平时除了遇到二分类问题,碰到最多的就是多分类问题,例如我们发布blogs时候选择的tag等。如果每个样本只关联一个标签则是单标签多分类,如果每个样本可以关联多个样本,则是多标签多分类。今天我们来看下新闻的多分类问题。
一、数据集
这里使用路透社在1986年发布的数据集,它包含很多的短新闻及其对应的主题,它包含46个主题,是一个简单的被广泛使用的分类数据集。
def load_data(self):
return reuters.load_data(num_words=self.num_words)
(train_data, train_labels), (test_data, test_labels) = self.load_data()
print(len(train_data))
print(len(test_data))
print(train_data[0])
print(train_labels[0])
可以看到有8982个训练样本及2246个测试样本,同时也可以看到第一个训练样本的内容和标签都是数字。
8982
2246
[1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 3095, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 4579, 1005, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 1245, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12]
3
看下第一个训练样本的实际内容
def get_text(self, data):
word_id_index = reuters.get_word_index()
id_word_index = dict([(id, value) for (value, id) in word_id_index.items()])
return ' '.join([id_word_index.get(i - 3, '?') for i in data])
print(self.get_text(train_data[0]))
执行后的样本内容
? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3
二、数据格式化
使用one-hot方式编码训练数据
def vectorize_sequences(self, sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i,sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
self.x_train = x_train = self.vectorize_sequences(train_data)
self.x_test = x_test = self.vectorize_sequences(test_data)
编码标签数据
def to_one_hot(self, labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i,label in enumerate(labels):
results[i, label] = 1
return results
self.one_hot_train_labels = one_hot_train_labels = self.to_one_hot(train_labels)
self.one_hot_test_labels = one_hot_test_labels = self.to_one_hot(test_labels)
三、构建模型
这里有46个新闻类别,所以中间层的维度不能太少,否则丢失的信息太多,这里我们使用64个隐藏单元。
model = self.model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics='accuracy')
最后一层输出是46个维度的向量,每个维度代码样本属于对应分类的概率。
这里使用便于计算两个概率分布距离的分类交叉熵作为损失函数。
四、校验模型
从训练集中保留一部分作为校验数据集。
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
还是以512个样本作为一个小的批次,训练20轮。
history = model.fit(partial_x_train, partial_y_train, epochs=self.epochs, batch_size=512, validation_data=(x_val, y_val))
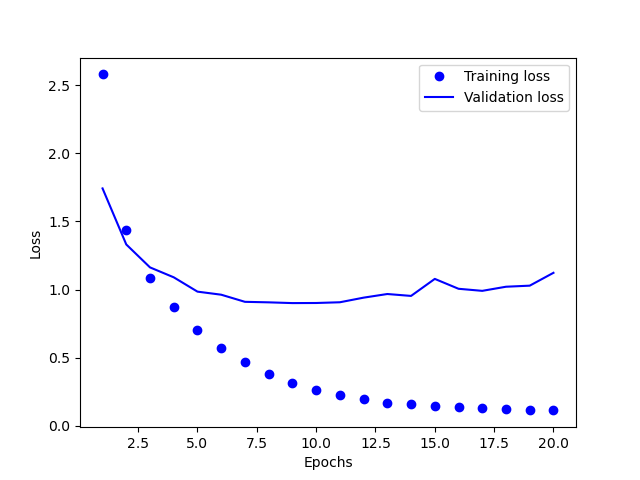
绘制损失曲线图
def plt_loss(self, history):
plt.clf()
loss = history.histroy['loss']
val_loss = history.histroy['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
绘制准确度曲线
def plt_accuracy(self, history):
plt.clf()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()

从图中可以看到训练到第九轮之后开始出现过拟合,改为9轮进行训练模型,并在测试机上评估模型。
def evaluate(self):
results = self.model.evaluate(self.x_test, self.one_hot_test_labels)
print('evaluate test data:')
print(results)
最终训练之后精度可以达到79%。
evaluate test data:
[0.9847680330276489, 0.7925200462341309]
五、总结
- 网络最后一层的大小应该跟类别的数量保持一致;
- 单标签多分类问题,最后一层需要使用softmax激活函数,方便输出概率分布。
- 单标签多分类问题,需要使用分类交叉熵作为损失函数。
- 中间层的维度不能小于输出标签数量。
from tensorflow.keras.datasets import reuters
import numpy as np
from tensorflow.keras import models
from tensorflow.keras import layers
import matplotlib.pyplot as plt
class MultiClassifier:
def __init__(self, num_words, epochs):
self.num_words = num_words
self.epochs = epochs
self.model = None
self.eval = False if epochs == 20 else True
def load_data(self):
return reuters.load_data(num_words=self.num_words)
def get_text(self, data):
word_id_index = reuters.get_word_index()
id_word_index = dict([(id, value) for (value, id) in word_id_index.items()])
return ' '.join([id_word_index.get(i - 3, '?') for i in data])
def vectorize_sequences(self, sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i,sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
def to_one_hot(self, labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i,label in enumerate(labels):
results[i, label] = 1
return results
def plt_loss(self, history):
plt.clf()
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
def plt_accuracy(self, history):
plt.clf()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
def evaluate(self):
results = self.model.evaluate(self.x_test, self.one_hot_test_labels)
print('evaluate test data:')
print(results)
def train(self):
(train_data, train_labels), (test_data, test_labels) = self.load_data()
print(len(train_data))
print(len(test_data))
print(train_data[0])
print(train_labels[0])
print(self.get_text(train_data[0]))
self.x_train = x_train = self.vectorize_sequences(train_data)
self.x_test = x_test = self.vectorize_sequences(test_data)
self.one_hot_train_labels = one_hot_train_labels = self.to_one_hot(train_labels)
self.one_hot_test_labels = one_hot_test_labels = self.to_one_hot(test_labels)
model = self.model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics='accuracy')
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
history = model.fit(partial_x_train, partial_y_train, epochs=self.epochs, batch_size=512, validation_data=(x_val, y_val))
if self.eval:
self.evaluate()
print(self.model.predict(x_test))
else:
self.plt_loss(history)
self.plt_accuracy(history)
classifier = MultiClassifier(num_words=10000, epochs=20)
# classifier = MultiClassifier(num_words=10000, epochs=9)
classifier.train()