一、序列化
1.正则表达式 创建表
//在加载文件时可以通过正则表达式来区分字段,字段名必须和文件中的字段名一致 create table reg_table( id int, name string ) row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties('input.regex'="id=(.*),name=(.*)"); //.代表单个字符 * 0~N次 //加载数据 load data local inpath '/usr/local/hive_data/regexp_test' overwrite into table reg_table;
2.通过json文件创建表
//创建user用户数据的指定JSON的序列化器 create table user_json_textfile( uid string, phone string, addr string ) row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';//这个类名是固定的 //加载数据 load data local inpath '/usr/local/xl_project/user/user_login_info.json' overwrite into table user_json_textfile;
需要注意的问题: 每行必须是一个完整的JSON,一个JSON串不能跨 越多行,原因是Hadoop是依赖换行符分割文件的。
创建数据表:(数据表中的列名与JSON中的KEY保持一致)
3.什么是SerDe:
SerDe是“Serializer and Deserializer”(序列化器和反序列化器的缩写)
Hive使用SerDe读写表的行数据
HDFS FILES-->InputFileFormat--><key,value>-->Deserializer--> Row Object
Row Object-->Serializer--><key,value>-->OutputFileFormat-->HDFS FILES
注意,“key”部分在读时被忽略,在写时始终是常量。基本上,row对象存储在value中
序列化是对象转换为字节序列的过程。 反序列化是字节序列恢复为对象的过程。 对象的序列化主要有两种用途:对象的持久化,即把对象转换成字节序列后保存到文件中;对象数据的网络传送。 除了上面两点, hive的序列化的作用还包括:Hive的反序列化是对key/value反序列化成hive table的每个列的值。Hive可以方便的将数据加载到表中而不需要对数据进行转换,这样在处理海量数据时可以节省大量的时间。
SerDe说明hive如何去处理一条记录,包括Serialize/Deserilize两个功能, Serialize把hive使用的java object转换成能写入hdfs的字节序列,或者其他系统能识别的流文件。Deserilize把字符串或者二进制流转换成hive能识别的java object对象。比如:select语句会用到Serialize对象, 把hdfs数据解析出来;insert语句会使用Deserilize,数据写入hdfs系统,需要把数据序列化。
Hive的一个原则是Hive不拥有HDFS文件格式。用户应该能够使用其他工具直接读取Hive表的HDFS文件或者使用其他工具直接写那些可以加载到外部表中的HDFS文件。
二、文件存储
1.文件格式的分类
hive文件的存储格式主要分为以下四种: TEXTFILE、SEQUENCEFILE、RCFILE、ORCFILE
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时直接把数据文 件COPY到HDFS上不进行处理。
SEQUENCEFILE、RCFILE、ORCFILE格式的表不能直接从本地文件导入数据,数据要 先导入到textfile格式的表中,然后再从表中用insert导入SequenceFile,RcFile和 OrcFile中。
2.TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时解压),但使用这种方式, hive默认对数据不会切分,从而无法对数据进行并行操作。
在反序列化的过程中,必须逐个字符判断是不是分隔符或行终止符,因此反序列化 开销最大。
3.SEQUENCEFILE格式
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以二进制的形 式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口 实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中 的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使 用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。
4.RCFILE
是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
5.ORCFILE格式
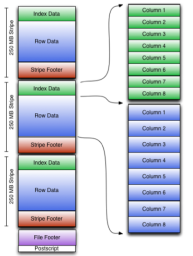
Orcfile(Optimized Row Columnar)是hive 0.11版里引入的新的存储格式, 是 对之前的RCFile存储格式的优化。可以看到每个Orc文件由1个或多个stripe(线条)组成,每个stripe250MB大小, 这个Stripe实际相当于之前的rcfile里的RowGroup概念,不过大小由 4MB->250MB, 这样应该能提升顺序读的吞吐率。每个Stripe里有三部分组成,分 别是IndexData,Row Data,Stripe Footer:
1、Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
2、Row Data:存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储。与RCfile不同的地方在于每个列进行了编码,分成多个Stream来存储
3、Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
6.总结
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高。
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 需要通过text文件 转化来加载。
rcfile 存储空间小,查询的效率高 ,需要通过text文件转化来加载,加载的速度最低
orcfile 存储空间最小,查询的最高 ,需要通过text文件转化来加载,加载的速度最低。
