紧接上文,我们讲述在线分类问题
令,
为0-1损失,我们做出如下的简化假设:

学习者的目标是相对于hypotheses set: H具有low regret,其中H中的每个函数是从到{0,1}的映射,并且regret被定义为:
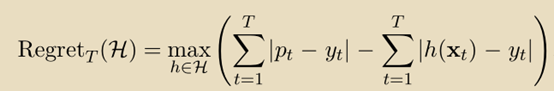
我们首先证明这是一个不可能完成的任务——如果,没有算法可以获得次线性regret bound。考虑
,
是一个总是返0的函数,
是一个总是返1的函数。通过简单地等待学习者的预测然后提供相反的答案作为真实答案,攻击者可以使任何在线算法的错误数等于T。相反,对于任何真实答案序列,令b为
中的大多数标签,则
的错误数最多为T/2。因此,任何在线算法的regret可能至少是T-T/2 =T/2,这不是T的次线性。
为了回避Cover’s impossibility result,我们进一步限制对抗环境的能力。下面展示两种方法。
第一种方法是增加额外的一个假设:

接下来,我们描述和分析在线学习算法,假设有限假设类(Finite Hypothesis Class)和输入序列的可实现性(realizability)。最自然的学习规则是使用(在任何在线回合)任何与过去所有例子一致的假设。

Consistent 算法维持一个与一致的所有假设的集合
。此集合通常称为version space。然后它从中选择任何假设并根据该假设进行预测。
Consistent 算法的mistake bound:

Halving算法:

Having算法的mistake bound:
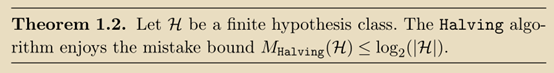
证明:

第二种方法是随机化(Randomization):
如果学习机输出 (
(),则它在t回合上的期望损失是:
对predictions domain做改变,此时predictions domain不等于target domain:
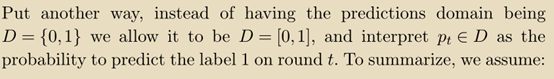
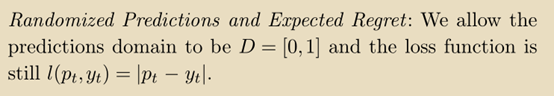
根据这个假设,可以推导出如下定理中所述的low regret算法:

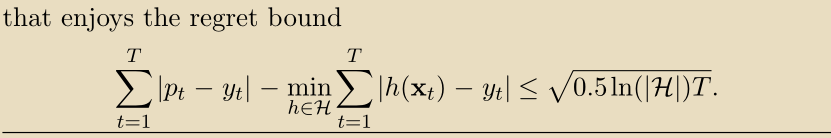
我们已经提出了两种不同的方法来回避Cover’s impossibility result: realizability 和 randomization。这两种方法似乎有些不同。然而,有一个深层的基本概念将它们连接起来。事实上,我们将证明这两种方法都可以解释为凸化技术。凸性是推导在线学习算法的中心主题,我们在下一节中进行研究。
未完,待续。。。。。。
下一节分析在线凸优化技术。