量就是指定义在函数里的变量,只能在局部生效 27 # 在局部可以引用全局变量 28 # 如果,全局和局部都有一个变量,叫name,函数查找变量的顺序是由内而外的。 29 30 31 #案例3: 32 name = "Black girl" #全局变量 33 def change_name(): 34 #name = "黑色的姑娘" #局部变量 35 print("在",name,"里面...",id(name)) 36 37 def func2(): 38 name = "rain" #局部变量 39 func2() 40 change_name() 41 print(name,id(name)) 42 #结果为: 43 #在 Black girl 里面... 2001613295984 44 #Black girl 2001613295984 45 46 #小结 47 #定义两个不同的函数如change_name和func2,两者是独立的空间,相同的name变量各自不会影响

-
函数—在函数里修改全局变量
1 #global 在函数里修改全局变量: 2 name = "Black girl" #全局变量 3 def change_name(): 4 global name #在函数里修改全局变量(声明name变量为全局变量并且位置必须放在name之前,从实际开发的角度,不建议使用global,因为实际场景中,其他位置还是调用全局变量,将函数内部的变量声明为全局变量后,函数一执行就修改了,难度加大) 5 name = "黑色的姑娘" #局部变量 6 age = 25 7 print("在",name,"里面...",id(name)) 8 change_name() 9 print(name,id(name)) 10 #结果为: 11 # 在 黑色的姑娘 里面... 2345943197360 12 #黑色的姑娘 2345943197360
-
函数—在函数里修改列表数据
1 names = ['Alex','Black Girl','Peiqi'] #全局变量 2 def change_name(): 3 names = ['Alex','Black Girl'] #局部变量 4 print(names) 5 change_name() 6 print(names) 7 #结果为: 8 # ['Alex', 'Black Girl'] 9 #['Alex', 'Black Girl', 'Peiqi'] 10 11 12 names = ['Alex','Black Girl','Peiqi'] #全局变量 13 def change_name(): 14 del names [2] #删除全局变量 15 names[1]="黑姑娘" 16 print(names) 17 change_name() 18 print(names) 19 #结果为: 20 # ['Alex', '黑姑娘'] 21 #['Alex', '黑姑娘'] 22 23 #小结: 24 #列表的重新赋值不会生效;整体的内存地址不能修改,但是内部的元素的内存地址是可以修改的。 25 #字典、列表、集合、对象 可以修改。 26 #字符串、数字 不可以修改。 27 28 #global 强制修改,不建议使用 29 names = ['Alex','Black Girl','Peiqi'] #全局变量 30 def change_name(): 31 global names 32 names =[12,3,5] 33 print(names) 34 change_name() 35 print(names) 36 #结果为: 37 # [12, 3, 5] 38 #[12, 3, 5]
-
函数—嵌套函数
1 #嵌套函数(1) 2 def func1(): 3 print('alex') 4 5 def func2(): 6 print('eric') 7 8 func1() #结果为;alex 9 10 #嵌套函数(2) 11 def func1(): 12 print('alex') 13 14 def func2(): 15 print('eric') 16 func2() #结果为; 17 18 19 #嵌套函数(3) 20 def func1(): 21 print('alex') 22 23 def func2(): 24 print('eric') 25 func2() 26 func1() #结果为;alex,eric 27 28 #小结:函数内部可以再次定义函数;执行需要被调用
