第四章 文件操作
4.1内存相关
-
示例一
v1=[11,22,33] v2=[11,22,33] #会重新开辟内存空间,保存当前的值 v1=666 v2=666 #会重新开辟内存空间,保存当前的值 v1="abc" v2="abc" #会重新开辟内存空间,保存当前的值 -
示例二:
v1=[11,22,33,44] v1=[11,22,33] #会重新开辟内存空间,保存当前的值 -
示例三:赋值操作不会开辟新的内存空间
#内部修改 v1=[1,2] v2=v1 #将v2的内存地址指向v1所指向的内存地址,即v1和v2指向同一个内存空间 v1.append(3) #修改V1的值, v2也会变化 print(v2) #[1,2,3] v2.append(4) #修改v2的值,v1也会改变 print(v1) #[1,2,3,4] #赋值操作 v1=[11,22,33,44] #开辟一个新的内存空间,将v1重新指向他、 #对于v2而言,其仍指向[1,2,3,4]的内存空间 print(v1,v2) #[11, 22, 33, 44] [1, 2, 3, 4]#对于字符串来说,其不可进行内部修改 v1="apple" v2=v1 #赋值 v1="pear" print(v1,v2) #pear,apple -
示例四:嵌套的
v=[1,2,3] values=[11,22,v] print(values) #[11, 22, [1, 2, 3]] v.append("apple") #对v进行操作,则values因为也包含v,则其也会发生变化 print(values) #[11, 22, [1, 2, 3, 'apple']] values[-1].append(666) print(v) #[1, 2, 3, 'apple', 666] v=9999 #values指向的还是v之前的内存空间 print(values) #[11, 22, [1, 2, 3, 'apple', 666]] values[-1]=666 #v指向的内存空间还是9999 print(v) #9999 -
示例五
v1=[1,2,3] v2=["a","b","c"] v3=["x","y","z",v1,v2,v1] v3[-1].append(666) #修改了v1所指向的内存单元的值 print(v1) #[1, 2, 3, 666] #v3里面也有指向v1内存单元的值,故v3里面的v1值也全部会变 print(v3) #['x', 'y', 'z', [1, 2, 3, 666], ['a', 'b', 'c'], [1, 2, 3, 66]] #实际上v3里面存的是v1和v2的内存地址 v3[3]=999 print(v3) #['x', 'y', 'z', 999, ['a', 'b', 'c'], [1, 2, 3, 666]] print(v1) #[1, 2, 3, 666]
内存垃圾:当此内存没有指针指向它的时候,就会被系统当成垃圾
-
查看内存地址id
v1=[1,2,3] v2=[1,2,3] v3=v1 print(id(v1),id(v2),id(v3)) #1653666177608 1653666177672 1653666177608 #v1和v3的内存地址是一样的,v2的内存地址是新开辟的 v1=999 print(id(v1),id(v3)) #v1的内存地址变化了,v3的内存地址保持不变 -
python中为了内存优化,做了缓存,提高性能,把一些相同的整型和字符串会放到一个内存地址中
-
整型:(-5到256)
-
字符串:除了形如"a_*" * 3
当然只有一些整型、字符串会出现这样的情况
-
-
==与is的区别
#==是判断数值是否相等,is是判断内存地址是否相等 v3=[1,2,3] v4=[2,3,4] print(v3==v4) #False print(v3 is v4) #False v1=[1,2] v2=[1,2] #v1和v2的内存地址并不相等 print(v1==v2) #True print(v1 is v2) #False v5=[1,2,3] v6=v5 #v6和 v5的内存地址相等,则值也相等 print(v5==v6) #True print(v5 is v6) #True #python缓存机制导致的特殊情况 v7=10 v8=10 #由于python的缓存机制,导致v7和v8实际上是一个内存地址 print(v7==v8) #True print(v7 is v8) #True -
方法的内存操作
