1. 准备工作
这里我只是把我的师兄教我的关于Solrcloud搭建的过程,以及需要注意的地方文档化了。感谢他教会了我很多。
1.机子IP
三台安装linux系统的机子的IP地址为:
172.24.133.11
172.24.133.21
172.24.133.31
2.软件版本
使用的tomcat的版本是:apache-tomcat-8.0.26
使用的solr的版本是:solr-5.3.0
使用的zookeeper的版本是:zookeeper-3.4.6
3.软件解压目录
tomcat、zookeeper已经solr的解压后放置的目录为:/usr/local/apache/,如下图所示:

2. solr部署到tomcat
1.找到solr工程
solr实际上是一个web服务,所以我们需要将solr部署到tomcat下。我们需要找到solr.war这个文件。solr不同版本之间solr.war的目录是不同的。为了方便展示目录,使用win7下的目录结构,相对路径和linux上是一样的。
在win7的D盘目录下有solr5.2.1的解压包,如下图是solr5.2.1下solr.war所在的目录:
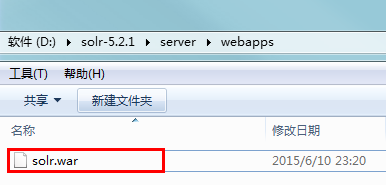
我们需要将这个solr.war解压出来,例如:

如果是solr5.3.0那么我们是找不到solr.war的,但是我们能够找到webapp,我们要做的就是将这个文件夹重命名为solr即可。
拥有文件夹solr之后我们需要做的事情是复制必要的jar包到这个文件夹中,具体的操作如下:找到如下的jar包
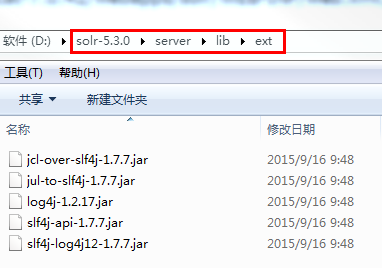
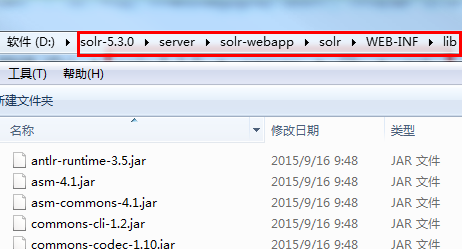
将这些jar包复制到
还需要复制log4j.properties文件到solr工程,具体目录如下:
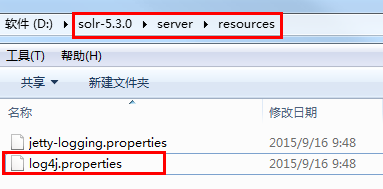
将log4j.properties复制到如下目录:

2. 拷贝solr工程到tomcat
好吧,现在我们需要将solr这个文件放置到tomcat下,具体的目录如下所示:

在linux上的目录结构也是一样的。最后solr要存放到tomcat目录下即可:

3.建立solrhome文件夹
solrhome文件夹是用于存放solr的索引的,也就是全文检索的数据。solrhome这个文件夹需要自己手动创建,位置可以任意并且名称是任意的。例如:

你需要在solr5.3.0里边找到以下两个文件并复制到multicore文件夹下:


4.修改solr工程的web.xml
虽然放置索引的位置已经找到,但是需要告诉solr项目,solrhome的目录在哪里,要不然它就找不到了。
linux下使用的代码:

修改web.xml文件中的如下红框中内容:
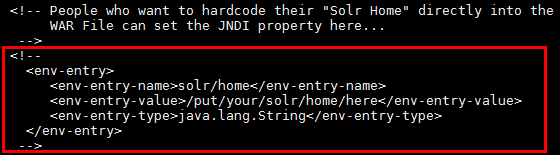
注意得要把注释的给去除:

启动tomcat输入地址localhost:8080/solr,能够看到如下的界面,说明你成功了:

如果你需要部署zookeeper集群那么你还需要进行如下的操作:
修改solrhome中的solr.xml文件,本文使用的路径为:/solr/solrhome/multicore/。添加或修改solr.xml文件中的内容:

3. zookeeper
通过上面的介绍你已经成功将solr部署到tomcat上了,但是往往需要使用zookeeper配合solr一起使用。简单讲zookeeper可以很好的管理solr服务器中的数据,可以让多个solr服务器中的数据保持同步。分别在那三台linux系统中部署zookeeper。
1.修改zoo.cfg文件中的配置
找到zoo_sample.cfg文件,重命名为:zoo.cfg,或者复制一份然后重命名为zoo.cfg。

按照一下所示对zoo.cfg文件进行添加或修改参数:

server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器,最好是使用本机ip地址的后几位数字,这样不易重复;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20 秒。
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 5*2000=10 秒。
tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔tickTime 时间就会发送一个心跳。
dataDir:顾名思义就是 Zookeeper 保存数据的目录,data目录得要自己创建,具体操作看下一步
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
2. 建立data目录
建立data目录用于存放zookeeper的数据,例如:

在data文件夹中建立myid文件。

myid中的值必须与server.A=B:C:D 中的A是一样的。根据zoo.cfg中胡配置信息。
server.11=172.24.133.11:6888:8888
server.21=172.24.133.21:6888:8888
server.31=172.24.133.31:6888:8888
myid在172.24.133.11这个机子上的值为11;myid在172.24.133.21这个机子上的值为21;myid在172.24.133.31这个机子上的值为31
实际上zookeeper集群的配置也只有myid中的内容是不一样的,它的作用就是用于表示不同的zookeeper的机子。
4. 上传schema.xml和solrconfig.xml
首先需要在任意的目录构建一个,比如:

schema.xml里边定义了solr服务器中的索引;solrconfig.xml则是solr的相关配置;其他的文件里边是没有内容的,只要创建就好。我的配置文件的:下载
上传E:111schemaless_searchconf中内容到/configs/solrcloud/schemaless_search。
public static void main(String[] args) throws Exception { // TODO Auto-generated method stub // zookeeperIP地址和端口号 String zkServerAddress = "127.0.0.1:2181"; String schemeless = "schemaless_search"; // E:111schemaless_searchconf File config = new File("E:/111/" + schemeless + "/conf"); System.out.println(config.exists()); SolrZkClient client = new SolrZkClient(zkServerAddress, 1000, 1000, new OnReconnect() { @Override public void command() {} }); ZkConfigManager configManager = new ZkConfigManager(client); // 默认添加路径:/configs 云端目录为:/configs/solrcloud/schemaless_search configManager.uploadConfigDir(Paths.get("E:/111/" + schemeless + "/conf"), "solrcloud/" + schemeless); client.close(); System.out.println("结束"); }
使索引生效:
public static void main(String[] args) throws Exception { // TODO Auto-generated method stub String collectionName = "schemaless_search"; // solr服务器的IP CloudSolrClient client = new CloudSolrClient("172.24.133.13"); CollectionAdminRequest.Delete delete = new CollectionAdminRequest.Delete(); // 如果存在schemaless_search文件夹则先删除 delete.setCollectionName(collectionName); CollectionAdminResponse response; try { response = delete.process(client); System.out.println(response); } catch (Exception e) { e.printStackTrace(); } CollectionAdminRequest.Create create = new CollectionAdminRequest.Create(); create.setCollectionName(collectionName); // 目录/configs/solrcloud/schemaless_search下找到文件并加载 create.setConfigName("solrcloud/" + collectionName); create.setNumShards(2); create.setMaxShardsPerNode(2); create.setReplicationFactor(2); response = create.process(client); client.close(); }
到目前为止所有的配置都完成了,访问solr服务器的可以看到下图。

2015-09-17 20:36:22