一、基于PaddleHub的一键OCR中文识别
(1)背景介绍:
飞桨首次开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。根据OCR的应用场景而言,我们可以大致分成识别特定场景下的专用OCR以及识别多种场景下的通用OCR。就前者而言,证件识别以及车牌识别就是专用OCR的典型案例。针对特定场景进行设计、优化以达到最好的特定场景下的效果展示。那通用的OCR就是使用在更多、更复杂的场景下,拥有比较好的泛性。在这个过程中由于场景的不确定性,比如:图片背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等等问题,会带来极大的挑战。现PaddleHub为大家提供的是超轻量级中文OCR模型,聚焦特定的场景,支持中英文数字组合式别、竖排文字识别、长文本识别场景。
aistudio项目地址: https://aistudio.baidu.com/aistudio/projectdetail/507159?shared=1
(2)技术路线:
输入--图像预处理--文字检测--文本识别--输出
(3)实验展示:

图1:加载预训练模型
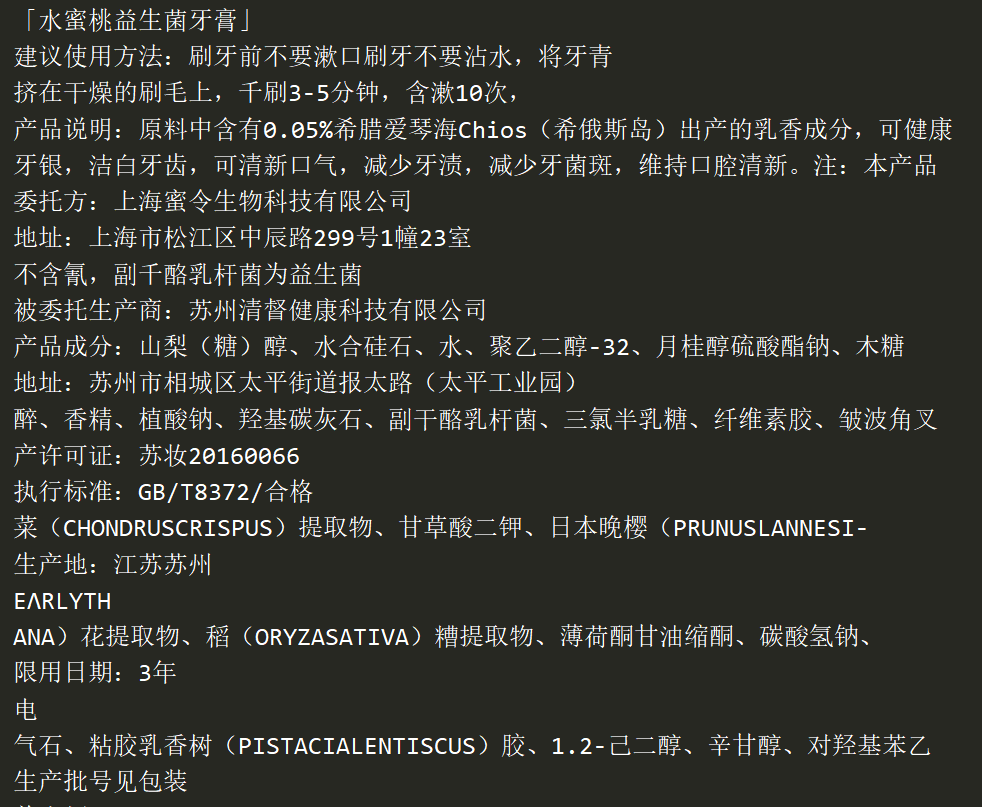
图2;预测结果

图3;成品一

图4:成品二

图5:成品三
二、总结和收获
在本次暑期实践中,我学习了python、Paddlehub的相关知识,我认识到,无论是在机器学习还是深度学习中,Python以及成为主导性的编程语言,而且现在许多主流的深度学习框架都提供Python接口,Python被用于数据处理、定义网络模型、执行训练过程、数据可视化等。熟悉Python的基础语法对深度学习实践是非常重要的。而Paddlehub就是为了解决对深度学习模型的需求而开发的工具,方便用户不用花费大量精力从头开始训练一个模型,综合这段时间的学习,感觉对paddlehub的框架使用比较顺手,在以后的学习生活中将会进一步加深框架的应用,其次就是我认识到深度学习的底层基础是数学基础知识,只有对数学知识进行深入学习和理解,在加上不断的积累实际的经验,遇到更多的问题,再进行解决累积经验。