print("列表的append()方法") v1=[1,2,3] v2=v1 v1.append("apple") #列表是可以修改的,append()不会重新开辟一个内存空间 print(v1,v2) #[1, 2, 3, 'apple'] [1, 2, 3, 'apple'] print("字符串的大小写转换如upper()") v3="apple" v4=v3 v3.upper() #由于是str类型,并不可变,会重新开辟一块内存空间 v5=v3.upper() # 若有接收的值,接收者能变大写 print(v3,v4,v5) #apple apple APPLE print("字符串类型的切片") v6="apple" v7=v6[0:2] #字符串并不可变,所以只能新开辟一块内存空间接收切片的值 print(v6,v7) #原来的值没有修改 print("集合的add()") v8={1,2,3} v9=v8 v8.add(666) #集合是可变类型,修改了v8地址的值,v9也会修改 print(v8,v9) #{1, 2, 3, 666} {1, 2, 3, 666} print("集合的intersection()") v10={1,2,3} v11=v10 v10.intersection({1,3,5}) #需要将其结果赋值给一个新的值 print(v10,v11) #实际上没有对v10和v11的元素的值修改 print("列表的索引") v12=[1,2,3,4,5] #列表其实存的是指向一个大 的内存地址 v13=v12 print("修改前:",id(v12[0])) #140714809807904 v12[0]=[6,7,8,9] #列表中的索引指向的是一个内存地址,内存地址所指的值是索引中的值 print("修改后:",id(v12[0])) #1944748080712 ,修改前与后的索引地址是不同的 #可以发现,索引指向的地址由于值发生变化,又创建一个新的内存空间,并重新指向该内存地址 print(v12,v13) #[[6, 7, 8, 9], 2, 3, 4, 5] [[6, 7, 8, 9], 2, 3, 4, 5] print("列表的嵌套") v14=[1,2] v15=[1,2,v14] v14[0]="apple" #修改v14[0]的值,由于v15[2]指向v14的地址,所以v15[2]的值会随着v14改变 print(v14,v15) #['apple', 2] [1, 2, ['apple', 2]] v15的值也会随着发生变化 v15[2][1]=666 #修改的是v15所指向的v14的[1]号地址,v14和v15会随着一起发生变化 print(v14,v15) #['apple', 666] [1, 2, ['apple', 666]] v15[2]=123 #修改的是v15[2]的值,v15[2]会重新创建一个内存空间,保存内存地址 print(v14,v15) #['apple', 2] [1, 2, 123] v14的值不会发生变化 #列表/集合/字典 的内存 操作类似 print("取字典key,修改values") v16={"k1":"v1","k2":"v2"} v17=v16 print("修改前:",id(v16["k1"])) #2358676809632 v16["k1"]="apple" #v17的地址指向v16,修改 v16则v17的值也会随之改变 print("修改后:",id(v16["k1"])) #2358676810864 print(v16,v17) #{'k1': 'apple', 'k2': 'v2'} {'k1': 'apple', 'k2': 'v2'} #再来一道列表的嵌套的题 print("列表的嵌套") v18=[1,2,3] v19=[v18,v18,v18] v19[0]="apple" #只是重新开辟一块内存空间,将v19[0]指向该内存地址 print(v18,v19) #[1, 2, 3] ['apple', [1, 2, 3], [1, 2, 3]] v18[0]=666 print(v18,v19) #[666, 2, 3] ['apple', [666, 2, 3], [666, 2, 3]] v19[2][2]=999 print(v18,v19) #[666, 2, 999] ['apple', [666, 2, 999], [666, 2, 999]] print("字典循环的内存相关的操作") v20={} for i in range(10): v20["user"]=i print(v20) #{'user': 9} print("列表中嵌套字典的循环") v21=[] v22={} for i in range(10): v22["user"]=i v21.append(v22) print(v21,v22) #[{'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}] {'user': 9} v23={"k1":"v1","k1":"v2"} #字典保存的方法是 键通过哈希算法转换成0101的值并保存值的地址,根据值的地址可以找到对应的内存,找到真正的值 print(v23) #{'k1': 'v2'} 相同键,只会保存最后一个键与值 print("列表和在循环中创建字典并添加入列表") v24=[] for i in range(10): v25={} v25["user"]=i v24.append(v25) print(v24,v25) #[{'user': 