引言
定位:查询数据库得到的结果集乱码,client端向数据库插入数据乱码。
网上有不少帖子,手把手地教给我们如何去改这一问题。方案大多数如下:
方案中最多介绍的就是更改配置文件,win下
my.ini、Linux下my.cnf# Win下 my.ini 有的默认被注释掉,只需要去掉注释就可以
#在[client]下追加:
default-character-set=utf8
#在[mysqld]下追加:
character-set-server=utf8
#在[mysql]下追加:
default-character-set=utf8
# Linux下,这里就有所不同,每个人当初安装MySQL的方式,添加的my.cnf
#是否是用的官网模板还是网上复制的内容填充的,但是方式要添加的内容和win
#大同小异,如果当初指定了相应的默认字符集就无需指定字符集。
#【注】无论是my.ini还是my.cnf里面的mysql相关的配置项一定要在所属的组下面,
比如default-character-set就只能放在[mysql]/[client],不能放在[mysqld]下,
不然会导致mysql服务启动失败,可能如下:
#[Error]start Starting MySQL .. The server quit without updating PID file
# 所以说mysql服务起不来了,可能是配置文件出现了问题其实最关键的一项是
[mysqld] character-set-server=utf8,其它两项,对于my.cnf只需要追加[mysql] character-set-server=utf8就可以改变character_set_client、character_set_connection、character_set_results这三项的值,这三项代表是什么意思,别急,后面会有介绍。如果是利用JDBC连接mysql时出现的乱码,大致的步骤会有:
更改上面所讲的配置文件、更改数据库编码、更改表编码、添加在连接数据库的url地址上添加后缀
?useUnicode=true&characterEncoding=xxx等等,有的同学一顿猛改,挨个尝试,最终还是乱码还是没有解决,然而有的同学运气就比较好,改完数据库编码乱码问题就解决了。但是回过头来想想是哪个地方改好的,为什么这样改就OK,就有点摸不着头脑了,下次遇到同样的…所以有时候抓住事物的根源就能举一反三。
如果你有和我上面所说的同样的困惑,那么请继续往下探索,文章有点长,但阅过之后相信你一定会有所收获。如果我哪里说的不对或者有错,请一定不吝赐教。
character_set_client/connection/results变量
首先附一张图,帮助下面更好地理解。
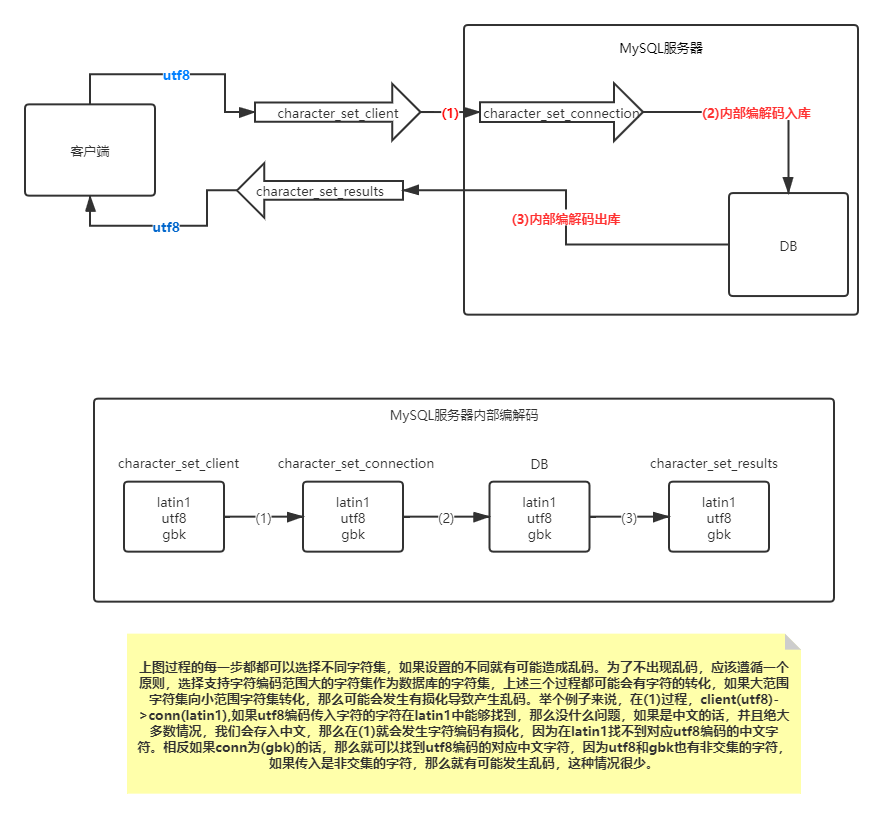
1. 三个变量的含义及作用
- character_set_client:客户端发送的sql语句编码字符集。它的作用就是告诉mysql服务器,本地客户端采用了什么编码环境。
insert into t values('吴');,服务器知道这条sql是以character_set_client指定的字符集所编码的,'吴'将被转化为指定的编码格式,比如它的utf8编码为E590B4,最终以0101…发送到server。 - character_set_connection:服务器将接收到的character_set_client指定编码的sql语句翻译成character_set_connection指定编码的sql。也有不少帖子谈到该变量是否有用,为什么要设置这个中间变量,直接把sql执行入库,为什么还要转化,在这里不争论这一个。
- character_set_results:指示了服务器将查询结果返回给客户端的字符集。服务器检索库表之后,需根据该变量的值将查询结果的字符集转化为character_set_results所指定的字符集。
关于这三个变量,MySQL在官网也提到:
Every client has session-specific connection-related character set and collation system variables. These session system variable values are initialized at connect time, but can be changed within the session.
