前提是先安装hadoop和java,启动hive之前要先启动HDFS和yarn
安装hive在一台机器上安装就可以了.

1.解压
tar -zxvf apache-hive-1.2.1-bin.tar.gz

配置环境变量
vi /etc/profile
新建一个hive-site.xml(好像只修改这个配置文件就行了)
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop1:3306/hive?createDatabaseIfNotExist=true</value>
#如果mysql在本机,那么这里的hadoop1可以换成localhost,如果在其他机器上,则需要授予权限
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
6.把mysql驱动包放到hive的lib目录下(去网上或者maven库中找一个mysql驱动包)

如果不替换jline包会报找不到主类的错误(jline是提供命令行的功能的,命令行的字需要它解析)
7.删除jline包
rm -rf /opt/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar
8.拷贝jline包
cd /hive-1.2.1/lib/
cp jline-2.12.jar /opt/hadoop-2.6.4/share/hadoop/yarn/lib/
进入hive:


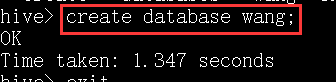
创建一个数据库wang:
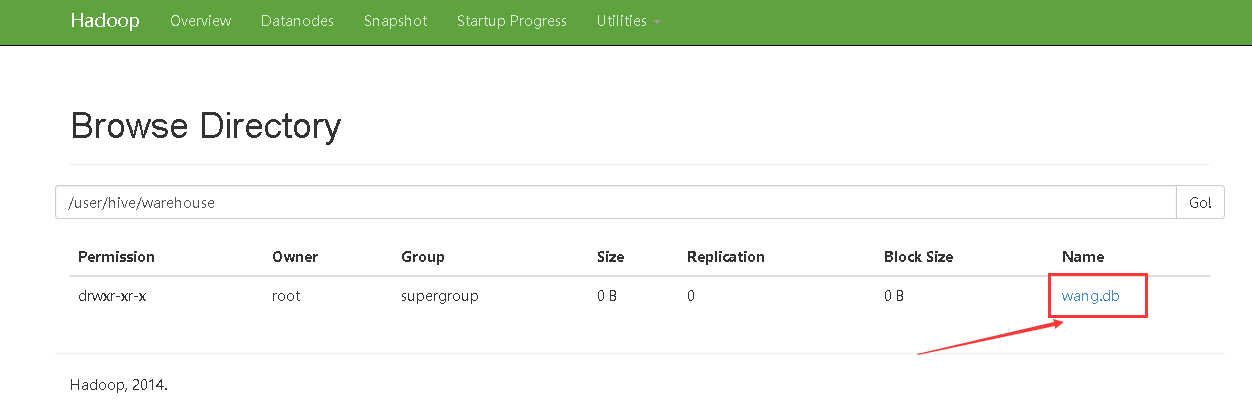
查看HDFS的UI界面:
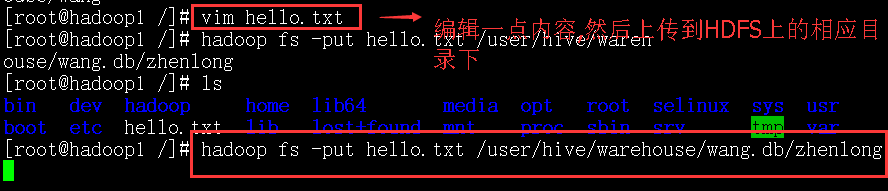


select * from 不会产生mapreduce任务,下面这一条名命令可以产生mapreduce任务.
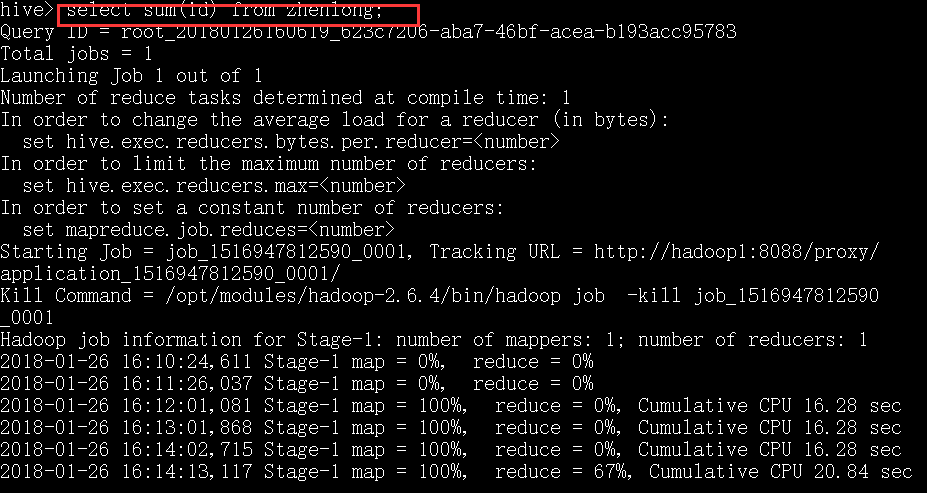
启动hive可以有好几种方式:
直接输入hive可以启动
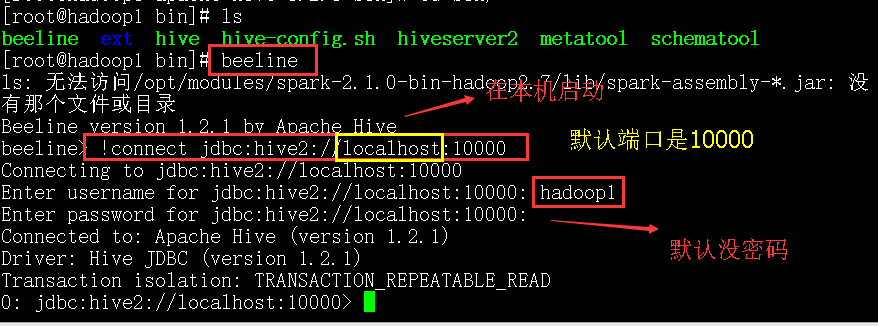
也可以把hive启动为一个服务, hive thrift

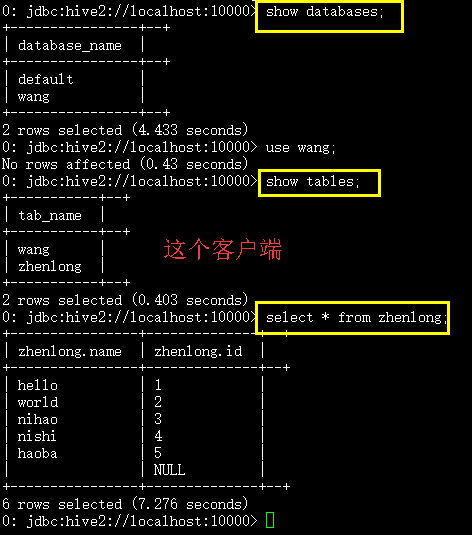

hive的大体使用就是这样.