0}, {'user': 1}, {'user': 2}, {'user': 3}, {'user': 4}, {'user': 5}, {'user': 6}, {'user': 7}, {'user': 8}, {'user': 9}] {'user': 9} print("列表与循环append()") v26=[1,2,3,4] v27=[] for i in v26: v27.append(i) #相当于把数字的地址给到v27 print(v26,v27) #[1, 2, 3, 4] [1, 2, 3, 4] print(id(v26[0]),id(v27[0])) #140714614182944 140714614182944 内存地址相同 v27[0]=666 print(v26,v27) #[1, 2, 3, 4] [666, 2, 3, 4] 只修改v27的值,v26不会发生改变 print("列表与循环append(str())") v28=[1,2,3,4] v29=[] for i in v28: v29.append(str(i)) #每次生成一个新的字符串添加到v29 print(v28,v29) #[1, 2, 3, 4] ['1', '2', '3', '4'] print(id(v28[0]),id(v29[0])) #140714809807904 2747158554528 内存地址不相同 print("带有字符串的列表与循环append()") v30=["apple","pear","cherry"] v31=[] for i in v30: v31.append(i.upper()) print(v30,v31) #['apple', 'pear', 'cherry'] ['APPLE', 'PEAR', 'CHERRY'] print(id(v30[0]),id(v31[0])) #2084019629952 2084019628048 内存地址不一样 v32=[] for i in v30: v32.append(i+"sb") #括号中的值修改过之后就会生成新的地址,没有修改就还是原来的地址 print(v30,v32) #['apple', 'pear', 'cherry'] ['applesb', 'pearsb', 'cherrysb'] print(id(v30[0]),id(v32[0])) #1931911098296 1931911457792 内存地址也不同
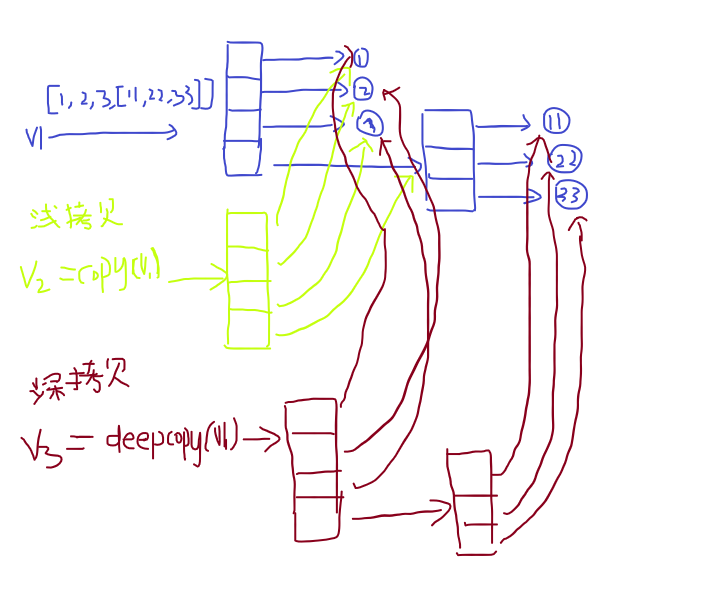
4.2深浅拷贝
4.2.1浅拷贝
拷贝第一层
4.2.2深拷贝
拷贝所有的数据(可变)
import copy
#在字符串、整型、布尔类型、元组的拷贝中,由于这些是不可变的数据类型,深浅拷贝并没有区别,都会开辟内存空间拷贝一份数据,拷贝出的数据会被copy()所赋予的值指向(究竟有没有创建新的空间?不知道,但是由于小数据池的缘故,第一层不可变数据类型拷贝出来的内存地址是相同的)
v1="apple"
v2=copy.copy(v1) #浅拷贝 由于小数据池的缘故,其内存地址相同(应该不一样的)
print(id(v1),id(v2)) #2015823325256 2015823325256
v3=copy.deepcopy(v1) #深拷贝 由于小数据池的缘故,其内存地址相同(应该不一样的)
print(id(v1),id(v3)) #2015823325256 2015823325256
#浅拷贝:只拷贝第一层
#深拷贝:拷贝嵌套层次中的所有可变类型(拷贝所有的数据(可变))
v4=[1,2,3,[11,22,33]]
v5=copy.copy(v4)
v6=copy.deepcopy(v4)
print(id(v4),id(v5),id(v6)) #1895510213704 1895510273032 1895510270216
print(id(v4[0]),id(v5[0]),id(v6[0])) #140725113574432 140725113574432 140725113574432
print(id(v4[-1]),id(v5[-1]),id(v6[-1])) #1895510213320 1895510213320 1895510373896
#可以发现深浅拷贝的内存地址都是新的,这是由于深浅拷贝都会拷贝一个一样大小的新的列表(第一层),前面三个数据是不可变类型,
#就将其内存地址存放到新的列表(第一层)中,也就是通过新列表(第一层)的内存地址可以索引到原来前面的三个数据
#但是最后一个数据是可变的列表,浅拷贝就将列表[11,22,33]的内存地址保存到新的列表(第一层)中,
#深拷贝则会再创建一个新的列表(第二层)并存放11,22,33的地址,通过新列表(第二层)的地址索引到原来的数据
#同理对于字典、集合这些可变的数据类型也是如此
#注意深拷贝和浅拷贝拷贝出来的数据都是一样的,只是地址不一样
#特殊情况
v7=(1,2,[666.999],4)
