数据结构中有数组和链表来实现对数据的存储,但是数组存储区间是连续的,寻址容易,插入和删除困难;而链表的空间是离散的,因此寻址困难,插入和删除容易。
因此,综合了二者的优势,我们可以设计一种数据结构——哈希表(hash table),它寻址、插入和删除都很方便。在java中,哈希表的实现主要就是HashMap了,可以说HashMap是java开发中使用最多的类之一吧。
HashMap的底层其实就是链表的数组,代码为
transient Entry[] table;
这里的table其实就是一个链表的数组,因为我们的数据是二元的,因此HashMap定义了一个内部的类Entry,它包含了key和value两个属性。这样一个一维的线性数组就可以存储两个值了。同时Entry是一个链表,因此还有一个Entry next属性,它指向了下一个节点。
存储put时:
首先计算出key的hash,然后用table[hash]得到那个链表,再遍历这个链表,如果链表中有一个key和这个key是满足equals的话,则将value替换掉;如果没有的话,则插入到链表的尾部。
int h = hash(key); Entry e = table[h];
for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果key在链表中已存在,则替换为新value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
在get时,也是以同样的方法得到那个链表Entry e;然后遍历这个链表取出元素
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null;
HashMap对性能的优化:
HashMap对性能优化,主要是在于减少hash冲突(不同的key算出同样的hash),因为hash冲突越多,从链表中需要的寻址时间就越长。
1.通过计算hash值的方式减少hash冲突:
这个hash方法有效的减少了hash冲突:(具体我确实不懂!大家参考http://zhangshixi.iteye.com/blog/672697)
static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } static int indexFor(int h, int length) { return h & (length-1); }
我自己写了一个非常简单计算hash值的方式,勉强能用:
Math.abs(o==null?0:o.hashCode()) % length
2.自动扩容
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。因此,此时就需要对数组进行扩容了。
当HashMap中的元素个数超过数组大小*loadFactor(默认值0.75)时,就会进行数组扩容。这时,需要创建一张新表,将原表的映射到新表中。
扩容时,遍历每个元素,重新计算其hash值,然后加入新表中。
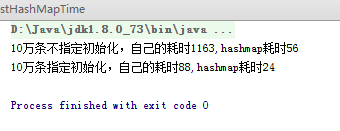
一般来说,扩容数组的大小为原数组大小的两倍。而这是一个很耗性能的操作,因此,如果我们已经预知HashMap中元素的个数,那么提前设置初始容量将大大提升其性能。
我将我的源码放到了github上,欢迎大家下载交流。
http://pan.baidu.com/s/1qXN137Q (12月19号更新)
https://github.com/xcr1234/my-java
附上自己实现的性能测试结果,勉强能接受
这篇博文和代码肯定还有很多不足的地方,也请各位大神指出!或者fork我的代码并提出宝贵的建议,谢谢!