五、函数进阶
http://www.cnblogs.com/Eva-J/articles/7156261.html
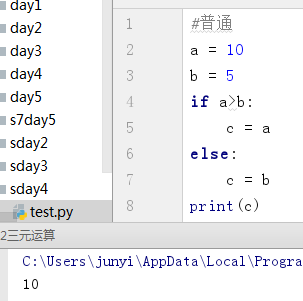
1、三元运算
#结果 = 条件成立的结果 if 条件 else 条件不成立的结果

2、名称空间
2.1 名称空间
#三种:内置、全局、局部
#内置
#全局:除了函数内部的名字之外 我们自己写的代码里所有的名字
#局部:函数内部的
#对于变量的使用:在局部可以使用全局命名空间中的名字,但是全局不可以使用局部命名空间中的名字
#对于局部来说:自己有的时候就用自己的,自己没有再用全局的
2.2 名称空间加载顺序
#启动python
#内置的命名空间
#加载全局命名空间中的名字 —— 从上到下顺序加载
#加载局部命名空间中的名字 —— 调用该函数的时候 从上到下去加载
3、作用域
3.1 作用域
#作用域
#范围从大到小:内置 全局 局部 --> 局部
#作用域链:
#使用名字的顺序,从当前位置往上一层层找,用先找到的名字
#内置的命名空间 在任意地方都可以用
#全局的命名空间 在我们写的代码里任意地方
#局部的命名空间 只能在自己的函数内使用
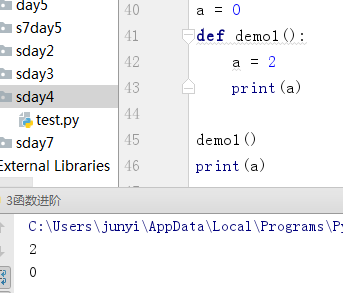
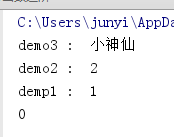
#作用域:站在范围小的局部,如果局部有用局部,局部没有往上一层找,一层一层往上找,找到第一个可用的名字就用这个
a = 0
def demo1():
a = 1
def demo2():
a = 2
def demo3():
a = '小神仙'
print('demo3 : ',a)
demo3()
print('demo2 : ',a)
demo2()
print('demp1 : ',a)
demo1()
print(a)
3.2 global,nonlocal
#global 修改全局命名空间里的变量值
#对于不可变的数据类型 如果在函数内部修改想对全局生效,就要进行global声明
#对于可变的数据类型 如果在内部想要修改,直接修改即可


#nonlocal 只修改局部命名空间里的 从内部往外部找到第一个对应的变量名


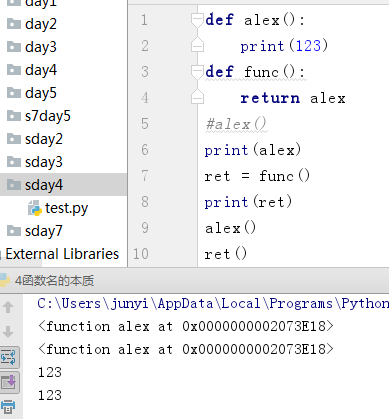
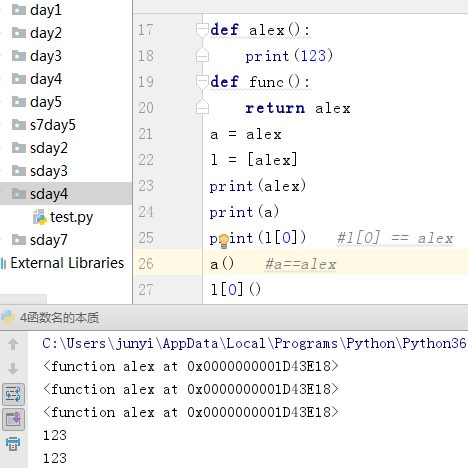
4、函数名的本质
# 函数的名字 —— 可以当作变量使用 —— 函数名是第一类对象的概念
# 首先是一个函数的内存地址
# 可以赋值,可以作为其他列表等容器类型的元素
# 可以作为函数的参数,返回值
5、闭包函数
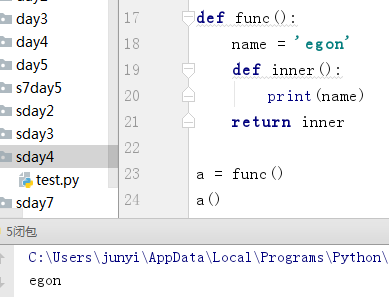
5.1 闭包函数
#内部函数 引用了 外部函数的 变量,内部的函数 就叫做闭包
def func():
name = 'egon'
def inner():
print(name)
return inner
a = func()
a()
5.2 闭包函数应用
例一
#从网页上爬取信息
from urllib.request import urlopen #模块
def get_url():
url = 'http://www.cnblogs.com/Eva-J/articles/7156261.html'
def inner():
ret = urlopen(url).read()
return ret
return inner
get_web = get_url()
res = get_web()
print(res)