每个客户端或者终端在连接上server之后,都有自己特定的系统变量,服务器默认采用客户端的本地化参数初始化系统变量的值,并且在本次会话中可以动态改变其值。Linux下的shell和win下的dos在连接到server之后,本地化参数可能存在差异(编码格式),上面三个变量在不同终端下值的不同就是最好的验证。可以看下面截图。
【注】*当character_set_client、character_set_connection值相同时,也不会发生编解码。
2. 乱码课代表 "?"、火星文"å ½…"
打开任意客户终端,连接mysql,之后执行show variables like 'character_set%',就可以查看这三个变量的值,乱码问题最大程度上是由这三个变量和数据库字符集的配置,乱码的根源就是编解码操作。下面我展示了四个client终端在执行完命令之后的截图。【我这里的MySQL服务器是安装在ALi的ECS服务器上,这里三个终端所连接的都是同一个mysql服务器】
Linux:
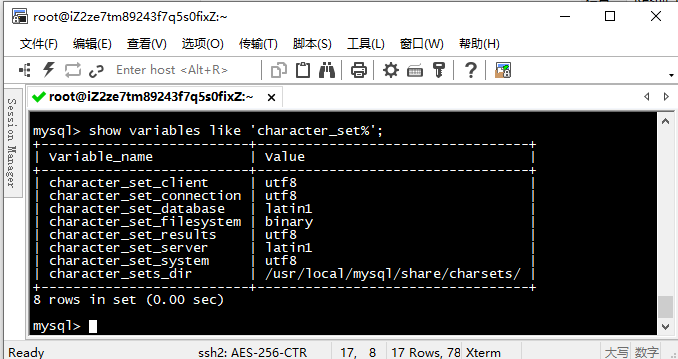
win->cmd命令窗口远程连接Linux服务器上的MySQL:

Navicate终端下连接:
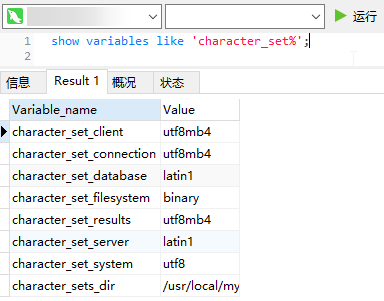
IDEA下利用JDBC连接数据库后查询到的结果,注意,为了试验,url后面不要跟具体的数据库名,只要mysql的地址和端口就可以,因为variables有global和session两个范围,这里采用默认查询session级别。
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://192.168.0.1:3306", "***", "***");
PreparedStatement ps = connection.prepareStatement(" show variables like 'character_set%';");
ps.execute();
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
//| Variable_name | Value
System.out.println(resultSet.getString("Variable_name"));
System.out.println(resultSet.getString("Value"));
}
/*
输出
character_set_client
latin1
character_set_connection
latin1
character_set_database
latin1
character_set_filesystem
binary
character_set_results
character_set_server
latin1
character_set_system
utf8
character_sets_dir
/usr/local/mysql/share/charsets/
*/
}
请仔细观察这三个变量:
character_set_client、character_set_connection、character_set_results
这三个变量在不同的终端可能有不一样的值,比如dos下和Linux下。但是每一个终端下这三个变量的值默认情况下是相同的,dos下是三个变量值全为gbk,Linux下全为utf8。
1、乱码复现,从最小的latin1字符集说起
latin1编码(字符集),所占空间大小1字节,编码范围0~255,使用了ASCII码的高位1,在ASCII基础上扩展了128个字符,扩展的128个字符,大致看了一下都是火星文,看不懂。尽管一个utf8的字符映射到latin1上会出现乱码,但这不能否定latin1就不能存放utf8的数据,或者说用latin1存放utf8的字符查询后肯定会乱码,这不是绝对的,下面会有示例。
# 为了看出效果,将三个变量值统一
mysql> set names "latin1";
mysql> show variables like 'character_set%';
+--------------------------+----------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/charsets/ |
+--------------------------+----------------------------------+