v8=copy.copy(v7)
v9=copy.deepcopy(v7)
print(id(v7),id(v8),id(v9)) #1701626030824 1701626030824 1701626031064
#发现元组中嵌套了可变的数据类型,导致深拷贝时也会重新创建一个元组,所以元组的地址发生了变化
4.2.3修改深浅拷贝中的文件
还是以上述代码的v1、v2、v3作为例子
当修改深浅拷贝的数据的时候,如需要修改v2[0]=666,为了保存666,会重新开辟一块内存空间保存666的值,并使原来的数据地址会指向新开辟的内存空间的地址,这样就保证了修改拷贝的文件中的值不会改变到原来的v1。
4.3文件的基本操作
obj=open("路径",mode="模式",encoding="编码")
obj.write(x)
y=obj.read()
obj.close()
4.4打开模式
- 只读只写字符串 r / w / a
- 可读可写字符串 r+ / w+ / a+
- 只读只写二进制 rb / wb /ab
- 可读可写二进制 r+b / w+b / a+b
4.5读写操作
-
read(),全部读到内存
-
read(1)
-
1表示一个字符
obj=open("a.txt",mode="r",encoding="utf-8") data=obj.read(1) #读取一个字符 obj.close() print(data) -
1表示一个字节
obj=open("a.txt",mode="rb") data=obj.read(1) obj.close() print(data)
-
-
readlines() 逐行进行读取
-
readline() 读取光标后一行
-
for循环 可以用在超级大文件,使得文件不会一次性读取到内存中
-
write(字符串)
obj=open("a.txt",mode="w",encoding="utf-8") data=obj.wirte("我要写入文件拉") obj.close() -
write(二进制)
obj=open("a.txt",mode="wb") data=obj.wirte("我想用二进制写文件".encode("utf-8")) obj.close()
4.6文件的中级操作
-
调整光标的位置seek() 以字节为单位(无论mode是否为二进制)
-
获取光标的当前所在字节的位置tell()
可以通过光标的操作对于大文件的下载中断以后继续进行。
obj=open("aaa.txt",mode="r",encoding="utf-8") data=obj.tell() obj.close() -
flush() 强制将内存中的数据写入到硬盘上
-
详细的关于文件中级操作的解释
#文件操作
#打开和关闭文件 open() close()
#方式一:先打开文件,一顿操作以后,再关闭文件
"""
file_obj=open("test.txt",mode="r",encoding="utf-8")
content=file_obj.read()
print(content)
file_obj.close() #关闭的时候才会把文件强制刷到硬盘上面
"""
#方式二:为了防止自己忘记关闭文件,导致文件不能从内存写到硬盘上,用with...as...加缩进进行文件操作
"""
with open("test.txt",mode="r",encoding="utf-8") as file_obj:
data=file_obj.read()
#缩进中的代码执行以后,自动关闭文件
"""
#文件的两种操作:read() write() 读和写
#read()读取全部的内容 / read(1) 从光标处开始往后读取一个字符 / readlines() 逐行进行读取,得到的是列表的形式
#readline() 仅读取光标后一行 / for i in file_obj: 也可以逐行进行读取,并且不会一次性放入到内存中,但是会有换行符,需要用strip()去除
#补充strip()可以去除空格、
、 等
#write() 将要写入的内容填入括号中即可,而且可以按照write("你好胖
")会进行换行。会根据光标的位置往后写(需要注意有例外,如a/a+/ab)
"""
file_obj=open("aaa.txt",mode="r",encoding=("utf-8"))
content=file_obj.readlines()
print(content) #['今朝有酒今朝醉
', '游湖
', '又用
', '与i及']
file_obj.seek(0)
content1=file_obj.readline() #直接读取文件的后一行
print(content1) #今朝有酒今朝醉
print("************************")
file_obj.seek(0) #再次把光标移动到首部
#如果需要读取一个非常大的文件,需要分开将文件放入内存中,不至于将一个大文件直接放入到内存当中
for i in file_obj:
result=i.strip() #在此处的主要功能就是去除
