本文是我学习<深入理解计算机系统>中网络编程部分的学习笔记。
1. Web基础
web客户端和服务器之间的交互使用的是一个基于文本的应用级协议HTTP(超文本传输协议)。一个web客户端(即浏览器)打开一个到服务器的因特网连接,并且请求某些内容。服务器响应所请求的内容,然后关闭连接。浏览器读取这些内容,并把它显示在屏幕上。
对于web客户端和服务器而言,内容是与一个MIME类型相关的字节序列。常见的MIME类型:
| MIME类型 | 描述 |
| text/html | HTML页面 |
| text/plain | 无格式文本 |
| image/gif | GIF格式编码的二进制图像 |
| image/jpeg | JPEG格式编码的二进制图像 |
web服务器以两种不同的方式向客服端提供内容:
(1)静态内容:取一个磁盘文件,并将它的内容返回给客户端
(2)动态内容:执行一个可执行文件,并将它的输出返回给客户端
统一资源定位符:URL
http://www.google.com:80/index.html
表示因特网主机 www.google.com 上一个称为 index.html 的HTML文件,它是由一个监听端口80的Web服务器所管理的。 HTTP默认端口号为80
可执行文件的URL可以在文件名后包括程序参数, “?”字符分隔文件名和参数,而且每个参数都用“&”字符分隔开,如:
http://www.ics.cs.cmu.edu:8000/cgi-bin/adder?123&456
表示一个 /cgi-bin/adder 的可执行文件,带两个参数字符串为 123 和 456
确定一个URL指向的是静态内容还是动态内容没有标准的规则,常见的方法就是把所有的可执行文件都放在 cgi-bin 目录中
2. HTTP
HTTP标准要求每个文本行都由一对回车和换行符来结束
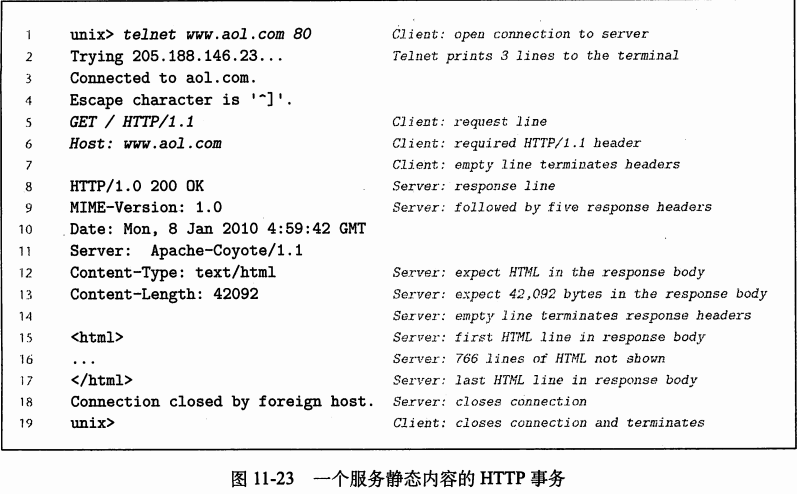
(1)HTTP请求
一个HTTP请求:一个请求行(request line) 后面跟随0个或多个请求报头(request header), 再跟随一个空的文本行来终止报头
请求行: <method> <uri> <version>
HTTP支持许多方法,包括 GET,POST,PUT,DELETE,OPTIONS,HEAD,TRACE。
URI是相应URL的后缀,包括文件名和可选参数
version 字段表示该请求所遵循的HTTP版本
请求报头:<header name> : <header data> 为服务器提供了额外的信息,例如浏览器的版本类型
HTTP 1.1中 一个IP地址的服务器可以是 多宿主主机,例如 www.host1.com www.host2.com 可以存在于同一服务器上。
HTTP 1.1 中必须有 host 请求报头,如 host:www.google.com:80 如果没有这个host请求报头,每个主机名都只有唯一IP,IP地址很快将用尽。
(2)HTTP响应
一个HTTP响应:一个响应行(response line) 后面跟随0个或多个响应报头(response header),再跟随一个空的文本行来终止报头,最后跟随一个响应主体(response body)
响应行:<version> <status code> <status message>
status code 是一个三位的正整数
| 状态代码 | 状态消息 | 描述 |
| 200 | 成功 | 处理请求无误 |
| 301 | 永久移动 | 内容移动到位置头中指明的主机上 |
| 400 | 错误请求 | 服务器不能理解请求 |
| 403 | 禁止 | 服务器无权访问所请求的文件 |
| 404 | 未发现 | 服务器不能找到所请求的文件 |
| 501 | 未实现 | 服务器不支持请求的方法 |
| 505 | HTTP版本不支持 | 服务器不支持请求的版本 |
两个最重要的响应报头:
Content-Type 告诉客户端响应主体中内容的MIME类型
Content-Length 指示响应主体的字节大小
响应主体中包含着被请求的内容。
3.服务动态内容
(1) 客户端如何将程序参数传递给服务器
GET请求的参数在URI中传递, “?”字符分隔了文件名和参数,每个参数都用一个"&"分隔开,参数中不允许有空格,必须用字符串“%20”来表示
HTTP POST请求的参数是在请求主体中而不是 URI中传递的
(2)服务器如何将参数传递给子进程
GET /cgi-bin/adder?123&456 HTTP/1.1
它调用 fork 来创建一个子进程,并调用 execve 在子进程的上下文中执行 /cgi-bin/adder 程序
在调用 execve 之前,子进程将CGI环境变量 QUERY_STRING 设置为"123&456", adder 程序在运行时可以用unix getenv 函数来引用它
(3)服务器如何将其他信息传递给子进程
| 环境变量 | 描述 |
| QUERY_STRING | 程序参数 |
| SERVER_PORT | 父进程侦听的端口 |
| REQUEST_METHOD | GET 或 POST |
| REMOTE_HOST | 客户端的域名 |
| REMOTE_ADDR | 客户端的点分十进制IP地址 |
| CONTENT_TYPE | 只对POST而言,请求体的MIME类型 |
| CONTENT_LENGTH | 只对POST而言,请求体的字节大小 |
(4) 子进程将它的输出发送到哪里
一个CGI程序将它的动态内容发送到标准输出,在子进程加载并运行CGI程序之前,它使用UNIX dup2 函数将它标准输出重定向到和客户端相关连的已连接描述符
因此,任何CGI程序写到标准输出的东西都会直接到达客户端
4. 综合: Tiny web 服务器
(1) main程序