# 创建数据库,默认字符集为latin1,继承了server的字符集
mysql> create database db;
# 查看数据库结构
mysql> show create database db;
+----------+-------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------+
| db | CREATE DATABASE `db` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+----------+-------------------------------------------------------------+
# 选中新建的库
mysql> use db;
mysql> create table t(t varchar(30));
#表的字符集默认继承自db,db又继承server
mysql> show create table t;
+-------+------------+
| Table | Create Table
+-------+--------------+
| t | CREATE TABLE `t` (
`t` varchar(30) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1|
+-------+----------+
# 查看表字段字符集
mysql> show full columns from tG;
*************************** 1. row ***************************
Field: t
Type: varchar(30)
Collation: latin1_swedish_ci
Null: YES
Key:
Default: NULL
Extra:
Privileges: select,insert,update,references
Comment:
# 插入一条英文和中文信息
mysql> insert into t values('wu'),('吴');
mysql> select *,hex(t),length(t) from t;
+------+--------+-----------+
| t | hex(t) | length(t) |
+------+--------+-----------+
| wu | 7775 | 2 |
| 吴 | E590B4 | 3 |
+------+--------+-----------+
数据库表字段字符集为latin1,character_client/connection/results这三个变量的值也为latin1,一个没有中文字符的latin1字符集竟然能存储中文并且还能把数据完好无损的展示出来,其实数据底层编码没有受损,如果数据编码过程中受损,我们看到的就不是这样的了,况且上面hex(t)字符编码也显示了数据并没有受损。我们看下流程:
[1] [2] [3] [4]
shell--->吴-utf8->"E590B4"--->client(latin1)--->conn(latin1)--->DB
# insert执行过程:
# 客户端发出插入字符的命令,server检查character_set_client,知道客户端使用latin1作为编码集,
其实我们欺骗了server服务器,因为在没有执行set names "latin1"之前,character_set_client是utf8
即是shell本地环境下的字符编码。server检查character_set_conn,和set_client相同,[1]->[2]过程
传递的"E590B4"不会发生编码解码转化等问题,[3]->[4]属于数据库内部操作了,检查conn是否和数
据库编码集相同,这里是相同的,按照latin1格式,以字节流写入硬盘.
# 分析:【输入】
# shell通过set names "latin1"欺骗了server,让server以为我们本地的编码是latin1格式,本来
字符"吴"在shell中是以utf8格式的单字符3字节中文存在,在server中是认为是以latin1编码的
字符(转化为latin1是这个样子"å ´") ,3字符3字节的形式存在,因为在[2]->[3]->[4]中流转,
没有发生编码转换,也没有字符损失,只不过server中认为的"E590B4"和shell中认为的"E590B4"
语义不同,latin1最终还是能存储下这一串字符编码.
