| 所属课程 | 福州大学软件工程实践(2019) |
|---|---|
| 作业要求 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结对学号 | 221600330吴可强、221600331向鹏 |
| 作业目标 | 提高个人编码能力,查找资料与学习能力,团队合作与沟通能力 |
| 本博客链接 | https://www.cnblogs.com/xiang-peng/p/10540046.html |
| 队友博客链接 | https://www.cnblogs.com/masgak/p/10537632.html |
| 基本需求github地址 | https://github.com/Snug-XP/PairProject1-Java |
| 进阶需求github地址 | https://github.com/masgak/PairProject2-Java |
分工:#
- 1、221600330吴可强 :负责爬虫与附加题部分,整合测试与修改函数,博客编写。
- 2、221600331向鹏:负责词频统计的代码实现和相关撰写,单元测试和性能分析。
本次作业分两部分#
一:基本需求##
实现一个能够对文本文件中的单词的词频进行统计的控制台程序。
第一步、实现基本功能输入文件名以命令行参数传入。
- 1、统计文件的字符数
- 2、统计文件的单词总数
- 3、统计文件的有效行数
- 4、统计文件中各单词的出现次数
- 5、按照字典序输出到文件result.txt
第二步、接口封装
- 把基本功能里的:统计字符数、统计单词数、统计最多的10个单词及其词频
这三个功能独立出来,成为一个独立的模块
二:进阶需求##
新增功能,并在命令行程序中支持下述命令行参数。说明:字符总数统计、单词总数统计、有效行统计要求与个人项目相同
- 1、使用工具爬取论文信息
- 2、自定义输入输出文件
- 3、加入权重的词频统计
- 4、新增词组词频统计功能
- 5、自定义词频统计输出
- 6、多参数的混合使用
基本需求代码签入记录: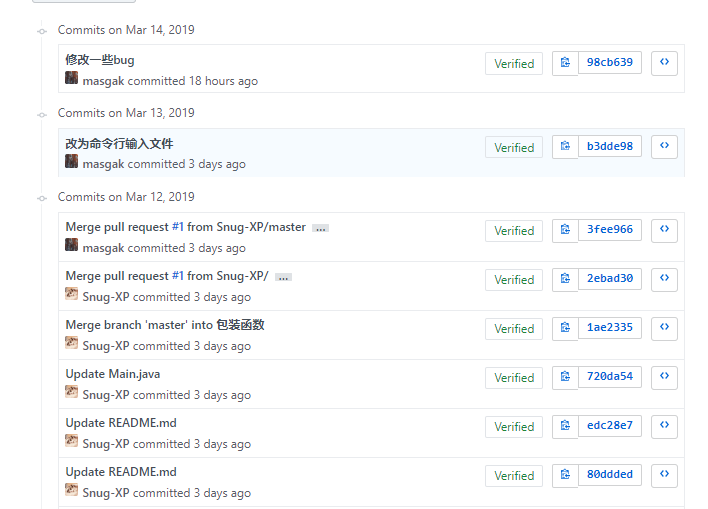
进阶需求代码签入记录:
PSP表格#
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 45 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 45 |
| Development | 开发 | 720 | 900 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 30 |
| • Design Spec | • 生成设计文档 | 0 | 0 |
| • Design Review | • 设计复审 | 120 | 100 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| • Design | • 具体设计 | 60 | 70 |
| • Coding | • 具体编码 | 720 | 900 |
| • Code Review | • 代码复审 | 300 | 240 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 180 | 240 |