Tiny是一个迭代服务器,监听在命令行中传递来的端口上的连接请求,在通过调用 open_listenfd 函数打开一个监听套接字以后,执行无限服务器循环,不断接受连接请求(第16行),执行事务(第17行),并关闭连接它的那一端(第18行)
1 int main(int argc, char **argv) 2 { 3 int listenfd, connfd, port, clientlen; 4 struct sockaddr_in clientaddr; 5 6 /* Check command line args */ 7 if (argc != 2) { 8 fprintf(stderr, "usage: %s <port> ", argv[0]); 9 exit(1); 10 } 11 port = atoi(argv[1]); 12 13 listenfd = Open_listenfd(port); 14 while (1) { 15 clientlen = sizeof(clientaddr); 16 connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); //line:netp:tiny:accept 17 doit(connfd); //line:netp:tiny:doit 18 Close(connfd); //line:netp:tiny:close 19 } 20 }
(2) doit函数
doit函数处理一个HTTP事物,首先读和解析请求行(request line)(第11-12行),注意,我们使用rio_readlineb函数读取请求行。
Tiny只支持GET方法,如果客户端请求其他方法,发送一个错误信息。
然后将URI解析为一个文件名和一个可能为空的CGI参数字符串,并且设置一个标志表明请求的是静态内容还是动态内容(第21行)
如果请求的是静态内容,就验证是否为普通文件,有读权限(第29行)
如果请求的是动态内容,就验证是否为可执行文件(第37行),如果是,就提供动态内容(第42行)
1 void doit(int fd) 2 { 3 int is_static; 4 struct stat sbuf; 5 char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE]; 6 char filename[MAXLINE], cgiargs[MAXLINE]; 7 rio_t rio; 8 9 /* Read request line and headers */ 10 Rio_readinitb(&rio, fd); 11 Rio_readlineb(&rio, buf, MAXLINE); //line:netp:doit:readrequest 12 sscanf(buf, "%s %s %s", method, uri, version); //line:netp:doit:parserequest 13 if (strcasecmp(method, "GET")) { //line:netp:doit:beginrequesterr 14 clienterror(fd, method, "501", "Not Implemented", 15 "Tiny does not implement this method"); 16 return; 17 } //line:netp:doit:endrequesterr 18 read_requesthdrs(&rio); //line:netp:doit:readrequesthdrs 19 20 /* Parse URI from GET request */ 21 is_static = parse_uri(uri, filename, cgiargs); //line:netp:doit:staticcheck 22 if (stat(filename, &sbuf) < 0) { //line:netp:doit:beginnotfound 23 clienterror(fd, filename, "404", "Not found", 24 "Tiny couldn't find this file"); 25 return; 26 } //line:netp:doit:endnotfound 27 28 if (is_static) { /* Serve static content */ 29 if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode)) { //line:netp:doit:readable 30 clienterror(fd, filename, "403", "Forbidden", 31 "Tiny couldn't read the file"); 32 return; 33 } 34 serve_static(fd, filename, sbuf.st_size); //line:netp:doit:servestatic 35 } 36 else { /* Serve dynamic content */ 37 if (!(S_ISREG(sbuf.st_mode)) || !(S_IXUSR & sbuf.st_mode)) { //line:netp:doit:executable 38 clienterror(fd, filename, "403", "Forbidden", 39 "Tiny couldn't run the CGI program"); 40 return; 41 } 42 serve_dynamic(fd, filename, cgiargs); //line:netp:doit:servedynamic 43 } 44 }
(3)clienterror函数
clienterror函数检查一些明显的错误,并把它报告给客户端