[5] [6] [7]
DB-->results(latin1)-->"E590B4"-->utf8-->shell-->“吴”
# 分析:【输出】
# [5]->[6]数据库内部没有发生有损化编码,成功的将“E590B4”带到shell之前,因为shell编
码是utf8,不要忽略shell格式的编码,正是因为它,才将格式复原。因为results当初设置
的是latin1,最终是以latin1格式返回,这时shell就认为这是一个utf8编码的字符,它有被欺
骗了,就会按照utf8格式来划分字符,“E590B4”又被当做3字节一字符进行了utf8编码,
最终复原.
在终端中执行set names 'utf8';;将编码格式改为shell默认的本地化参数,然后执行查询,乱码出现
mysql> set names "utf8";
# 乱码出现
mysql> select *,hex(t),length(t) from t;
+--------+--------+-----------+
| t | hex(t) | length(t) |
+--------+--------+-----------+
| wu | 7775 | 2 |
| å´ | E590B4 | 3 |
+--------+--------+-----------+
出现乱码,肯定是编解码出现了错误,出现编解码错误的过程发生在了[5]->[6],这时的[5]->[6]不在是上面的了
[5] [6] [7]
DB(latin1)-->results(utf8)-->"E590B4"-->utf8-->shell-->“吴”
# DB内部到character_set_results编解码的过程发生了错误,也不能说是错误吧,因为[5]->[6]
就是正常的latin1->utf8格式的转化,utf8的字符集包含latin1,latin1的字符都能在utf8中找到
相应的字符,“E590B4"latin1编码表示"å ´"(三字符),(utf8>latin1)无损转化,转为utf8也是"å ´"(三字符),
这里语义就发生了变化,不在是utf8当初认为的单字符3字节了,显示在shell中就是火星文了
接下来又会看到另一个熟悉的朋友(?)。
在上述操作的基础上,client、conn、results都为utf8,数据库表字段为latin1的格式下,插入一条数据
如果插入数据报错,改下sql_mode模式:
set sql_mode="";
mysql> insert into t values('吴');
Query OK, 1 row affected, 1 warning (0.01 sec)
# mysql这时候给出提示如下,说明字符在编码的时候遇到了冲突
mysql> show warnings;
+---------+------+----------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------+
| Warning | 1366 | Incorrect string value: 'xE5x90xB4' for column 't' at row 1 |
+---------+------+----------------------------------------------------------------+
# 熟悉的老盆友“?”出现
mysql> select *,hex(t),length(t) from t;
+--------+--------+-----------+
| t | hex(t) | length(t) |