| • Test Report | • 测试报告 | 0 | 0 |
| • Size Measurement | • 计算工作量 | 0 | 0 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 50 |
| 合计 | 2270 | 2710 |
解题思路描述##
爬虫部分
- 工具:python3.7
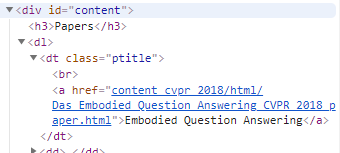
- 首先要求是爬取论文列表,并且将题目摘要等输出到文件中。因为python是典型的爬取工具,代码量较少逻辑较简单因此我们选择这个语言。查看cvpr2018年论文网页,发现论文基本详情链接都在id=content class=ptitle中(爬取的链接只是完整链接后半部分),论文列表则存储在content的表格中。
点击进入详情页就可以直接看到需求中的题目与摘要都分别存储在content下的id为papertitle abstract中
因此这次解题思路的流程图如下:
常见的python网页解析工具有:re正则匹配、python自带的html.parser模块、第三方库BeautifulSoup以及lxm库。
因为这次需要爬取的元素都直接表明了id与class,所以使用BeautifuiSoup可以直接获取信息,用其他的解析器反而需要多写判断条件。


BeautifulSoup学习参考:https://www.cnblogs.com/hanmk/p/8724162.html
java部分
- 一开始看到题目后觉得题目好繁杂,看了好多遍才大致抓住重点,又结合群里面的讨论又注意到一些原本被我忽略的细节。看到基本要求觉得还是很简单的,一个个小功能本来一开始也是打算在一次读取文件时实现,之后发现有点不方便,加上看到把各个功能独立出来的要求,就分开实现了。在进阶要求中,可以直接使用前面完成的代码,把论文爬取结果的文件去掉不需要统计的部分形成一个新文件,用这个新文件统计字符数、单词数和行数,而单词和词组的权重词频就用原文件统计。
设计实践过程##
代码组织:
221600330&221600331
|- src
|- Main.java(主程序,可以从命令行接收参数)
|- lib.java(包括所有的统计字符,行数,单词数等程序)
|- file.java(与文件流有关的程序)
|- cvpr
|- result.txt(爬虫结果)
|- cvpr.python(爬虫程序,可以爬取CVPR2018论文列表)
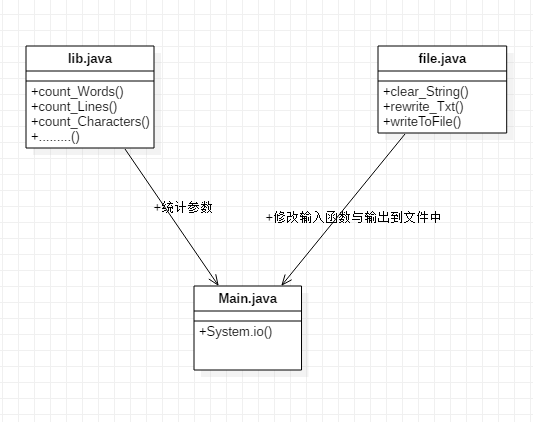
基础需求有两个类,主类接收命令参数,lib类包括基本的统计函数
进阶需求有三个类,主类接收命令参数,file类包括的函数有
public static String clear_String() //去除字符串中的非ASCII码
public static String rewrite_Txt()//去掉爬取结果中例如“Title: ”、“Abstract: ”、换行符等并写入一个新文件
public static void writeToFile()//写入文件
lib类包括的函数有