例二
#requests这个模块可以爬取网站
import requests #pip install requests
def index(url):
#url = 'https://www.python.org'
def get_url():
print(requests.get(url).text)
return get_url
#python_web = index('https://www.python.org')
baidu_web = index('http://www.cnblogs.com/Eva-J/articles/7156261.html')
#python_web()
baidu_web()
6、装饰器
http://www.cnblogs.com/Eva-J/articles/7194277.html
6.1基本装饰器
装饰器本身可以是任意可调用对象,被装饰的对象本身也可以是任意可调用对象
装饰器遵循的原则:
1、不修改被装饰对象的源代码
2、不修改被调用对象的调用方式
@装饰器名,必须写在被装饰对象的正上方,并且是单独一行

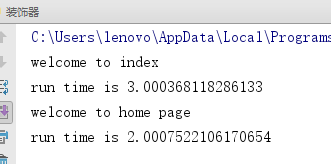
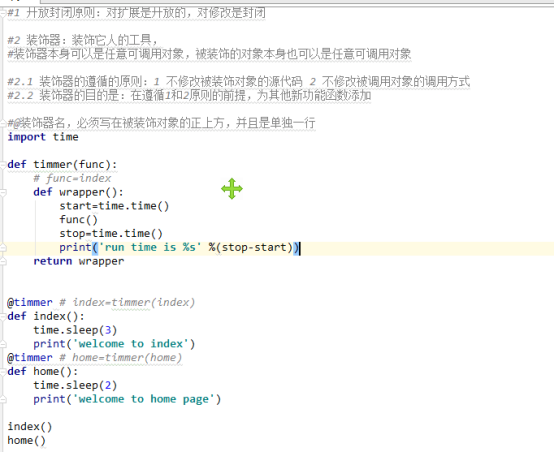
import time
def timmer(func):# func=index
def wapper():
start = time.time()
func()#index()
stop = time.time()
print('run time is %s'%(stop - start))
return wapper
@timmer# index=timmer(index)
def index():
time.sleep(3)
print('welcome to index')
@timmer# home=timmer(home)
def home():
time.sleep(2)
print('welcome to home page')
index()
home()