void clienterror(int fd, char *cause, char *errnum, char *shortmsg, char *longmsg) { char buf[MAXLINE], body[MAXBUF]; /* Build the HTTP response body */ sprintf(body, "<html><title>Tiny Error</title>"); sprintf(body, "%s<body bgcolor=""ffffff""> ", body); sprintf(body, "%s%s: %s ", body, errnum, shortmsg); sprintf(body, "%s<p>%s: %s ", body, longmsg, cause); sprintf(body, "%s<hr><em>The Tiny Web server</em> ", body); /* Print the HTTP response */ sprintf(buf, "HTTP/1.0 %s %s ", errnum, shortmsg); Rio_writen(fd, buf, strlen(buf)); sprintf(buf, "Content-type: text/html "); Rio_writen(fd, buf, strlen(buf)); sprintf(buf, "Content-length: %d ", (int)strlen(body)); Rio_writen(fd, buf, strlen(buf)); Rio_writen(fd, body, strlen(body)); }
(4)read_requesthdrs 函数
Tiny不使用请求报头中的任何信息,仅仅调用 read_requesthdrs函数来读取并忽略这些报头。
注意,终止请求报头的空文本行是由 回车和换行符组成的,在第6行中检查
1 void read_requesthdrs(rio_t *rp) 2 { 3 char buf[MAXLINE]; 4 5 Rio_readlineb(rp, buf, MAXLINE); 6 while(strcmp(buf, " ")) { //line:netp:readhdrs:checkterm 7 Rio_readlineb(rp, buf, MAXLINE); 8 printf("%s", buf); 9 } 10 return; 11 }
(5)parse_uri 函数
Tiny假设静态内容的主目录就是当前目录,可执行文件的主目录是 ./cgi-bin/ 任何包含字符串 cgi-bin 的URI都认为是对动态内容的请求。
首先将URI解析为一个文件名和一个可选的CGI参数字符串。
如果请求的是静态内容(第5行),就清除CGI参数串(第6行),然后将URI转换为一个相对的unix 路径名,例如 ./index.html
如果URI是用'/' 结尾的(第9行) ,我们就把默认的文件名加在后面(第10行)
如果请求的是动态内容(第13行),就会抽取所有的CGI参数(第14-20行),并将URI剩下的部分转换为一个相应的unix文件名(第21-22行)
1 int parse_uri(char *uri, char *filename, char *cgiargs) 2 { 3 char *ptr; 4 5 if (!strstr(uri, "cgi-bin")) { /* Static content */ //line:netp:parseuri:isstatic 6 strcpy(cgiargs, ""); //line:netp:parseuri:clearcgi 7 strcpy(filename, "."); //line:netp:parseuri:beginconvert1 8 strcat(filename, uri); //line:netp:parseuri:endconvert1 9 if (uri[strlen(uri)-1] == '/') //line:netp:parseuri:slashcheck 10 strcat(filename, "home.html"); //line:netp:parseuri:appenddefault 11 return 1; 12 } 13 else { /* Dynamic content */ //line:netp:parseuri:isdynamic 14 ptr = index(uri, '?'); //line:netp:parseuri:beginextract 15 if (ptr) { 16 strcpy(cgiargs, ptr+1); 17 *ptr = '�'; 18 } 19 else 20 strcpy(cgiargs, ""); //line:netp:parseuri:endextract 21 strcpy(filename, "."); //line:netp:parseuri:beginconvert2 22 strcat(filename, uri); //line:netp:parseuri:endconvert2 23 return 0; 24 } 25 }
(6)serve_static 函数
Tiny提供四种不同的静态内容:HTML文件、无格式的文本文件、GIF编码格式图片、JPEG编码格式图片
serve_static 函数发送一个HTTP响应,其主体包含一个本地文件的内容。
首先我们通过检查文件名的后缀来判断文件类型(第7行),并且发送响应行和响应报头给客户端(第8-12行)。注意用一个空行终止报头
第16行,我们使用 unix mmap函数将被请求文件映射到一个虚拟问存储器空间,调用mmap将文件srcfd的前filesize个字节映射到一个从地址srcp开始的私有只读虚拟存储器区域。