public static int count_Lines()//统计行数
public static int get_Words_Num()//统计单词数
public static Map<String, String> count_Words()//将单词与出现次数放入map中
public static int count_Characters()//统计字符数
public static Map<String, String> count_Phrase_frequency()//计算词组词频
public static Map<String, String> count_Word_Frequency()//计算单词词频
其中统计词组与单词词频函数与count_Words息息相关,这两函数的输入结果就有上个函数形成的哈希表。只有先将单词与出现次数形成一个map,才能进行后续的词频与词组频率统计。
内部实现设计(类图)##
关键算法(将单词与频率写入map)流程图##
改进思路##
- 1、使用map存储单词
- 2、使用bufferwriter发现重写文件时flush次数太多,占用大部分时间,所以改成write
- 3、判断是否为单词时想使用正则表达式,但发现一个个字符直接判断已经为O(n),以后可以再尝试下

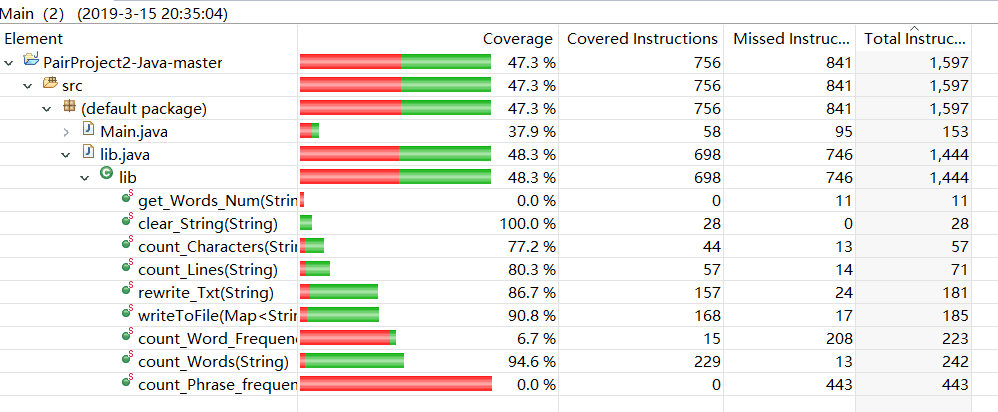
其中消耗最高的函数为clear_String(),即去除文本中无关的ascii并重写到新文件为主要消耗。
代码覆盖率(分别为单词与词组)
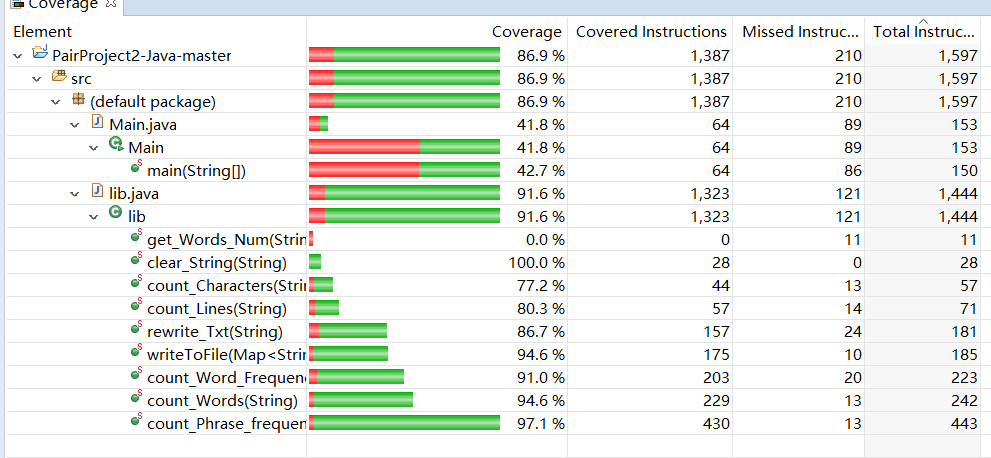
单元测试##
代码说明##
python:爬取详情页链接并循环生成新链接
cvprurl='http://openaccess.thecvf.com/CVPR2018.py'
response=requests.get(cvprurl)
soup=BeautifulSoup(response.text,'html.parser')
for links in soup.select('.ptitle'): #返回每个超链接
newlinks = 'http://openaccess.thecvf.com/'+ links.select('a')[0]['href']
python:在新连接中爬取标题与摘要并写入文档
response2 = requests.get(newlinks) #打开链接
soup2 = BeautifulSoup(response2.text,'html.parser') #把网页内容存进容器
Title = soup2.select('#papertitle')[0].text.strip() #找到标题元素爬取
print("Title:",Title,file=txt)
java:首先按行读取文件,再判断读取到的流是否为单词(至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写),如果是单词则读入hashmap中,每多读一次出现次数加一,形成最初的map数据。
public static Map<String, String> count_Words(String file_path){
......................
