零. 在用scrapy爬取数据中,有写是通过js返回的数据,如果我们每个都要获取,那就会相当麻烦,而且查看源码也看不到数据的,所以能不能像浏览器一样去操作他呢?
所以有了->
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。Selenium 测试可以在 Windows、Linux 和 Macintosh上的 Internet Explorer、Chrome和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。
一.http://selenium-python.readthedocs.io/installation.html
下载谷歌浏览器模拟
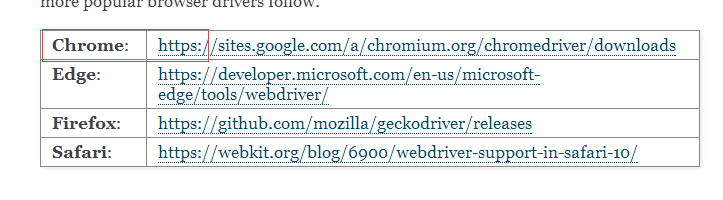
二.安装selenium
pip install selenium
from selenium import webdriver
from scrapy.selector import Selector
browser = webdriver.Chrome(executable_path="F:/GitHub/python/chromedriver_win32/chromedriver.exe");
browser.get("https://detail.tmall.com/item.htm?spm=a222t.8063993.4308149192.1.4d1c4546jqNJNV&acm=lb-zebra-164656-978500.1003.4.3165043&id=566510433862&scm=1003.4.lb-zebra-164656-978500.OTHER_222_3165043&scene=taobao_shop&sku_properties=10004:653780895;5919063:6536025")
print(browser.page_source)
t_selector = Selector(text=browser.page_source)
ttt = t_selector.xpath('//*[@class="tm-price"]//text()').extract()
print(ttt)
browser.quit();
模拟访问淘宝
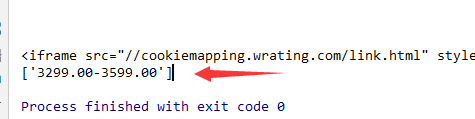
OK! 拿到了淘宝的商品价格了!