6.2装饰器进阶
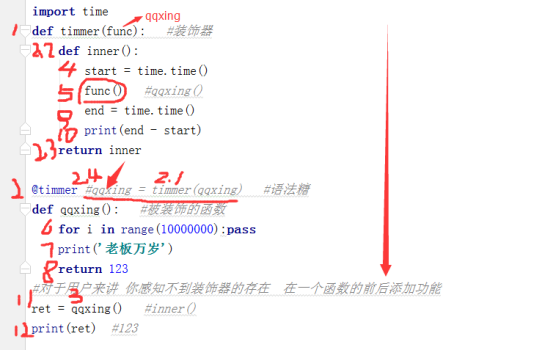
import time
def timmer(func):
def wrapper(*args,**kwargs):
start=time.time()
res=func(*args,**kwargs)
stop=time.time()
print('run time is %s' %(stop-start))
return res
return wrapper
@timmer # index=timmer(index)
def index():
time.sleep(3)
print('welcome to index')
return 123
@timmer # home=timmer(home)
def home(name):
time.sleep(2)
print('welcome %s to home page' %name)
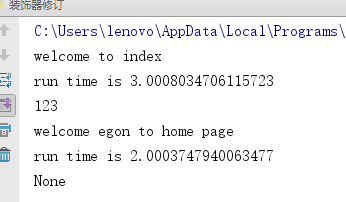
res=index() #res=wrapper()
print(res)
res1=home('egon') #wrapper('egon')
print(res1)
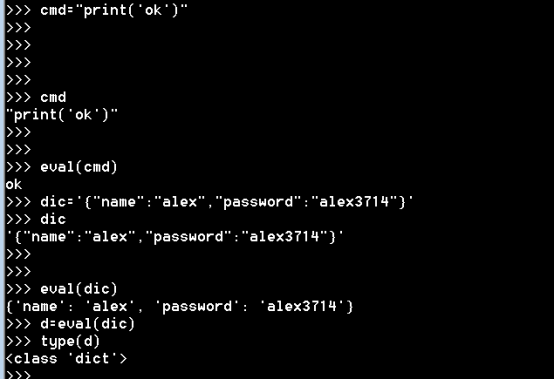
6.3 eval()
eval()是将字符串拿出来执行,如果字符串是命令,相当于执行命令
eval() #非常危险
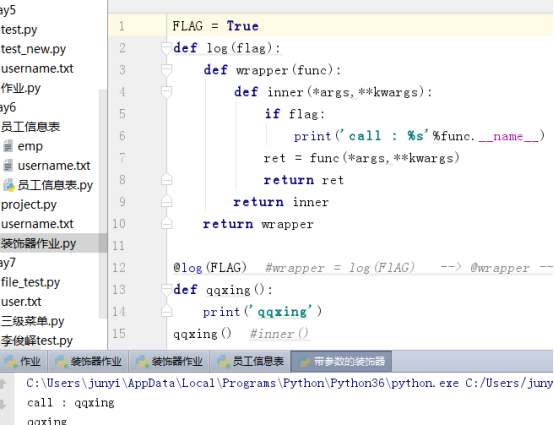
6.4 带参装饰器
FLAG = False
def log(flag):
def wrapper(func):
def inner(*args,**kwargs):
if flag:
print('call : %s'%func.__name__)
ret = func(*args,**kwargs)
return ret
return inner
return wrapper
@log(FLAG) #wrapper = log(FlAG) --> @wrapper --> qqxing = wrapper(qqxing) = inner
def qqxing():
print('qqxing')
qqxing() #inner()
修改外部变量后
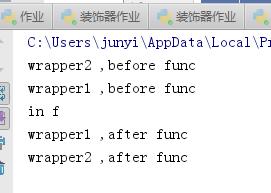
6.5 嵌套装饰器
def wrapper1(func):
def inner1():
print('wrapper1 ,before func')
func() #f
print('wrapper1 ,after func')
return inner1
def wrapper2(func):
def inner2():
print('wrapper2 ,before func')
func() #inner1
print('wrapper2 ,after func')
return inner2
@wrapper2 #f = wrapper2(wrapper1(f)) --> f = wrapper2(inner1) --> f = inner2
@wrapper1
def f():
print('in f')
f() #inner2()
7、迭代器
http://www.cnblogs.com/Eva-J/articles/7213953.html
7.1 可迭代对象iterable
7.1.1 可迭代对象
#字符串
#列表
#元组
#字典
#集合
#文件句柄、文件操作符
#range
7.1.2 判断是否是可迭代对象
(1) 导入Iterable模块
from collections import Iterable #检测一个对象是否可迭代
print(isinstance('aaa',Iterable))
print(isinstance(123,Iterable))
print(isinstance([1,2,3],Iterable))