1 #嵌套函数(1) 2 age = 19 3 def func1(): 4 age = 73 5 print(age) 6 def func2(): 7 age=84 8 print(age) 9 func2() 10 func1() #结果为;73,84 11 12 13 #嵌套函数(2) 14 age = 19 15 def func1(): 16 age = 73 17 print(age) 18 def func2(): 19 print(age) 20 func2() 21 func1() #结果为;73,73 如果子函数内部没有age变量,会一层一层往上级找,直到找到为止 22 23 24 #嵌套函数(3) 25 age = 19 26 def func1(): 27 28 def func2(): 29 print(age) 30 age = 73 31 func2() 32 func1() #结果为;73 33 34 35 #嵌套函数(4) 36 age = 19 37 def func1(): 38 39 def func2(): 40 print(age) 41 func2() 42 age = 73 43 #func1() #结果为;NameError: free variable 'age' referenced before assignment in enclosing scope 44 45 46 #嵌套函数(5) 47 age = 19 48 def func1(): 49 global age 50 def func2(): 51 print(age) 52 func2() 53 age = 73 54 func1() #结果为;19 55 56 57 #嵌套函数(5) 58 age = 19 59 def func1(): 60 global age 61 def func2(): 62 print(age) 63 age = 73 64 func2() 65 func1() 66 print(age) #结果为;73,73
-
函数—作用域
- 在Python中函数就是一个作用域(与JavaScript相似)局部变量放置在其作用域中
- 在C#、Java中的作用域为{}
- 代码定义完成后,作用域已经生成,顺着作用域链向上查找
- 函数名可以当做返回值。例如 return func2
1 #代码定义完成后,作用域已经生成,顺着作用域链向上查找。 2 #函数名可以当做返回值 3 age = 18 4 def func1(): 5 age = 73 6 def func2(): 7 print(age) 8 9 return func2 10 val = func1() 11 val() #结果为:73
-
函数—匿名函数
1 def calc(x,y): #声明一个函数 2 if x < y: 3 return x*y 4 else: 5 return x/y 6 7 print(calc(3,8)) #调用函数 24 8 9 #匿名函数 10 func = lambda x,y: x*y if x < y else x/y #lambda结合三元运算来声明一个匿名函数 11 12 print(func(3,8)) #调用匿名函数 24 13 14 15 #匿名函数例题: 16 data = list(range(10)) 17 print(data) #结果为:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 18 for index,i in enumerate(data): 19 data[index]=i*i 20 print(data) #结果为:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81] 21 22 #优化后: 23 data = list(range(10)) 24 print(data) #结果为:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 25 def f2(n): 26 return n*n 27 print(list(map(f2,data))) #结果为:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81] 28 29 print(list(map(lambda x:x*x,data))) #结果为:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81] 30 31 #小结: 32 #节省代码量 33 #看着高级
