最近产品搞安全漏洞修复(由省公安局发文强制要求整改高危漏洞,发起的这项活动)
涉及几个点,必须修改:
①跨站脚本
②请求参数篡改
- 场景 1:表格提交前,通过拦截请求参数,篡改参数后,再发送给服务器
- 场景2:修改个人信息时,通过拦截响应数据,篡改响应结果后,再返回给客户端(即前端验证不正确,结果返回是正确的,于是成功进入修改页面)
③加密传输
用户在登录后,涉及需要传输密码的地方,需要加密传输
④防伪造登录
在整改后,先手动验证了,最后用APPscan扫描:
- fiddler拦截请求 及 响应数据
场景1,可以通过fiddler抓包工具,拦截requests 的数据,再发给服务器,并篡改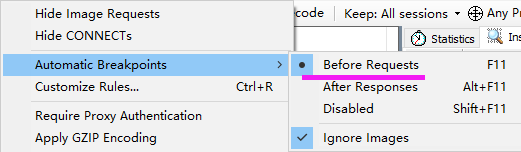
场景2,可以通过fiddler抓包工具,拦截responses返回的数据,篡改后,返回前端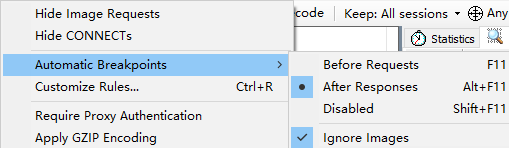
=====================================================================
- APPscan扫描

APPSCAN的登录方法,根据实际需要选择(如:自动),用户名和密码即为被测网站的登录账户,
PS:(如果后面,通过手工探索来录制脚本,在录制过程中,在界面上输入用户名和账号)
1)若登录方法选择“记录”,则可通过界面右侧的“记录(R)”按钮打开APPScan内置浏览器并输入登录信息,关闭内置浏览器后,AppScan即可记录该用户名和密码,扫描的时候相当于是已登录此账户的状态进行扫描;
2)若选择“提示”,则根据网站扫描探索过程中需要登录会提示输入登录信息,人工输入正确的账号信息之后继续扫描;
3)若选择“无”,则不需输入登录账户
===============================
- AppScan使用特别注意事项
【1】AppScan扫描过程中,会向服务器发送较多请求,会占用一定的正常请求访问的资源,可能导致一些垃圾数据,建议只在本地测试环境执行
【2】使用AppScan之前,请提前备份好数据库的数据,假若扫描致使服务器异常关闭,则需重启服务;若扫描产生的请求数据过多,或Web程序出现异常,可能需要从备份数据恢复还原。一般情况下,正常扫描Web程序很少可能出现Web服务异常的情形
【3】AppScan扫描配置时,有区分为Web Application(Web应用程序)和Web Service(Web服务)的扫描方向。若只对Web程序本身的漏洞检测,就选Web Application扫描即可;
若选择Web Service扫描,则需提前告知服务器维护的负责人,建立异常情况发生的处理机制,最好避开访问请求的高峰or办公人员集中使用的时间,比如下班后自动扫描
【4】AppScan扫描的结果并不代表完全真实的情况,受限于所用扫描器版本的漏洞规则库的规则,以及操作者的配置策略,扫描过程中有可能会使得扫描器出现误判or漏测。
如有必要,还需对扫描的结果进行人工校验,可对同一Web应用分次进行扫描对比差异性
【6】使用破解版的AppScan扫描Web应用时,若Web网站本身结构比较复杂、模块众多、涉及的url数目巨大(几万-十多万),
则不宜一次性全站扫描,有可能连续扫描几个小时都不能探索完网站的所有结构。持续时间过长还可能造成AppScan出现卡顿,显示“正在扫描中”,但实际上已经没有继续再扫描。
因此,当第一次探索了大概的网站结构和容量之后,若容量巨大,最好分而治之,按模块结构分批进行扫描测试
【7】结果分析(Analysis)
在APPScan扫描结果基础上,根据不同的严重级别进行排序、手工+工具验证的方式对漏洞验证可靠性,排除误报的情况,并尽可能找出漏报的情况,把本次扫描结果汇总,对以上已验证存在的安全漏洞排列优先级、漏洞威胁程度,并提出每个漏洞的修复建议
然后,再把此次安全漏洞整理的报告提交给项目负责人,由负责人决定哪些漏洞转给开发工程师修复,而后再由安全测试工程师进行回归验证修复的状况
链接:https://www.jianshu.com/p/46e1d026e97f
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
参照:
① https://www.jianshu.com/p/46e1d026e97f APPscan的使用
②https://blog.csdn.net/vikesgao/article/details/7823136 APPscan的工作原理
==========================================================
问题:大佬,用appscan扫描web安全,它攻击时会修改请求的类型吗?
比如啊,一个接口本来是post请求,它按get请求攻击,存在漏洞
解答:接口本来是post,为啥让get也能用,这就是风险点啊