一旦文件映射到存储器,就不再需要它的描述符了,关闭这个文件(第17行)。
第18行执行的是到客户端的实际文件传动。rio_writen 函数拷贝从srcp位置开始的filesize个字节(已经被映射到了所请求的文件) 到客户端的已连接描述符。
第19行释放了映射的虚拟存储器区域,避免潜在的存储器泄漏
1 void serve_static(int fd, char *filename, int filesize) 2 { 3 int srcfd; 4 char *srcp, filetype[MAXLINE], buf[MAXBUF]; 5 6 /* Send response headers to client */ 7 get_filetype(filename, filetype); //line:netp:servestatic:getfiletype 8 sprintf(buf, "HTTP/1.0 200 OK "); //line:netp:servestatic:beginserve 9 sprintf(buf, "%sServer: Tiny Web Server ", buf); 10 sprintf(buf, "%sContent-length: %d ", buf, filesize); 11 sprintf(buf, "%sContent-type: %s ", buf, filetype); 12 Rio_writen(fd, buf, strlen(buf)); //line:netp:servestatic:endserve 13 14 /* Send response body to client */ 15 srcfd = Open(filename, O_RDONLY, 0); //line:netp:servestatic:open 16 srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);//line:netp:servestatic:mmap 17 Close(srcfd); //line:netp:servestatic:close 18 Rio_writen(fd, srcp, filesize); //line:netp:servestatic:write 19 Munmap(srcp, filesize); //line:netp:servestatic:munmap 20 } 21 22 /* 23 * get_filetype - derive file type from file name 24 */ 25 void get_filetype(char *filename, char *filetype) 26 { 27 if (strstr(filename, ".html")) 28 strcpy(filetype, "text/html"); 29 else if (strstr(filename, ".gif")) 30 strcpy(filetype, "image/gif"); 31 else if (strstr(filename, ".jpg")) 32 strcpy(filetype, "image/jpeg"); 33 else 34 strcpy(filetype, "text/plain"); 35 }
(6)serve_dynamic 函数
Tiny通过派生一个子进程并在子进程的上下文中运行一个CGI程序,来提供各种类型的动态内容。
serve_dynamic函数一开始就向客户端发送一个表明成功的响应行,,同时还包括带有信息的server报头。
第13行,子进程用来自请求URI的CGI参数初始化QUERY_STRING环境变量
第14行,子进程重定向它的标准输出到已连接文件描述符
第15行,加载并运行CGI程序,因为CGI程序运行在子进程的上下文中,它能够访问所有在调用execve函数之前就存在的打开文件和环境变量
第17行,父进程阻塞在对wait的调用中,等待子进程终止的时候,回收操作系统那个分配给子进程的资源
1 void serve_dynamic(int fd, char *filename, char *cgiargs) 2 { 3 char buf[MAXLINE], *emptylist[] = { NULL }; 4 5 /* Return first part of HTTP response */ 6 sprintf(buf, "HTTP/1.0 200 OK "); 7 Rio_writen(fd, buf, strlen(buf)); 8 sprintf(buf, "Server: Tiny Web Server "); 9 Rio_writen(fd, buf, strlen(buf)); 10 11 if (Fork() == 0) { /* child */ //line:netp:servedynamic:fork 12 /* Real server would set all CGI vars here */ 13 setenv("QUERY_STRING", cgiargs, 1); //line:netp:servedynamic:setenv 14 Dup2(fd, STDOUT_FILENO); /* Redirect stdout to client */ //line:netp:servedynamic:dup2 15 Execve(filename, emptylist, environ); /* Run CGI program */ //line:netp:servedynamic:execve 16 } 17 Wait(NULL); /* Parent waits for and reaps child */ //line:netp:servedynamic:wait 18 }