职友集,搜索到全国上百家招聘网站的最新职位。
打开网址后,你会发现:这是职友集网站的地区企业排行榜,里面含有
本月人气企业榜 前10家公司的招聘信息(公司名称、职位、工作地点和招聘要求)
最佳口碑雇主 前10家公司的招聘信息(公司名称、职位、工作地点和招聘要求)
最多粉丝企业榜 前10家公司的招聘信息(公司名称、职位、工作地点和招聘要求)
最多评论企业榜 前10家公司的招聘信息(公司名称、职位、工作地点和招聘要求)
1、创建 职友网 项目 zhiyou
1 D:USERDATApython>scrapy startproject zhiyou 2 New Scrapy project 'zhiyou', using template directory 'c:userswww1707appdatalocalprogramspythonpython37libsite-packagesscrapy emplatesproject', created in: 3 D:USERDATApythonzhiyou 4 5 You can start your first spider with: 6 cd zhiyou 7 scrapy genspider example example.com 8 9 D:USERDATApython>cd zhiyou 10 11 D:USERDATApythonzhiyou>
2、创建爬虫文件 D:USERDATApythonzhiyouzhiyouspiderszhiyou.py
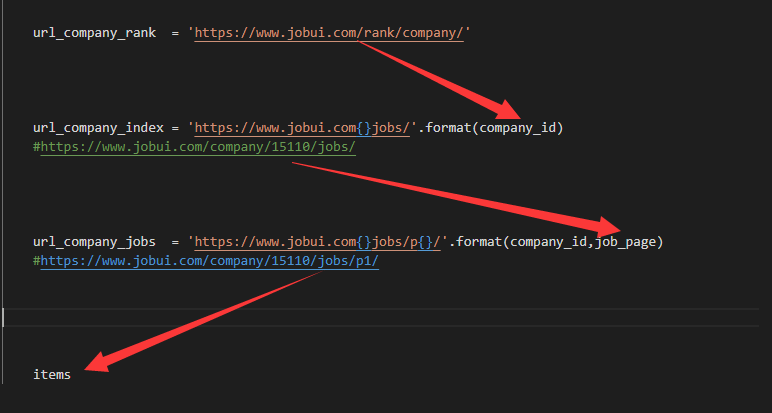
1 import scrapy 2 import bs4 3 import re 4 import requests 5 import math 6 from ..items import ZhiyouItem 7 8 class ZhiyouItemSpider(scrapy.Spider): 9 name = 'zhiyou' 10 allowed_domains = ['www.jobui.com'] 11 start_urls = ['https://www.jobui.com/rank/company/'] 12 13 def parse(self,response): 14 bs = bs4.BeautifulSoup(response.text,'html.parser') 15 datas = bs.find_all('a',href=re.compile('^/company/')) 16 for data in datas: 17 company_id = data['href'] 18 company_url = 'https://www.jobui.com{}jobs/'.format(company_id) 19 yield scrapy.Request(company_url,callback=self.parse_company) 20 21 def parse_company(self,response): 22 bs = bs4.BeautifulSoup(response.text,'html.parser') 23 try: 24 jobs = int(bs.find('p',class_='m-desc').text.split(' ')[1]) 25 job_page = math.ceil(jobs / 15) + 1 26 company_url = str(response).split(' ')[1].replace('>','') 27 # for i in range(1,job_page): 28 for i in range(1,2): 29 job_url = '{}p{}'.format(company_url,i) 30 yield scrapy.Request(job_url,callback=self.parse_job) 31 except: 32 pass 33 34 def parse_job(self,response): 35 bs = bs4.BeautifulSoup(response.text,'html.parser') 36 datas = bs.find_all('div',class_='job-simple-content') 37 company_name = bs.find('h1',id='companyH1')['data-companyname'] 38 for data in datas: 39 item = ZhiyouItem() 40 item['company'] = company_name 41 item['job'] = data.find('h3').text 42 item['city'] = data.find('span').text 43 item['desc'] = data.find_all('span')[1].text 44 yield item
3、编辑settings.py
1 BOT_NAME = 'zhiyou' 2 3 SPIDER_MODULES = ['zhiyou.spiders'] 4 NEWSPIDER_MODULE = 'zhiyou.spiders' 5 6 USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' 7 8 ROBOTSTXT_OBEY = False 9 10 FEED_URI = './s.csv' 11 FEED_FORMAT='CSV' 12 FEED_EXPORT_ENCODING='utf-8-sig' 13 14 DOWNLOAD_DELAY = 0.5 15 16 ITEM_PIPELINES = { 17 'zhiyou.pipelines.ZhiyouPipeline': 300, 18 }
4、编辑 items.py