三、分区
1.什么是分区
hive开发中,在存储数据时,为了更快地查询数据和更好地管理数据,都会对hive 表中数据进行分区存储。所谓的分区,在hive表中体现的是多了一个字段。而在底 层文件存储系统中,比如HDFS上,分区则是一个文件夹,或者说是一个文件目录, 不同的分区,就是数据存放在根目录下的不同子目录里,可以通过show partitions查看。
查看分区
show partitions
2.动态和静态分区
创建分区(无论动态还是静态分区创建语句是不变的只有插入语句变化)
//创建一个按照年份分区的表 create table test_partition ( id string comment 'ID', name string comment '名字' ) comment '测试分区' partitioned by (year int comment '年') ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
静态分区
#insert语句: insert into table test_partition partition(year=2018) values ('001','张三'); insert into table test_partition partition(year=2018) values ('001','张三'); insert into table test_partition partition(year=2018) values ('002','李四'); #load语句 load data local inpath '/usr/local/part_test' into table test_partition partition (year =2018); load data local inpath '/usr/local/part_test' into table test_partition partition (year =2018); load data local inpath '/usr/local/part_test' into table test_partition partition (year =2017); //要加载的文件为 002,李四 003,王五 003,王五
动态分区
//动态分区默认不开启,需要使用下列语句开启: set hive.exec.dynamic.partition.mode=nonstrict;#需退出hive,重新进入执行 // insert语句数据插入: insert into table test_partition partition(year) values ('001','张三',2016); //load语句插入: load data local inpath '/usr/local/part_test' into table test_partition partition (year); FAILED: NullPointerException null 报错 //在这里没有为分区字段赋任何值,所以会抛出NullPointerException这样的异常,可以使用下面的办法解决: 创建一张没有分区的表: create table test ( id string comment 'ID', name string comment '名字', year int comment '年' )comment '测试' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ; //将数据载入到没有分区的表中: load data local inpath '/usr/local/part_test' into table test; // 然后从表test,动态分区的插入到test_partition中: insert into table test_partition partition(year) select * from test;
删除修改分区
1、修改分区 alter table 表名 partition (分区列=分区值) set location 新分区地址; 注意:此时原先的分区文件夹仍存在,但是在往分区添加数据时,只会添加到新的分区目录。 2、删除分区 alter table 表名 drop partition(分区列=分区值);
静态分区和动态分区的区别
静态分区和动态分区的主要区别在与:
静态分区中的数据需要手动指定,当分区列的值有很多的情况下,就要不停的 使用INSERT语句进行显示指定。
动态分区:可通过SELECT语句实现数据的一次性导入,而且可以通过数据源中 不同分区列的值动态的生成相应的目录,并把对应的数据写入对应的目录中。
简单的来说:静态分区是给与固定的值,而动态分区可实现分区数据的动态指定
四、分桶
1.什么是分桶
分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得 hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash 值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文 件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。(放置分桶的内容不能自定义,只能通过hashcode的值来进行)
2.分桶和分区的区别
分区针对的是数据存储路径(HDFS中表现出来的便是文件夹),分桶针对的是数据文件。分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区,特别是当数据要确定合适的划分大小的时候,分区便不再合适。分桶是将数据集分解成更容易管理的若干部分的技术。
3.怎么用分桶
#创建一个存有id和name的表 create table student_bck (id int, name string) clustered by (id) into 3 buckets #创建三个分桶 row format delimited fields terminated by ",";//设置加载文件的字段分隔符
#向桶中插入数据
insert overwrite table student_bck select id,name from test; //insert将原有表中的数据加载到分桶的表中
#查看桶中的数据
select * from student_bck tablesample (bucket x out of y on id);//x表示从哪个桶(x-1)开始,y代表分几个桶,也可以理解分x为分子,y为分母,及将表分为y份(桶),取第x份(桶)
为何取出王五的记录,是因为王五的记录为3,取模桶数余数为0,所以 理应放置在第一个桶中。当X=1时代表获取的是第一个桶的数据。