print(result)
file_obj.close()
"""
#三种基本的文件操作mode r/w/a 的区别:
#r 是只能读取文件,从光标处读取内容,不能写,且光标默认起始位置位于0(若没有该文件,则会报错)
#w 只能写文件,不能读取文件,在文件进行open()的时候就会先清空文件,然后将新的文件内容写入,写完以后光标会跑到最后(若没有该文件,则会新建一个文件)
#a 追加写入,不能读,光标默认在末尾,在此mode的情况下,只能追加到末尾,无论光标移动到哪里(若没有该文件,则会创建一个新的文件)
#若是不能读或写的mode下面,进行读或写的操作会报错:io.UnsupportedOperation: not writable
"""
file_obj=open("aaa.txt",mode="a",encoding="utf-8")
file_obj.write("你好")
file_obj.close() #会创建一个新的文件
"""
#三种基本的文件操作mode+ r+/w+/a+
#r+ 可读可写,从光标位置开始读写,默认光标位置为0(文件的开头处)读或者写,写的时候由于光标位置为0,所以会覆盖后面的内容
"""
file_obj=open("aaa.txt",mode="r+",encoding="utf-8")
file_obj.seek(3)
content=file_obj.read() #默认从光标的位置开始读,当然写也是如此
print(content)
file_obj.close()
"""
#seek()移动光标的操作 表示把光标移动到第几个字节的位置,不写默认光标在所在的mode情况
"""
file_obj=open("aaa.txt",mode="r+",encoding="utf-8")
file_obj.seek(3)
file_obj.write("呵呵") #如果想在末尾添加,可以先用read()就可以将光标移动到末尾,再进行写的操作
file_obj.close()
"""
#当不知道光标处于何处时
#w+ 可读可写,同样进行文件操作的时候会把文件清空
#注意:先写后读,发现读不到数据,这是由于写完后光标已经移动到末尾,所以读的时候仍按光标的位置开始读就读不到东西
"""
file_obj=open("aaa.txt",mode="w+",encoding="utf-8") #此时文件被清空
file_obj.write("今朝有酒今朝醉") #写完以后光标的位置当然是在末尾
content=file_obj.read() #从光标开始的位置读取,由于光标已经在末尾,读取的东西为空
print(content+"读不到的东西")
file_obj.seek(0) ##所以可以先将光标移动到开始的位置,就可以读取原来的文件的内容
result=file_obj.read() #在内存中已经 有新的内容写入,光标从头开始读取,就可以得到内存中新写入的内容
print(result) #今朝有酒今朝醉
file_obj.close()
"""
#a+ 可读可写,默认光标正在最后,所以想要读取数据,需要将光标移动到起始位置。当然,即使光标移动到最前,也还是写到末尾
"""
file_obj=open("aaa.txt",mode="a+",encoding="utf-8")
file_obj.write("我要写东西") #由于a+对于文件写操作都是追加到末尾,所以最终文件的末尾会加上“我要写东西”的字符串
content=file_obj.read() #可以读取文件
print(content)
file_obj.close()
"""
#注意:对于文件操作来说,由于文件会读取到内存中,文件一般不存在修改
#实在需要修改,其实是在内存中修改,再重新写入到硬盘中,不是直接对文件进行操作。
对于一些大的文件来说,想要修改其中的内容,但是由于文件过大不能一次性读入到内存,可以用:
f1=open("aaa,txt",mode="r",encoding="utf-8")
f2=open("aaa.txt",mode="w",encoding="utf-8")
for line in f1:
new_line=line.replace("帅哥","丑逼")
f2.write(new_line)
f1.close()
f2.close()
#当然也可以采用with open(...) as ...: 缩进的方式直接将两个文件的打开
with open("a.txt",mode="r",encoding="utf-8") as f1,open ("a",mode="w",encoding="utf-8") as f2:
for line in f1:
new_line=line.replace("美女","女神")
f2.write(new_line)
4.7一些文件操作的练习题
#一些关于文件操作的练习题
#练习一:将user中的元素根据_链接,并写入aaa.txt文件中
#user=["apple","pen"]
"""
