问题起源
在使用t-sql中的exists(或者not exists)子查询的时候,不知道什么时候开始,发现一小部分人存在一种“伪优化”的一些做法,
并且向不明真相的群众传递这一种写法“优越性”,实在看不下去,
无法传递给他人正确的指导思想无可厚非,给他人传递错误的思想或者说误导人倒是一种罪恶。
本来这个事情是不值得一提的,看到越来越多被误导的群众开始推崇这种做法(甚至开始坚信了),实在是看不习惯,不吐不快。
典型的问题如下
select * from TableA a
where exists
(select 1 from TableB b where a.Id = b.Id ),当然这里子查询里写成select * 也无所谓。
这个要表达的逻辑就是说B表中存在与A表相同的Id的数据,就成立,这是要表达的逻辑。
参考如下写法,有人偏偏在在exists子查询中加上top 1 1,问其原因,为什么提高性能?理由就是加了top 1 1,只要在TableB中存在一条满足条件的条件即可,同时不用返回所有的行和列,因此可以提高性能。
select * from TableA a
where exists
(select top 1 1 from TableB b where a.Id = b.Id )
与直接写select 1 from TableB where a.Id =b.Id相比,真的可以提高性能吗?
exists(或者not exists)子查询的实现是一种半连接的“探测”逻辑机制(Semi Join),意思就是只要存在(而不关心具体有多少条)符合条件的数据即可,当然是不会再B表中找到所有的数据行(或者列)之后再返回。
但是exists(或者not exists)具体在执行的时候,到底走不走Semi Join不一定,跟具体的执行计划有关,本文暂不讨论走不走Semi Join的问题,只讨论子查询中select top 1 1 的写法到底影不影响效率。
测试验证
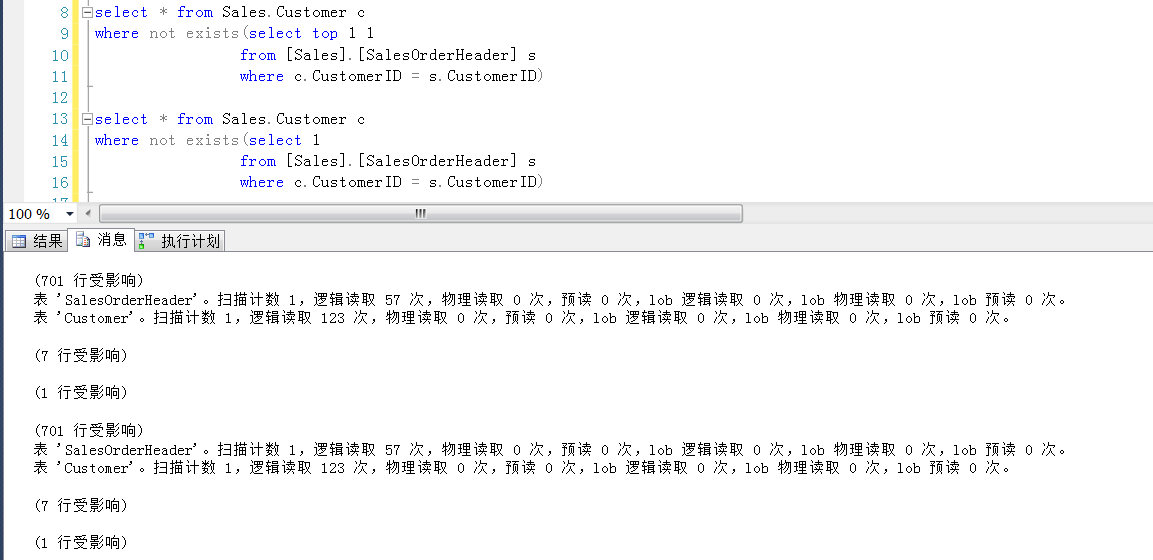
就以AdventureWorks2012示例库的两个表做demo,看看两者的执行计划和IO信息,会发现子查询中加不加 top 1,执行计划一样,IO一样,扯什么性能……
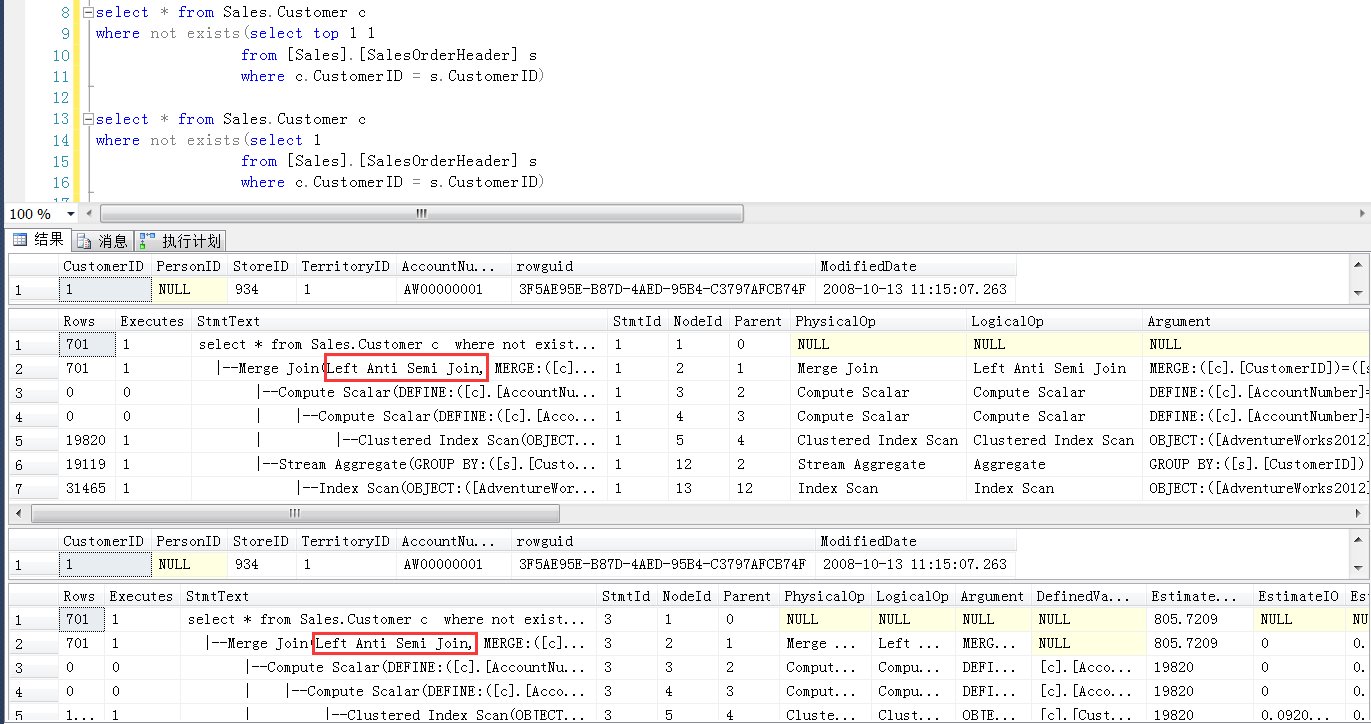