while ((str = bufferedReader.readLine()) != null) {
str = str.toLowerCase();
for (int i = 0; i < (str.length() - 3); i++) {
if (i > 0) {
if (('a' <= str.charAt(i - 1) && str.charAt(i - 1) <= 'z')
|| (48 <= str.charAt(i - 1) && str.charAt(i - 1) <= 57)) {// 如果前一个字符是字符或数字
continue;
}
}
if ('a' <= str.charAt(i) && str.charAt(i) <= 'z') {
if ('a' <= str.charAt(i + 1) && str.charAt(i + 1) <= 'z') {
if ('a' <= str.charAt(i + 2) && str.charAt(i + 2) <= 'z') {
if ('a' <= str.charAt(i + 3) && str.charAt(i + 3) <= 'z') {// 找到单词
int j;
for (j = i + 4; j < str.length(); j++) {// 看单词是否结束
if ('a' > str.charAt(j) || str.charAt(j) > 'z') {
if (48 > str.charAt(j) || str.charAt(j) > 57)// 不是数字
break;
}
}
String temp = str.substring(i, j);// 截取字符串索引号i到j区域(包括i,不包括j)
// 加到Map里去
if (map.containsKey(temp)) {
int n = Integer.parseInt(map.get(temp));
n++;
map.put(temp, n + "");
} else
map.put(temp, "1");
该过程的流程图为:

java:词组频率,在判断单词的基础上加个计数器计算连续出现的单词,放入字符串数组,如果次数大于词组长度,每判断一个单词就从字符串数组中该单词前M个组成个词组。
public static Map<String, String> count_Phrase_frequency(String file_path, int phraseLength, boolean is_weight)
....................................
while ((str = bufferedReader.readLine()) != null) {
str = file.clear_String(str);
str = str.toLowerCase();
// 去掉"title: "和"abstract: "
if (str.contains("title: ")) {
is_title = true;
str = str.substring(0, str.indexOf("title: ")) + str.substring(str.indexOf("title: ") + 7);
} else
is_title = false;
if (str.contains("abstract: "))
str = str.substring(0, str.indexOf("abstract: ")) + str.substring(str.indexOf("abstract: ") + 10);
int count = 0;// 计算连续出现的单词数
String[] words = new String[101];// 存储连续出现的单词
for (int i = 0; i < (str.length() - 3); i++) {
if (i > 0) {
if (('a' <= str.charAt(i - 1) && str.charAt(i - 1) <= 'z')
|| (48 <= str.charAt(i - 1) && str.charAt(i - 1) <= 57)) {// 如果前一个字符是字符或数字
continue;
}
}
if ('a' <= str.charAt(i) && str.charAt(i) <= 'z') {
if ('a' <= str.charAt(i + 1) && str.charAt(i + 1) <= 'z') {
if ('a' <= str.charAt(i + 2) && str.charAt(i + 2) <= 'z') {
if ('a' <= str.charAt(i + 3) && str.charAt(i + 3) <= 'z') {// 找到一个单词
int j;
for (j = i + 4; j < str.length(); j++) {// 看单词是否结束
if ('a' > str.charAt(j) || str.charAt(j) > 'z') {
if (48 > str.charAt(j) || str.charAt(j) > 57)// 不是数字,遇到分隔符
break;
}
}
String temp = str.substring(i, j);// 截取字符串索引号i到j区域(包括i,不包括j+1)---截取单词
