在这篇文章之前,陆续有了一些使用深度学习网络进行SR任务的工作,但是这些以提升PSNR为目标的深度神经网络存在几点问题:
- 网络表现对于网络结构很敏感,不同的初始化和训练方法对表现得影响也很大。这就使得模型的设计和优化策略的选择变得非常重要。
- 目前的SR算法都把不同放大因子的问题看作是独立的问题,没有利用他们之间的互相关系。
这篇文章主要针对这两点问题,首先改进了SRResNet网络结构,通过分析去除了不必要的模块简化了模型,提出了更稳定的训练方法。之后探索如何将其他尺度下训练的模型的只是转移,通过使用预训练的低尺度模型训练高尺度模型,从而在训练中利用了scale-interdependent信息。在训练$ imes3, imes 4$模型时,将预训练的$ imes2$作为初始化。并且提出了一个多尺度的超分模型,可以在一个模型中重建不同尺度的高分辨率图像。这篇文章的工作不是非常复杂,但是非常有效果,而且个人感觉paper的写作非常简洁清晰,在写作方面也值得借鉴。
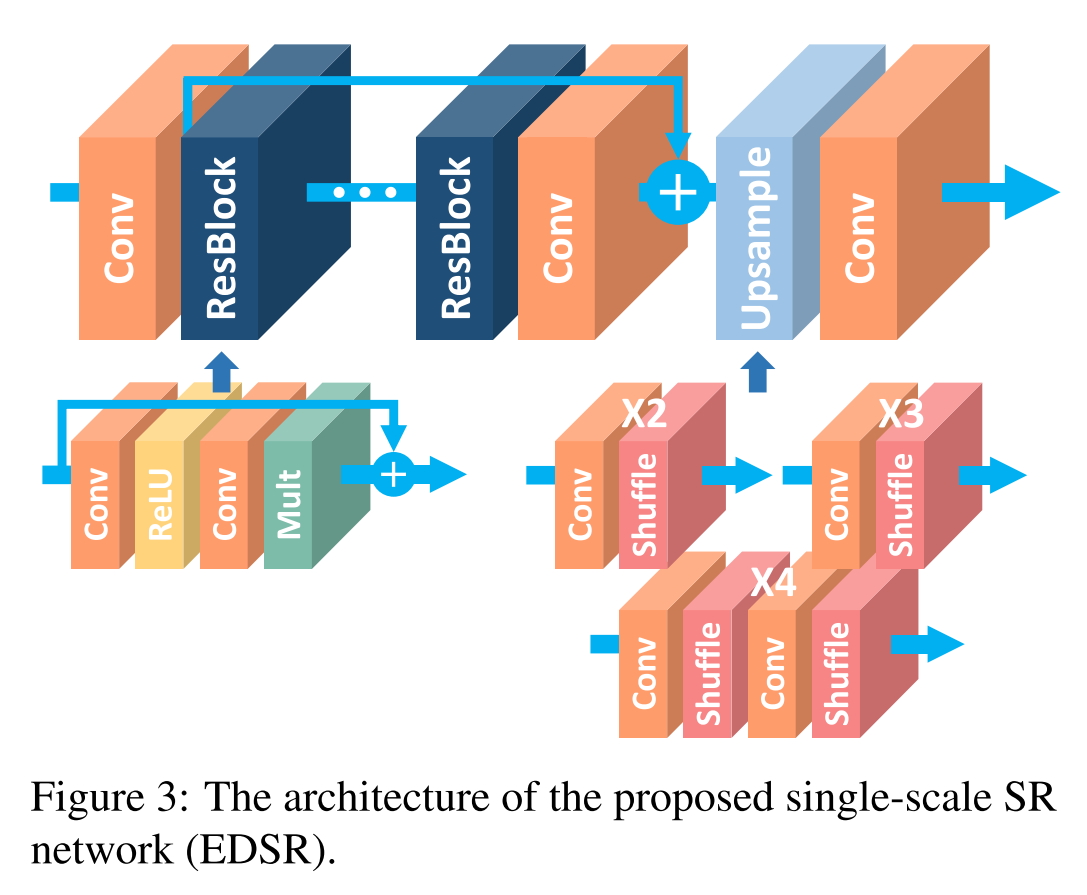
SRResNet是在ResNet提出后提出的,仅仅将ResNet直接应用于SR任务。但由于ResNet提出的初衷是应用于high-level-vision问题,直接应用实际上是suboptimal的。在每一个Residual Block中,都有一个Batch Normalization层,他归一化了特征但也因此去除了网络中的灵活性。本文去除每个Residual Block中的BN层,提升了表现。而且减少了大约40%的内存,这些节省的内存可以用于构建更大的模型。
