1 概述
RankNet、LambdaRank和LambdaMART是三个关系非常紧密的机器学习排序算法。
简而言之,RankNet是最基础,基于神经网络的排序算法;
而LambdaRank在RankNet的基础上修改了梯度的计算方式,也即加入了lambda梯度;
LambdaMART结合了lambda梯度和MART(另称为GBDT,梯度提升树)。
这三种算法在工业界中应用广泛,在BAT等国内大厂和微软谷歌等世界互联网巨头内部都有大量应用,还曾经赢得“Yahoo!Learning To Rank Challenge(Track 1)"的冠军。本人认为如果评选当今工业界中三种最重要的机器学习算法,以LambdaMART为首的集成学习算法肯定占有一席之地,另外两个分别是支持向量机和深度学习。
1. 排序问题的解决方法可总结为3种:point wise,pair wise,list wise。
2. LambdaMART算法模型属于第三种,其中MART是回归树。多棵树,每棵在前一棵的基础上学习。
3. boosting思想:叠加多个弱模型,渐进的逼近真实情况。问题在于:如何保证拟合方向正确,如何叠加弱模型的结果。
4. AdaBoost法:每次计算一个弱模型,对此弱模型分类错误的样本,增加其权重,在下一个弱模型中去学习。每次学习的样本应该是没有变化的,只是有的样本权重增大了。即增加权重来保证拟合方向正确,加法模型叠加弱模型效果。
5. MART:回归树。前后两步模型损失函数的差,近似于损失函数对模型求导*f(m+1)。如何保证每一次迭代都对解决问题有所帮助,模型每次拟合的目标f(m+1)是损失函数的梯度。决策树实际上将样本空间分为不同的区域,并进行预测。引入学习率,使得每次学习的目标是学习率的一部分。shrinkage,缩减,防止过拟合。
6.LambdaMART 就是用一个λ值代替了损失函数的梯度,将λ和 MART 结合起来罢了。
7. RankeNet :定义了一个连续可导的损失函数作为ranking的最优化目标,即概率的交叉熵。最终排序需要根据一个分数来进行比较,因此要得到一个计算分数的公式。根据公式计算,得到分数,就可得到偏序概率,即将分数经过sigmoid函数。再将偏序概率带入交叉熵函数,求导即可对函数的参数进行优化。
8. RankNet 的梯度下降表现在结果的整体变化中是逆序对的下降。RankNet 的梯度下降表现在单条结果的变化中,是结果在列表中的移动趋势。则直接定义梯度,来使得移动的趋势更好。对ranknet的损失函数求梯度,即所有逆序对的值求导。lambda(i,j),为损失函数L(i,j)对i的分数Si的导数,再加入NDCG的变化值。而每条文档移动的方向和趋势取决于其他所有与之 label 不同的文档。
9.LambdaMART:lambda是一个梯度,MART需要一个梯度,于是结合。

1 RankNet
1 .1 算法基础定义
RankNet解决如下搜索排序问题:给定query集合,每个query都对应着一个文档集合,如何对每个query返回排序后的文档集合。可以想象这样的场景:某位高考生在得知自己的成绩后,准备报考志愿。听说最近西湖大学办得不错,所以就想到网上搜搜关于西湖大学的资料。他打开一个搜索引擎,输入“西湖大学”四个字,然后点击“搜索”,页面从上到下显示了10条搜索结果,他认为排在上面的肯定比下面的相关,所以就开始从上往下一个个地浏览。所以RankNet的目标就是对所有query,都能将其返回的文档按照相关性进行排序。

2 LambdaRank
2.1 为什么需要LambdaRank
先看一张论文原文中的图,如下所示。这是一组用二元等级相关性进行排序的链接地址,其中浅灰色代表链接与query不相关,深蓝色代表链接与query相关。 对于左边来说,总的pairwise误差为13,而右边总的pairwise误差为11。但是大多数情况下我们更期望能得到左边的结果。这说明最基本的pairwise误差计算方式并不能很好地模拟用户对搜索引擎的期望。右边黑色箭头代表RankNet计算出的梯度大小,红色箭头是期望的梯度大小。NDCG和ERR在计算误差时,排名越靠前权重越大,可以很好地解决RankNet计算误差时的缺点。但是NDCG和ERR均是不可导的函数,如何加入到RankNet的梯度计算中去?