if (j == str.length())// 一段中以单词结尾
temp = temp + " ";
else
temp = temp + str.charAt(j);// 把单词后面的一个分隔符加到单词中去
count++;
words[count] = temp;
if (count >= phraseLength) {
temp = words[count - phraseLength + 1];
for (int k = phraseLength; k > 1; k--) {
temp = temp + words[count - k + 2];
}
temp = temp.substring(0, temp.length() - 1);// 和并后去掉末尾的分割符
// 加到Map里去
if (is_weight && is_title)// 计算权值为10:1,并且该词组在title段中
{
if (map.containsKey(temp)) {
int n = Integer.parseInt(map.get(temp));
n += 10;
map.put(temp, n + "");
} else
map.put(temp, "10");
} else {
// 不需要计算权值
if (map.containsKey(temp)) {
int n = Integer.parseInt(map.get(temp));
n++;
map.put(temp, n + "");
} else
map.put(temp, "1");
}
int n = Integer.parseInt(map.get("count_words_num"));
n++;// 总词组个数加一
map.put("count_words_num", n + "");
}
i = j;
} else {
count = 0;
i = i + 3;
} // 遇到少于4个字母的单词,结束count
} else {
count = 0;
i = i + 2;
} // 遇到少于4个字母的单词,结束count
} else {
count = 0;
i = i + 1;
} // 遇到少于4个字母的单词,结束count
} else {
if ((48 > str.charAt(i) || str.charAt(i) > 57)) {// 遇到分隔符加到加到上一个单词末尾
words[count] += str.charAt(i);
} else {
// 遇到数字,结束count
count = 0;
}
遇到的代码模块异常或结对困难及解决方法##
- 读入文本是乱码,特别是经过多个编译器与复制下载过程,常常换个编译器注释就会乱码。
- 字符数统计出错,由于对python使用不熟练,导致爬下数据中其他不可见字符没有清除干净。统计字符常常会多几个出来,找了很久才发现这个问题。
- 电脑java编译环境没有安装好,导致无法直接编译运行.java文件。
解决办法##
- 一律使用同个编译器,或者用系统的编辑器
- 查询python去除不可见字符的方法,在此之前用别人的数据测试
- 先在eclipse中运行得到.class文件,再用cmd运行。后续再重装java环境
评价你的队友#
- 221600330:随叫随到,查资料能力强,学习效率高并乐于尝试、善于交流 需要改进:太佛性
- 221600331:善于思考,做事态度细心负责,写代码时非常拼,有坚韧不拔的态度。 需要改进:容易钻牛角尖
附加题设计与展示##
创意独到之处#
- 1,在爬取Title, abstract的基础上又爬取了页面上能找到的作者,期刊名,时间,pdf链接
- 2,各热词出现的饼图概率
爬取结果与饼图文件:https://files-cdn.cnblogs.com/files/masgak/Desktop.rar
实现思路#
- 1,继续观察论文详情页的信息可以发现在content下的class=bibref中包括了所有信息,例如无法直接看出来的期刊名称,月份等信息。
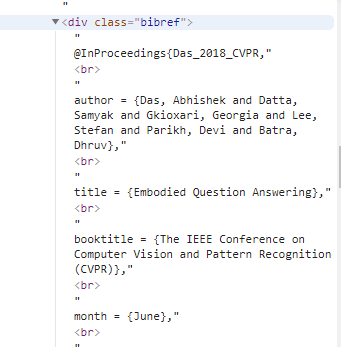
因为标题与摘要信息较为简单,前面可以使用自带的html.parser解析器直接获取,但这个信息使用html.parser更加复杂,因此选择用lxml解析器得到一个二维数组,再从二维数组中得到biber上的所有信息。
爬取结果截图:

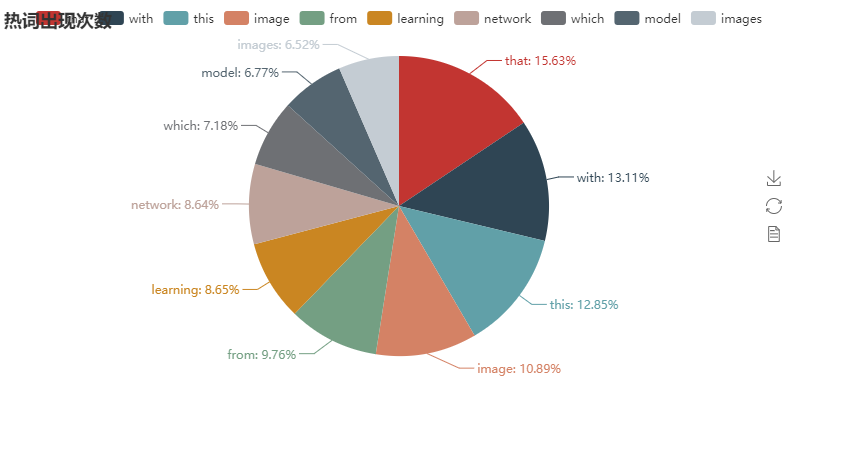
- 2,使用从wordcount中得到的十大热词数量,结合python的pyecharts画出饼图
饼图:
pyecharts代码
# coding=utf-8
from pyecharts import Pie
import random
attr = ["that","with","this","image", "from", "learning", "network", "which", "model","images"]
v1 = [1755, 1473, 1443, 1223, 1096, 971,971,807,760,732]
pie = Pie("热词出现次数")
pie.add("", attr, v1, is_label_show=True)
pie.render('pie.html')