模型的表现可以通过增加参数量来实现,假设一个网络的深度为$B$,宽度为$F$,那么参数量是$O(BF^2)$,内存量是$O(BF)$。(这只是一个大概的估计,他这里的宽度是把输入和输出的宽度视为一样的来看。一般模型会用参数量或是FLOPS进行衡量,一般一层的FLOPS用$H_out*W_out*(d*d*C*N)$来估计,$d*d*C*N$表示kernel的尺寸和个数)因此在资源有限的情况下应该尽可能增大F。但特征图数量增大到一定程度时会导致训练过程非常不稳定。文中提出使用Residual Scaling的方法解决该问题,即在每一个residual block中,最后一个卷积层后加一层constant scaling layer,乘以一个常数(文中使用的时0.1)
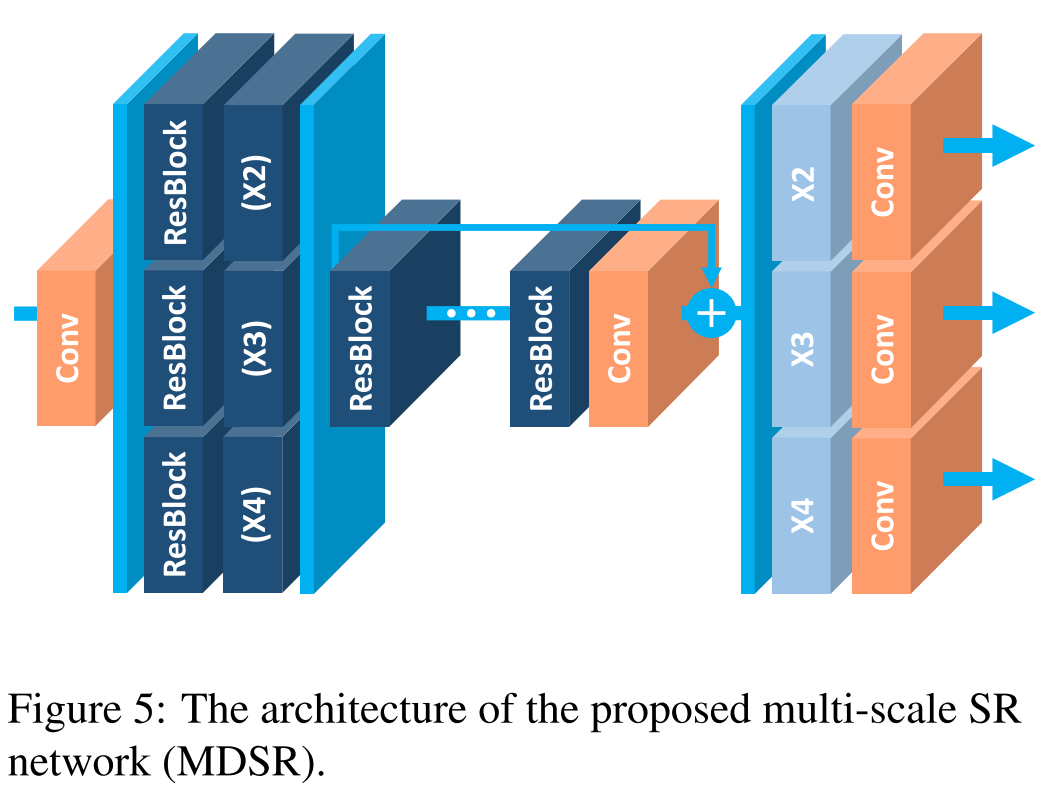
文中提出的多尺度模型如下,预处理模块是两层的residual block,作用是reduce不同尺度的输入中的variance。主干部分是相同的,使用相同的参数。网络的最后是scale-specific的上采样模块,平行的分布,处理多尺度的重建工作。该多尺度模型的参数量相比单独处理的模型参数总和要小很多。
文章在DIV2K, Set5, Set10, B100, Urban100数据集上进行了实验。使用的是L1loss。通常L2loss可以使PSNR表现更好,但作者发现L1loss可以提供更好的收敛性。相比SRCNN,EDSR差不多能提升1个点的表现,在Set5甚至差不多能有2个点。相比SRResNet差不多可以提升约0.5个点。