2.2 LambdaRank定义
RankNet中的λijλij可以看成是UiUi和UjUj中间的作用力,如果Ui⊳UjUi⊳Uj,则UjUj会给予UiUi向上的大小为|λij||λij|的推动力,而对应地UiUi会给予UjUj向下的大小为|λij||λij|的推动力。如何将NDCG等类似更关注排名靠前的搜索结果的评价指标加入到排序结果之间的推动力中去呢?实验表明,直接用|ΔNDCG||ΔNDCG|乘以原来的λijλij就可以得到很好的效果,也即:
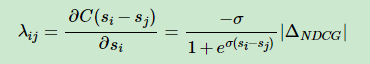
其中|ΔNDCG||ΔNDCG|是交换排序结果UiUi和UjUj得到的NDCG差值。NDCG倾向于将排名高并且相关性高的文档更快地向上推动,而排名地而且相关性较低的文档较慢地向上推动。
另外还可以将|ΔNDCG||ΔNDCG|替换成其他的评价指标。
λi可以看成是作用在排序文档上的力,其正负代表了方向,长度代表了力的大小。最初的实现是对每个文档对,都计算一遍梯度并且更新神经网络的参数值,而这里则是将同一个query下的所有文档对进行叠加,然后更新一次网络的权重参数。这种分解组合形式实际上就是一种小批量学习方法,不仅可以加快迭代速度,还可以为后面使用非连续的梯度模型打下基础。

如图 1所示,每个线条表示文档,蓝色表示相关文档,灰色表示不相关文档,RankNet以pairwise error的方式计算cost,左图的cost为13,右图通过把第一个相关文档下调3个位置,第二个文档上条5个位置,将cost降为11,但是像NDCG或者ERR等评价指标只关注top k个结果的排序,在优化过程中下调前面相关文档的位置不是我们想要得到的结果。图 1右图左边黑色的箭头表示RankNet下一轮的调序方向和强度,但我们真正需要的是右边红色箭头代表的方向和强度,即更关注靠前位置的相关文档的排序位置的提升。LambdaRank[11]正是基于这个思想演化而来,其中Lambda指的就是红色箭头,代表下一次迭代优化的方向和强度,也就是梯度。
3 LambdaMART:
首先你需要了解MART也就是GBDT,LambdaMART只是在GBDT的过程中做了一个很小的修改。原始GBDT两棵树之间样本的lable是通过「残差」确定,这里相当于不只是用残差,还用到了评价指标的信息:
λij=Sij∣∣△NDCG∂C∂oij∣∣λij=Sij|△NDCG∂C∂oij|
具体到一个样本上:
λi=∑j∈Pλijλi=∑j∈Pλij
整个流程被修改为(注意第6行):

类似做rank的方法还有GBRank,和传统GBDT的区别也是在「残差」的地方动脑子,有兴趣可以关注。并且xgboost也实现了Rank部分,基于LambdaRank,配合上GBDT也,应该也就变成LambdaMART了,有空可以尝试一下。
总结:
优势:1 直接优化排序目标,效果好 2 单模型融合多目标,serving压力小
劣势:1 样本数量大,训练速度慢 2 有些偏序关系不容易构造 3 多目标之间的关系不容易调整
对于梯度意义的理解:
RankNet:

λi可以看成是作用在排序文档上的力,其正负代表了方向,长度代表了力的大小。最初的实现是对每个文档对,都计算一遍梯度并且更新神经网络的参数值,
而这里则是将同一个query下的所有文档对进行叠加,然后更新一次网络的权重参数。这种分解组合形式实际上就是一种小批量学习方法,不仅可以加快迭代速度,
还可以为后面使用非连续的梯度模型打下基础。
LambdaRank
RankNet中的λijλ可以看成是UiUi和UjUj中间的作用力,如果Ui⊳UjUi⊳Uj,则UjUj会给予UiUi向上的大小为|λij||λij|的推动力,而对应地UiUi会给予UjUj向下的大小为|λij||λij|的推动力。
如何将NDCG等类似更关注排名靠前的搜索结果的评价指标加入到排序结果之间的推动力中去呢?实验表明,直接用|ΔNDCG||ΔNDCG|乘以原来的λijλij就可以得到很好的效果,也即:
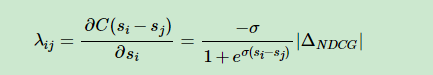
其中|ΔNDCG||ΔNDCG|是交换排序结果UiUi和UjUj得到的NDCG差值。NDCG倾向于将排名高并且相关性高的文档更快地向上推动,而排名地而且相关性较低的文档较慢地向上推动。
另外还可以将|ΔNDCG||ΔNDCG|替换成其他的评价指标。
LambdaMART




链接:
1 https://www.jianshu.com/p/bad4896e7e06
2 https://blog.csdn.net/huagong_adu/article/details/40710305
3 https://www.cnblogs.com/genyuan/p/9788294.html
4 https://www.cnblogs.com/genyuan/p/9788294.html
5 https://www.jianshu.com/p/aab1bf1307fd learn to rank 评价指标介绍