exists(或者not exists)的半连接的逻辑机制(Semi Join)决定了,你写不写top 1,它都是找到一个符合条件的数据之后就返回外层查询,
甚至在子查询中写select * from TableName,如果走Semi Join的执行方式,他照样是探测到有一条存在的数据之后就返回,肯定不会把所有的行都给找出来再返回,
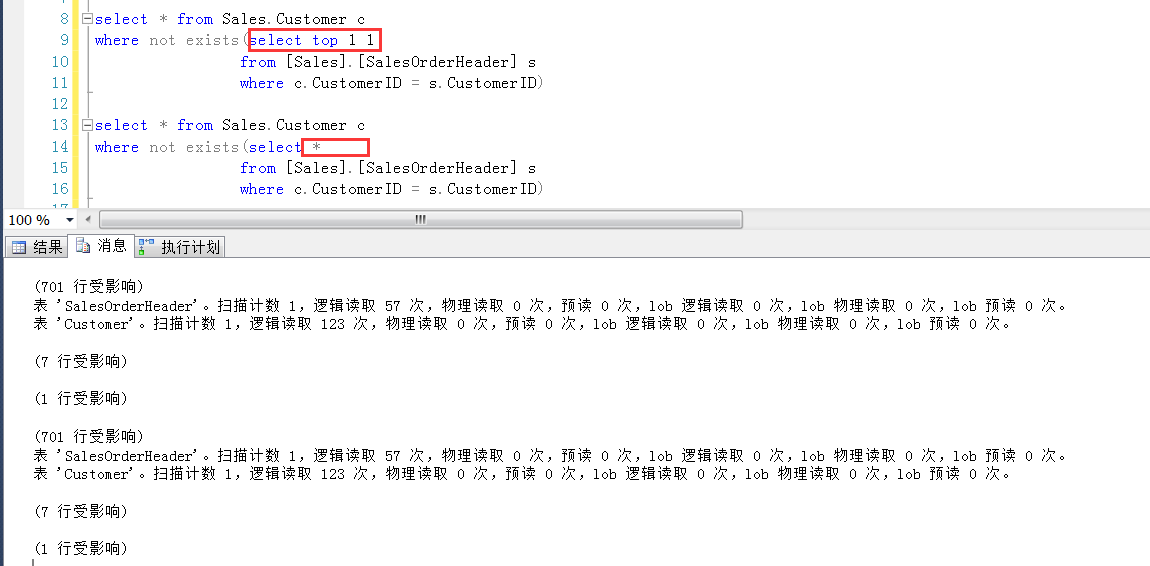
以下截图可以看到,即便子查询是select * ,IO信息也是一样的(当然执行计划也一样)。
在当前这种情况下,可以认为exists子查询中的*,也是不会影响效率什么的。
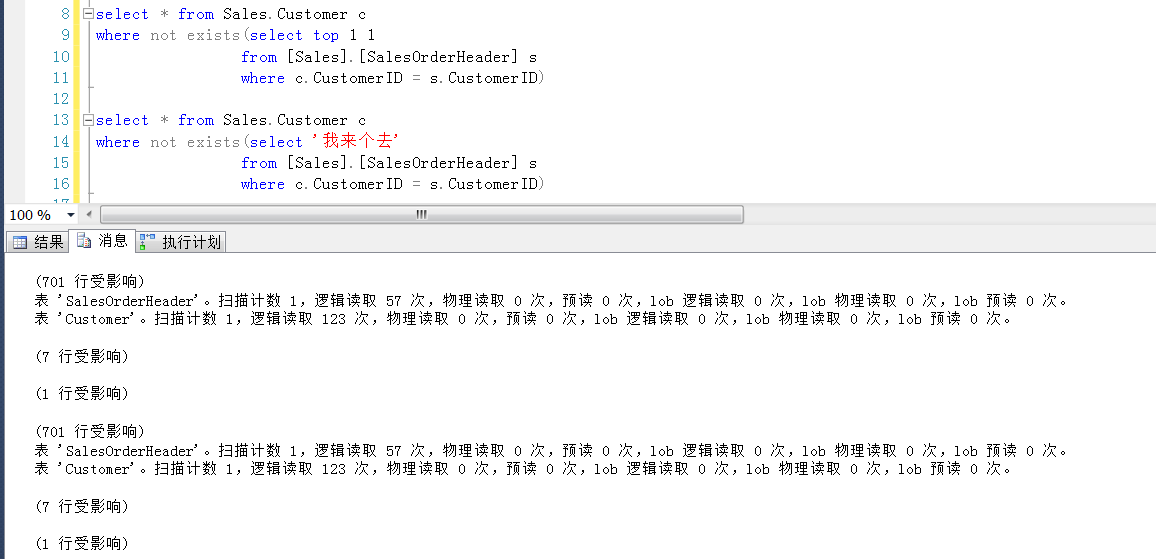
甚至是可以在子查询中select一个常量,也不会影响到效率或者说改变执行计划。
总结
这个问题比较简答,当然这个场景也仅限于sqlserver中的exists或者not exists子查询,对于别的数据库也不确定是不是优化器内部会自动优化。
当前这种场景下,对于sqlserver来说,不要费尽心思去刻意用select top 1 1去“优化”了。