user=["apple","pear"]
data="_".join(user) #用到字符串中的链接
print(data)
file=open("aaa.txt",mode="w",encoding=("utf-8"))
file.write(data)
file.close()
"""
#练习二:将uesr中的元素根据_链接,并写入aaa.txt的文件中
#user=[{"name":"apple","pwd":"123"},{"name":"pen","pwd":"123"}
"""
user=[{"name":"apple","pwd":"123"},{"name":"pen","pwd":"123"}]
file=open("aaa.txt",mode="w",encoding="utf-8")
for i in user:
#i其实是以字典的形式出现的
result="_".join(i.values()) #也可以用key来取values
#line="%s%s"%(i["name"],i["pwd"])
file.write(result+"
")
file.close()
"""
#练习三:将aaa.txt文件中的文件读取出来,并添加到一个列表user中
"""
#方式一:
user=[]
file=open("aaa.txt",mode="r",encoding="utf-8")
data=file.read()
user.append(data)
file.close()
print(user) #['apple_123
pen_123
']
#字符串其实可以通过
来分割一下,这里需要 用到split() ,这个也是字符串的方法
#data=data.strip() #['apple_123', 'pen_123']
result=data.split("
")
print(result) #['apple_123', 'pen_123', '']这样就可以拿到列表
#但是发现后面还有""空字符串,所以可以用strip()去除
print("************华丽的分割线************")
#方式二:
user1=[]
file=open("aaa.txt",mode="r",encoding="utf-8")
for i in file:
print(i) #逐行进行打印,而且保留有换行符
data1=i.strip()
user1.append(data1)
file.close()
print(user1) #最终也能得到['apple_123', 'pen_123']
"""
4.8理解文件操作的本质
理解了文件操作和进制以后,需要理解文件操作的本质
#理解文件操作的本质
"""
#根据字符串的内容以及encoding所指示的编码转化为二进制,写入到文件中
file=open("aaa.txt",mode="w",encoding="utf-8")
file.write("今朝有酒今朝醉")
file.close()
"""
"""
#读取硬盘上的二进制进内存,将二进制按照encoding的编码,转换成字符串
file=open("aaa.txt",mode="r",encoding="utf-8")
data=file.read()
file.close()
"""
#rb 直接读取二进制
"""
file=open("aaa.txt",mode="rb")
show=file.read()
print(show) #b'xe4xbdxa0xe5xa5xbdxe6xa3x92'
#可以发现读取的是2进制,表现出来的是16进制(可以发现都带x,这代表的就是16进制,这是为了方便表示二进制)
file.close()
"""
#wb 直接写入二进制
"""
file=open("aaa.txt",mode="wb")
#file.write("你好") #TypeError: a bytes-like object is required, not 'str'
#报错,显示不能直接写入字符串,只能以二进制的形式写入
#所以最好先将要写入的字符转换成二进制encode(),再将二进制写入文件中
data="你好棒"
content=data.encode("utf-8") #以utf-8的编码形式,将字符串转换成二进制
file.write(content) #写入二进制
file.close()
"""
#ab 直接追加二进制
#一般对于图片/音频/视频/未知编码,常用rb/wb/ab
字符串转二进制 encode()
二进制转字符串 decode()
4.9文件的修改
with open("aaa.txt",mode="r",encoding="utf-8") as f1:
data=f1.read()
#只能将文件读取到内存中修改
new_data=data.replace("酒","牛奶")
#将文件从内存重新写到硬盘中
with open("aaa.txt",mode="w",encoding="utf-8") as f1:
f1.write(new_data)