-
函数—高阶函数

1 #变量可以指向函数, 2 # 函数的参数能够接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数 3 def calc(x): 4 return x*x 5 #f = lambda x:x*x #变量名指向函数 6 f=calc #变量名指向函数 7 #f(2) 等价于 calc(2) 8 print(f(2)) 9 10 11 #高阶函数1 12 def func(x,y): 13 return x+y 14 15 def calc(x): 16 return x 17 f=calc(func) #高阶函数 18 print(f(5,9)) #结果为:14 19 20 21 #高阶函数2 22 def func2(x,y): 23 return abs,x,y #abs 求绝对值 24 res = func2(3,-10) 25 print(res) #结果为:(<built-in function abs>, 3, -10) 26 print(res[0](res[1]+res[2])) #结果为:7
-
函数—递归
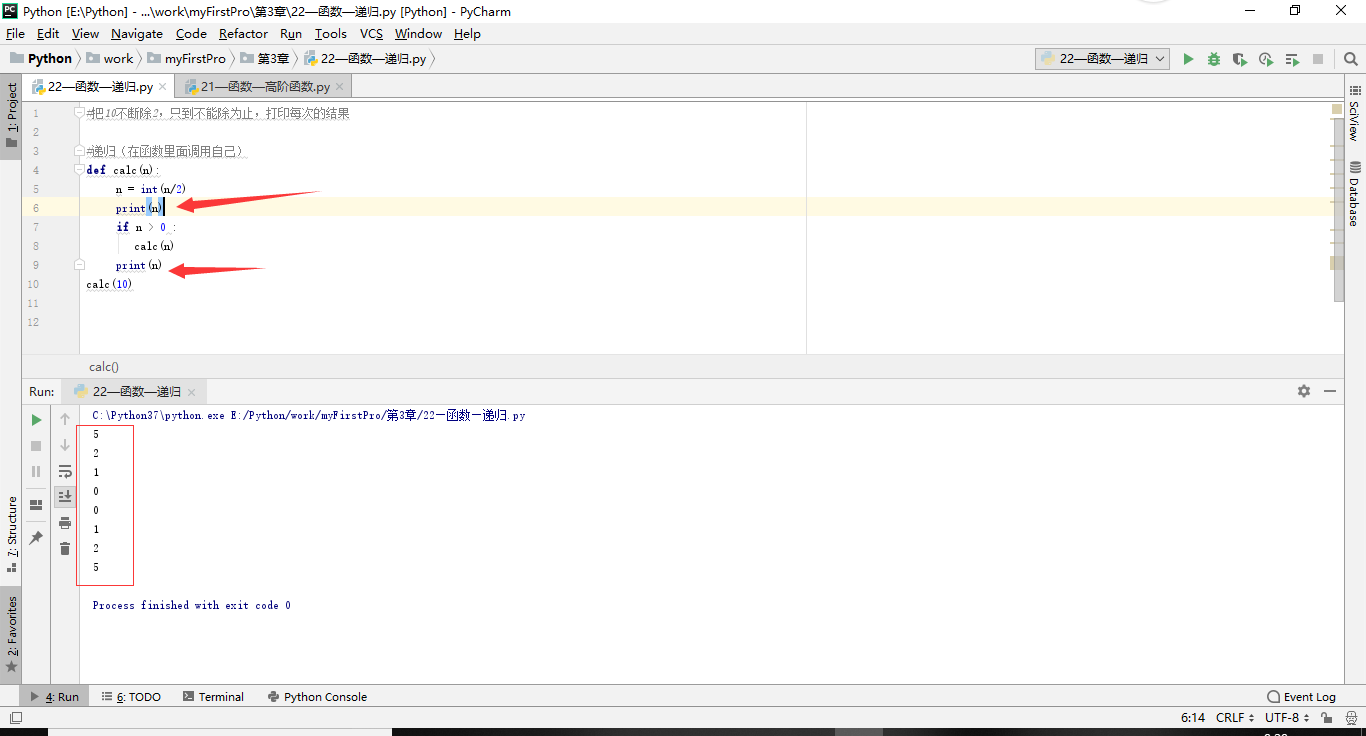
1 #把10不断除2,只到不能除为止,打印每次的结果 2 # n = 10 3 # while True: 4 # n = int(n/2) 5 # print(n) 6 # if n==0: 7 # break 8 # 9 10 import sys #导入sys模块 11 print(sys.getrecursionlimit()) #Python中最大值的限制为1000,防止将内存占用完毕 12 sys.setrecursionlimit(1200) #修改为1200次限制 13 14 #递归(在函数里面调用自己) 15 def calc(n): 16 n = int(n/2) 17 print(n) 18 calc(n) 19 20 # r1 = calc(10) 21 # r2 = calc(r1) 22 # r3 = calc(r2) 23 # print(r3) #选中后,按 ctrl + / 注释 24 calc(10)

-
函数—递归执行过程分析(一层层进去然后再一层层退出)
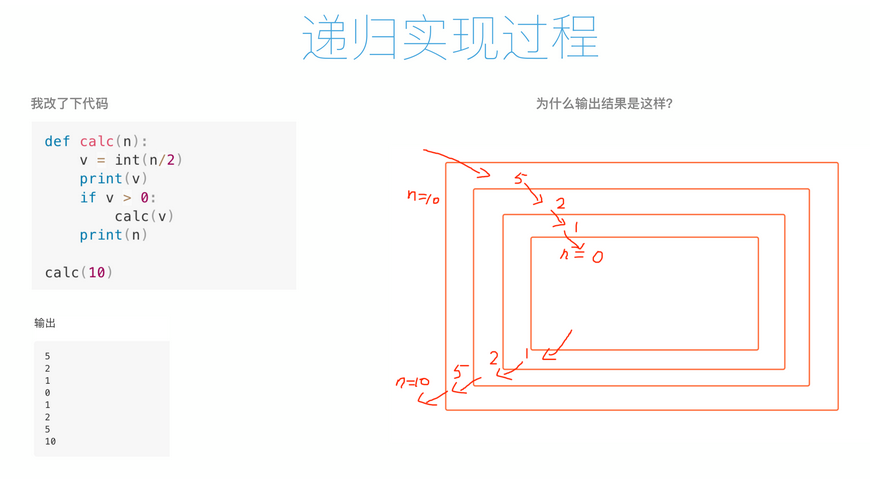
-
函数—递归的返回值
1 def calc(n,count): 2 print(n,count) 3 if count < 5: 4 calc(n/2,count+1) 5 6 calc(188,1) 7 #结果为: 8 # 188 1 9 # 94.0 2 10 # 47.0 3 11 # 23.5 4 12 # 11.75 5 13 14 15 #返回最底层的值 16 def calc(n,count): 17 print(n,count) 18 if count < 5: 19 return calc(n/2,count+1) 20 else: 21 return n 22 23 res = calc(188,1) 24 print('res',res) 25 #结果为: 26 # 188 1 27 # 94.0 2 28 # 47.0 3 29 # 23.5 4 30 # 11.75 5

-
函数—递归的特性总结
-
必须有一个明确的结束条件,要不就会变成死循环了,最终撑爆系统
-
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
-
递归执行效率不高,递归层次过多会导致栈溢出

-
递归与栈的关系(http://www.cnblogs.com/alex3714/articles/8955091.html)

但是却执行了900多次就出错,还说超过了最大递归深度限制,为什么要限制呢?