+--------+--------+-----------+
| wu | 7775 | 2 |
| å´ | E590B4 | 3 |
| ? | 3F | 1 |
+--------+--------+-----------+
3 rows in set (0.00 sec)
插入数据结果为"?"乱码,warnings警告也有一个提示,上述过程的编解码错误出现在向DB中转换存数据的过程中
[1] [2] [3] [4]
shell--->吴-utf8->"E590B4"--->client(utf8)--->conn(utf8)--->DB(latin1)
# [3]->[4]server内部字符集编解码,将数据整合到库中
# utf8->laint1 [我的猜想,如有错误,请不吝指出]
# 大的方面想,在latin1中找不到一个字符为"吴"且值为"E590B4"的字符,并且utf8是
单字符3字节,这3字节单字符的范围是latin1所不能解析的,因为latin1只能处理单字
符1字节,所以会有 Incorrect string value: 'xE5x90xB4' for column 't' at row 1 提示。
latin1不知道插入的是什么字符,最终会以问号代替所插入的字符。无论改变set names "latin1"还
是其他字符集查询,最终结果不变,"?"是挥之不去的了,因为他是以最小
字符集latin1格式保存在了库中,他就是一个"?"。
接着,改变character_set_client=latin1;,插入数据看效果。
mysql> set character_set_client=latin1;
mysql> show variables like 'character_set%';
+--------------------------+----------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------+
| character_set_client | latin1 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/charsets/ |
+--------------------------+----------------------------------+
8 rows in set (0.01 sec)
mysql> insert into t values('吴');
Query OK, 1 row affected (0.01 sec)
# 出现了和当初在latin1的环境下,插入数据之后查询显示无乱码,
后来set names "utf8";之后查询的乱码一样,对应表中第二条记录
mysql> select *,hex(t),length(t) from t;
+--------+--------+-----------+
| t | hex(t) | length(t) |
+--------+--------+-----------+
| wu | 7775 | 2 |
| å´ | E590B4 | 3 |[1]
| ? | 3F | 1 |
| å´ | E590B4 | 3 |[2]
+--------+--------+-----------+
这次出现乱码的错误转化逻辑发生在[2]->[3]处,其实之前说的编解码错误,并不能以偏概全,像出现Incorrect说明真正的出现了编解码错误,其他的插入数据并没有warnings,就不能这样说了,其实它编解码本来无误,只不过语义变化了,本来是单字符3字节,却被按照单字符单字节解析,底层数据没有遭到破坏,只是再次重组底层编码的时候就不一样了。