1 import scrapy 2 3 class ZhiyouItem(scrapy.Item): 4 company = scrapy.Field() 5 job = scrapy.Field() 6 city = scrapy.Field() 7 desc = scrapy.Field()
5、编辑pipelines.py
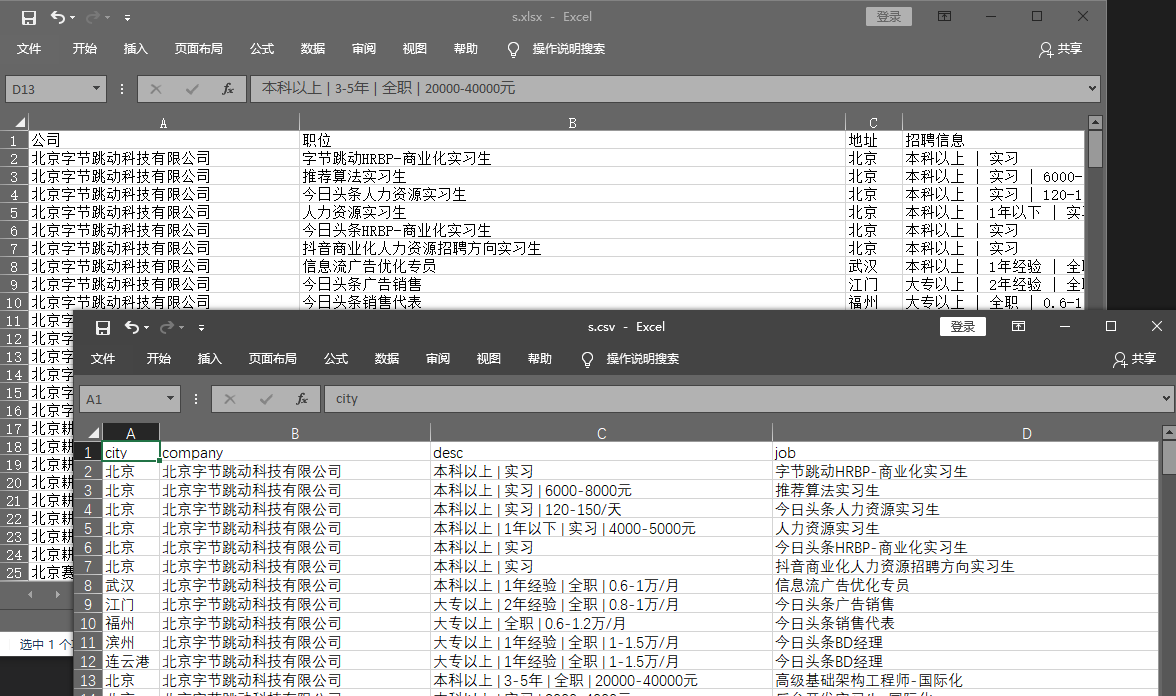
1 import openpyxl 2 3 class ZhiyouPipeline(object): 4 #定义一个JobuiPipeline类,负责处理item 5 def __init__(self): 6 #初始化函数 当类实例化时这个方法会自启动 7 self.wb =openpyxl.Workbook() 8 #创建工作薄 9 self.ws = self.wb.active 10 #定位活动表 11 self.ws.append(['公司', '职位', '地址', '招聘信息']) 12 #用append函数往表格添加表头 13 14 def process_item(self, item, spider): 15 #process_item是默认的处理item的方法,就像parse是默认处理response的方法 16 line = [item['company'], item['job'], item['city'], item['desc']] 17 #把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给line 18 self.ws.append(line) 19 #用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格 20 return item 21 #将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度 22 23 def close_spider(self, spider): 24 #close_spider是当爬虫结束运行时,这个方法就会执行 25 self.wb.save('./s.xlsx') 26 #保存文件 27 self.wb.close() 28 #关闭文件
6、在D:USERDATApythondangdang 下执行命令 scrapy crawl zhiyou
Scrapy 核心代码,callback
1 #导入模块: 2 import scrapy 3 import bs4 4 from ..items import JobuiItem 5 6 7 class JobuiSpider(scrapy.Spider): 8 name = 'jobs' 9 allowed_domains = ['www.jobui.com'] 10 start_urls = ['https://www.jobui.com/rank/company/'] 11 12 #提取公司id标识和构造公司招聘信息的网址: 13 def parse(self, response): 14 #parse是默认处理response的方法 15 bs = bs4.BeautifulSoup(response.text, 'html.parser') 16 ul_list = bs.find_all('ul',class_="textList flsty cfix") 17 for ul in ul_list: 18 a_list = ul.find_all('a') 19 for a in a_list: 20 company_id = a['href'] 21 url = 'https://www.jobui.com{id}jobs' 22 real_url = url.format(id=company_id) 23 yield scrapy.Request(real_url, callback=self.parse_job) 24 #用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parsejob方法。 25 26 27 def parse_job(self, response): 28 #定义新的处理response的方法parse_job(方法的名字可以自己起) 29 bs = bs4.BeautifulSoup(response.text, 'html.parser') 30 #用BeautifulSoup解析response(公司招聘信息的网页源代码) 31 company = bs.find(id="companyH1").text 32 #用fin方法提取出公司名称 33 datas = bs.find_all('li',class_="company-job-list") 34 #用find_all提取<li class_="company-job-list">标签,里面含有招聘信息的数据 35 for data in datas: 36 #遍历datas 37 item = JobuiItem() 38 #实例化JobuiItem这个类 39 item['company'] = company 40 #把公司名称放回JobuiItem类的company属性里 41 item['position']=data.find('h3').find('a').text 42 #提取出职位名称,并把这个数据放回JobuiItem类的position属性里 43 item['address'] = data.find('span',class_="col80").text 44 #提取出工作地点,并把这个数据放回JobuiItem类的address属性里 45 item['detail'] = data.find('span',class_="col150").text 46 #提取出招聘要求,并把这个数据放回JobuiItem类的detail属性里 47 yield item 48 #用yield语句把item传递给引擎