通俗来讲,是因为每个函数在调用自己的时候 还没有退出,占内存,多了肯定会导致内存崩溃。
本质上讲呢,在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
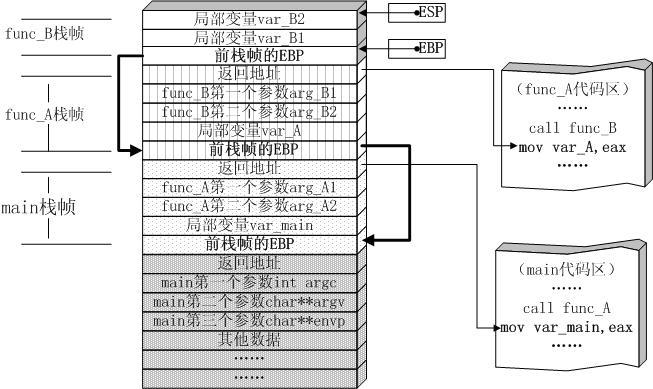
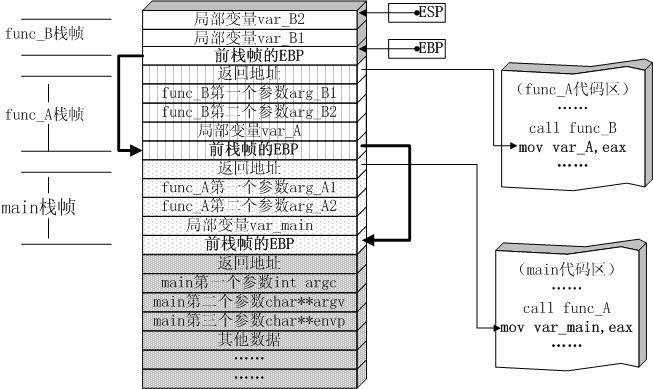
-
函数—递归的作用
-
可以用于解决很多算法问题,把复杂的问题分成一个个小问题,一一解决。
-
比如求斐波那契数列、汉诺塔、多级评论树、二分查找、求阶乘等。
1 # 求阶乘: 2 #任何大于1的自然数n阶乘表示方法: 3 # n!=n*(n-1)! 4 # n!=1*2*3*4....*n 5 6 def factorial(n): 7 if n == 0: #n 等于 0 时,运算结束 8 return 1 9 return n * factorial(n-1) 10 print(factorial(4)) #结果为:24
-
函数—尾递归优化
- 如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。
- 当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。
- 尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
- 当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。
- 编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。
- 通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
1 #尾递归 2 def calc(n): 3 print(n - 1) 4 if n > -50: 5 return calc(n - 1) 6 calc(100) 7 8 #阶乘 9 def factorial(n): 10 if n == 0: # n == 0 就运算结束 11 return 1 12 return n * factorial(n - 1) # 每次递归相乘,n值都较之前小1 13 d = factorial(4) 14 print(d) 15 #递归计算最终的return操作是乘法操作。所以不是尾递归。因为每个活跃期的返回值都依赖于用n乘以下一个活跃期的返回值,因此每次调用产生的栈帧将不得不保存在栈上直到下一个子调用的返回值确定。