[1] [2] [3] [4]
shell--->吴-utf8->"E590B4"--->client(latin1)--->conn(utf8)--->DB(latin1)
# latin1->utf8 [2] -> [3]
# set character_set_results=latin1欺骗服务器说自己的本地编码为latin1,
E590B4就会按照latin1编码解析,latin1->utf8是无损转化的,单字节单字符
就一定会在utf8中找到一个相应的字符,这是mysql服务器内部帮我们做的,
mysql服务器所做,mysql服务器所做,[3]->[4]过程,mysql再次对字符进
行编解码,因为这时候的utf8实际就是latin1的值 "å ´",这时候就能够找到
在latin1中对应的字符,查询输出的也就是看到的"å ´"
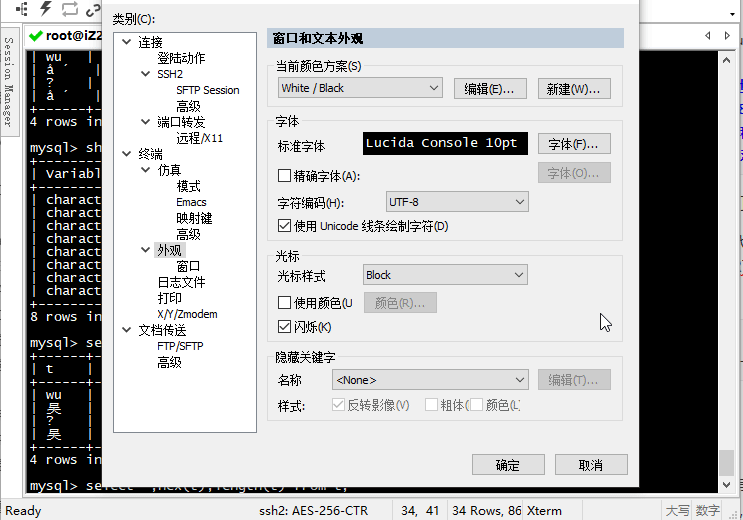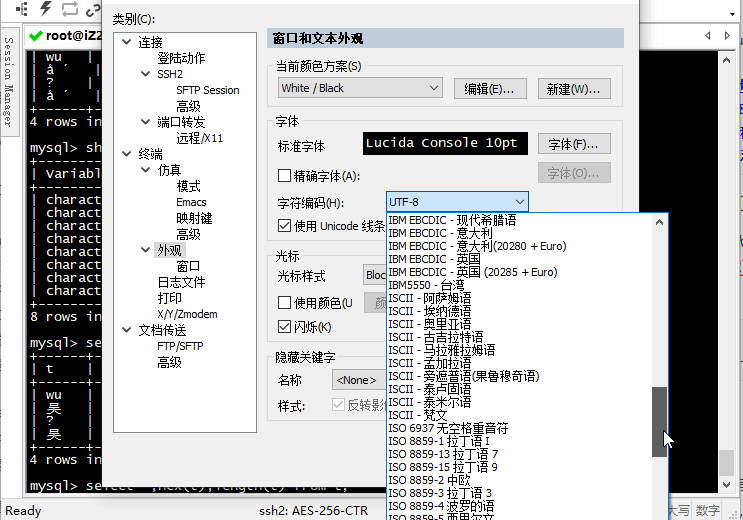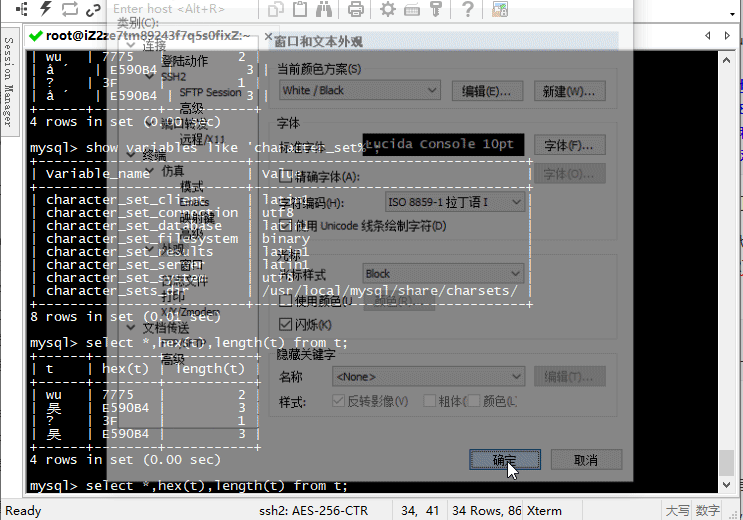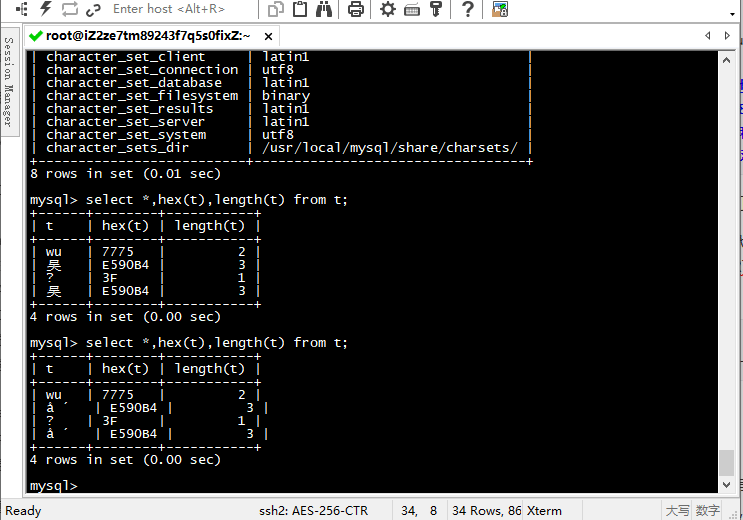
但是只要执行一句set character_set_results=latin1;[1]、[2]就会显示原中文字符。字符又现行了。
这个过程就是对应的[5]、[6]、[7],注意语义,在[7]之前“E590B4”代表的是"å ´",并不是“吴”,在[7]后,shell自动将"E590B4"重组的,这不是mysql所做。将远程连接工具 SecureCRT会话选项的字符集改为"ISO-8859-1(拉丁语)"之后,就会看到本来的"å ´",如下图。
[5] [6] [7]
DB(latin1)-->results(utf8)-->"E590B4"-->utf8-->shell-->“吴”
next,set names 'utf8'回到查询乱码态,接下来我们让conn为latin1,插入数据看结果
mysql> set character_set_connection=latin1;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t values('吴');
Query OK, 1 row affected, 1 warning (0.01 sec)
# 同样插入之后出现了警告,这时候编码肯定受损
mysql> select *,hex(t),length(t) from t;
+--------+--------+-----------+
| t | hex(t) | length(t) |
+--------+--------+-----------+
| wu | 7775 | 2 |
| å´ | E590B4 | 3 |
| ? | 3F | 1 |[3]
| å´ | E590B4 | 3 |
| ? | 3F | 1 |[4]
+--------+--------+-----------+
这次插入出现的错误在过程[2]->[3],看到这,应该也能分析出来个大概了吧,举一反三了吧
[1] [2] [3] [4]
shell--->吴-utf8->"E590B4"--->client(utf8)--->conn(latin1)--->DB(latin1)
# [2]->[3]mysql服务器内部转化,没有在latin1中找到[2]utf8格式的相应
字符,给出warning,sql_mode为严格模式下是给予错误提示.
