一.模板自带字段
当我们对文档操作时,前三个字段总是不变的
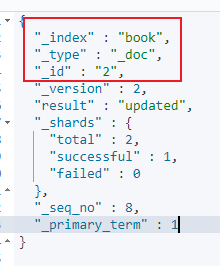
三个字段的含义:
_index:
原则:类似数据放在一个索引中。数据库中表的定义规则。如图书信息放在book索引中,员工信息放在employee索引中。各个索引存储和搜索时互不影响。(不同数据放到不同索引中)
定义规则:英文小写。尽量不要使用特殊字符。
_type:
注意:以后的es9将彻底删除此字段,所以当前版本在不断弱化type。不需要关注。见到_type都为doc。
_id:
含义:文档的唯一标识。就像表的id主键。结合索引可以标识和定义一个文档。
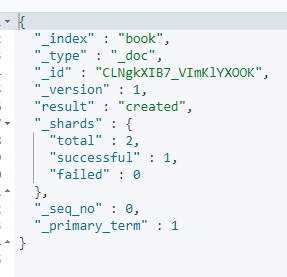
二.文档id的生成方式
1.手动生成:put /index/_doc/id
2.自动生成:put/index/_doc
生成的是20个字符的id,分布式唯一id,base64编码,GUID算法生成。
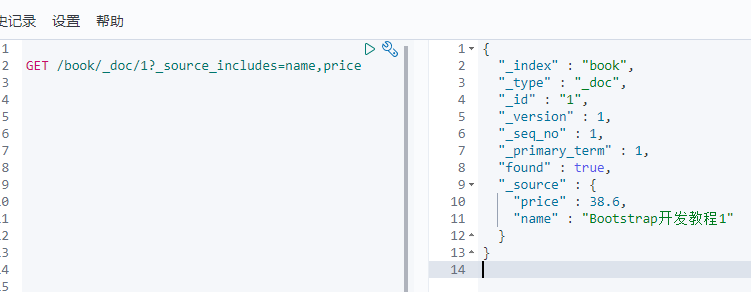
三.定制返回字段
语法:GET /index/type/id?_source_includes=field1,field2...
GET /book/_doc/1?__source_includes=name,price
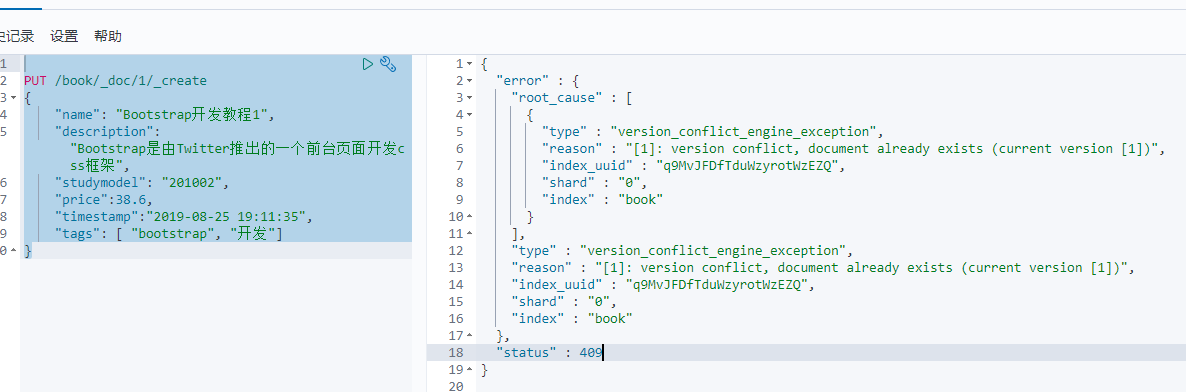
四.文档的替换与删除
1.全量替换:PUT /index/type/id
执行两次,返回结果中版本号(_version)在不断上升。此过程为全量替换。
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
2.为防止覆盖原有数据,我们在新增时,设置为强制创建,不会覆盖原有文档。
语法:PUT /index/type/id/_create
3.删除文档
DELETE /index/_doc/id
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
五.局部替换
原理:1.es内部获取旧文档
2.将传来的文档field更新到旧数据(内存)
3.将就文档标记为delete
4.创建新文档
post /index/type/id/_update
{
"doc": {
"field":"value"
}
}
六.批量查询
post /index/_doc/_search
{
"query": {
"ids" : {
"values" : [id1, id2...]
}
}
}
七.批量增删改 bulk
POST /_bulk
{"action": {"metadata"}}
{"data"}