3. JDBC的特殊处
为什么jdbc连接mysql的url后面加useUnicode=true&characterEncoding=utf8可以解决乱码呢?
The character encoding between client and server is automatically detected upon connection (provided that the Connector/J connection properties
characterEncodingandconnectionCollationare not set). You specify the encoding on the server using the system variablecharacter_set_server(for more information, see Server Character Set and Collation). The driver automatically uses the encoding specified by the server.To override the automatically detected encoding on the client side, use the
characterEncodingproperty in the connection URL to the server. Use Java-style names when specifying character encodings. The following table lists MySQL character set names and their corresponding Java-style names:
client在与server连接时,MySQL会自动检测客户与服务器之间的编码集,如果客户端没有指定characterEncoding 属性,那么client与服务器之间的连接就会使用character_set_server的值来初始化之前client_conn_results三个变量的值。如果指定了,则用characterEncoding 初始化。
在shell不改动默认编码(utf-8)下,数据库表字段字符集为latin1,character_client/connection/results这三个变量的值也为latin1时,查询到的结果是没有乱码的,最终会被shell正常解析。JDBC又有所不同了,插入查询都是乱码,结果为什么没有被idea所矫正?之前shell就能够自动重组字符,idea难道是个智障?
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:mysql://***/db1", "***", "***");
PreparedStatement ps = connection.prepareStatement(" select * from t");
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString("t"));
}
}
/* 输出
wu
�
?
�
?
*/
其实这与idea无关,字符编解码的事情是由本地的JDBC来做的,JDBC在本地完成解析后,idea才显示的
# shell
DB(latin1)-->results(latin1)--"E590B4"-->shell按照utf8格式解析
# jdbc
DB(latin1)-->results(latin1)--"E590B4"-->jdbc按照latin1格式解析完毕[1]--->idea显
示字符串,jdbc是在本地客户端解析的,所以说idea就不会像shell那样,强制重组,
jdbc在本地帮我们做好了,它只会将结果以latin1->utf8字符映射的方式显示。
# 在插入的时候也会提前将字符串以指定字符集编码化
尝试向数据库中插入一条记录,查询插入的结果是一个问号“?”,说明了在本地,
jdbc在将字符串转到latin1的时候就发生了编码错误,latin1中找不到utf8指定的字符,[1]->[2]编码损失。
[1] [2]
idea(utf8)->jdbc(latin1)->client(latin1)->conn(latin1)->DB
# 总:jdbc编解码的过程有一部分是在本地完成的
总结
1、一般为了避免乱码,应该将数据库中的字符集设置为utf8,因为utf8是unicode的中编码方式,unicode字符集包含世界上所有的字符,通过utf8可以实现gbk<->utf8字符的映射,当然不是所有的都能映射成功,只有那些我们连见都没见的古文或者其他不常见的字可能映射失败。
2、mysql的乱码情况主要有,底层数据编码没有受损,显示乱码,这种一般是在编解码的过程中语义发生了变化所导致的;另一种是编解码已经受损,在shell插入数据的时候受损后会有一个waring警告。常见的就是"?",这种情况,无论设置何种字符集,都会显示"?"。区分编解码语义的变化,根据mysql内部进行编解码还是外部进行编解码来判断,内部编解码主要是找相应的字符映射,外部则是重组,另外,JDBC有一部分编解码在本地完成。
思考,变化三个变量的值和库表字段编码,组合实验,尝试推断结果。
本文参考