(2)可迭代协议
__iter__方法,这个方法导致了一个数据类型的可迭代
#只要包含了“__iter__”方法的数据类型就是可迭代的 —— 可迭代协议
#数据类型和python解释器定下来的协议
# print([1,2,3].__iter__()) #list_iterator
s='hello'#字符串
l=['a','b','c','d']#列表
t=('a','b','c','d')#元组
dic={'name':'egon','sex':'m',"age":18}#字典
set1={1,2,3}#集合
f=open('db.txt')#文件
s.__iter__()
l.__iter__()
t.__iter__()
dic.__iter__()
set1.__iter__()
f.__iter__()
7.2 迭代器iterator
迭代器 就是实现了能从其中一个一个的取出值来
7.2.1判断是否是迭代器
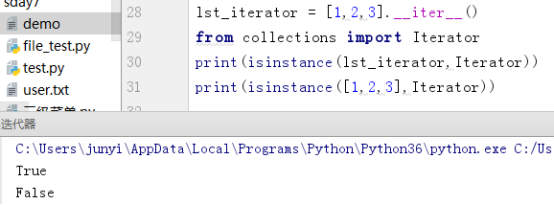
(1)导入Iterator模块
lst_iterator = [1,2,3].__iter__()
from collections import Iterator
print(isinstance(lst_iterator,Iterator))
print(isinstance([1,2,3],Iterator))
(2)迭代器协议
__next__和__iter__方法
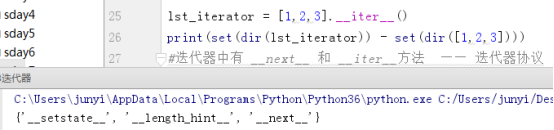
dir()查看一个数据类型有哪些方法
- 差集
7.2.2 迭代器和可迭代对象之间的关系
#在python里 你之前学过的所有的可以被for循环的 基本数据类型 都是可迭代的 而不是迭代器
#for 可以循环一个可迭代对象 也可以是一个迭代器
#迭代器一定是可迭代对象
#迭代器 = 可迭代对象.__iter__()
# f = open('file','w') #文件句柄就是一个迭代器
# range(10000000).__iter__() #range就是一个可迭代的对象
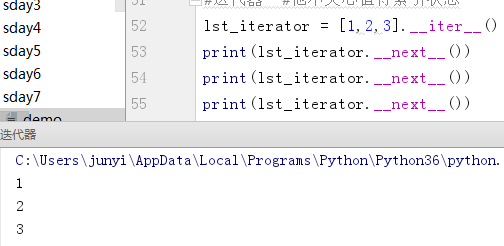
7.2.3 示例
(1)
lst_iterator = [1,2,3].__iter__()
print(lst_iterator.__next__())
print(lst_iterator.__next__())
print(lst_iterator.__next__())
(2)StopIteration
当迭代器循环完毕再循环时会报错,这是要忽略报错
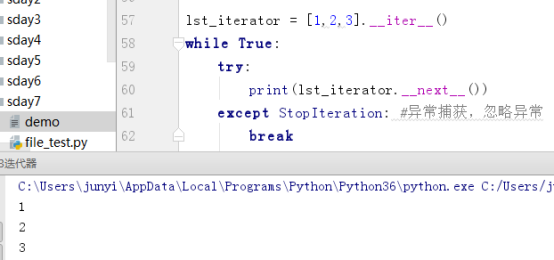
lst_iterator = [1,2,3].__iter__()
while True:
try:
print(lst_iterator.__next__())
except StopIteration: #异常捕获,忽略异常
break
7.2.4 迭代器的作用
#1.能够对python中的基本数据类型进行统一的遍历,不需要关心每一个值分别是什么
#2.它可以节省内存 —— 惰性运算
惰性运算,节省内存,防止生成大量数据占用内存
8、生成器
#Gerator #生成器
生成器就是迭代器,生成器是我们自己写出来的,所以生成器就是一个可迭代对象
有两种调用方式:
#生成器函数
#生成器表达式
8.1 生成器函数
8.1.1 生成器函数
带yield关键字的函数就是生成器函数
生成器函数在执行的时候只返回一个生成器,不执行生成器函数中的内容
从生成器中取值
1.__next__ 有几个yield就可以取几次
2.for循环取值 正常取 for i in g:
3.其他数据类型进行强制转换 list(g) 返回一个列表,里面装着生成器中的所有内容
注意:调用生成器函数的时候,要先获取生成器,再进行next取值
生成器中的内容只能取一次,且按顺序取值没有回头路,取完为止,生成器里面的值在用的时候才取.
8.1.2 调用生成器函数
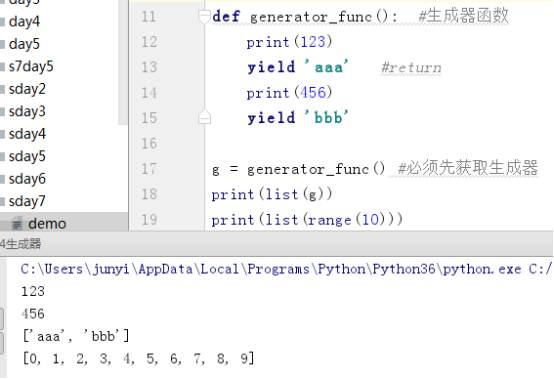
(1)
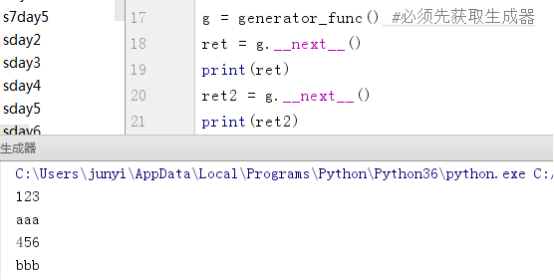
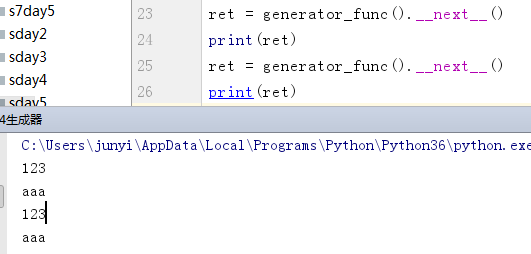
def generator_func(): #生成器函数
print(123)
yield 'aaa' #return
print(456)
yield 'bbb'
g = generator_func() #必须先获取生成器
ret = g.__next__()
print(ret)
ret2 = g.__next__()
print(ret2)
调用生成器函数时必须先获取生成器,不获取生成器会出现下面情况:

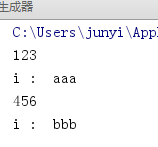
(2)for循环调用
#生成器的本质就是迭代器

(3)list()
list()可以直接接收一个可迭代对象
# #三种方法从生成器中取值
#1.a.__next__()
#2.for
for i in laomuji:
print(i)
#3.list强转
# print(list(a))
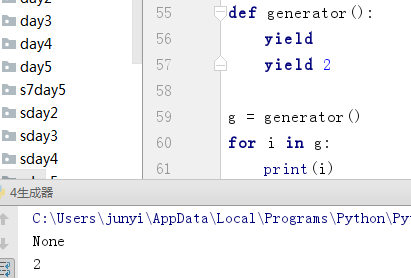
8.2 yield
8.2.1
我的理解是yield把应该返回的所有的值存到了一个虚拟的列表里,然后我们在想办法从列表里取数。同时可以把结果理解成像直接print()一样。
yield像return一样可以返回None
8.2.2 示例
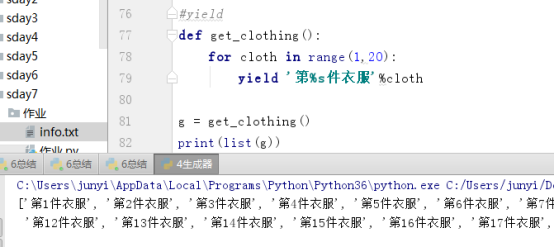
(1)
#yield
def get_clothing():
for cloth in range(1,2000000):
yield '第%s件衣服'%cloth
generate = get_clothing()
# print(generate.__next__())
# print(generate.__next__())
# print(generate.__next__())
#
for i in range(50):
print(generate.__next__())
(2)
def get_clothing():
for cloth in range(1,2000000):
yield '第%s件衣服'%cloth
for i in get_clothing():
print(i)
if i == '第100件衣服':
break
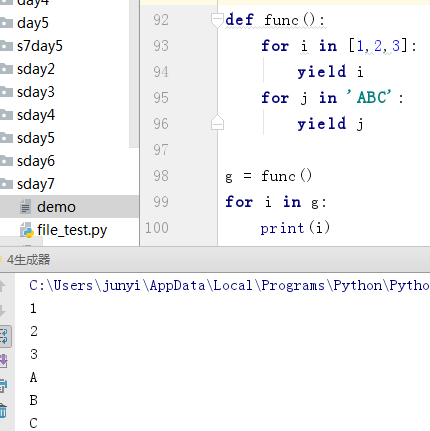
8.2.3 yield from
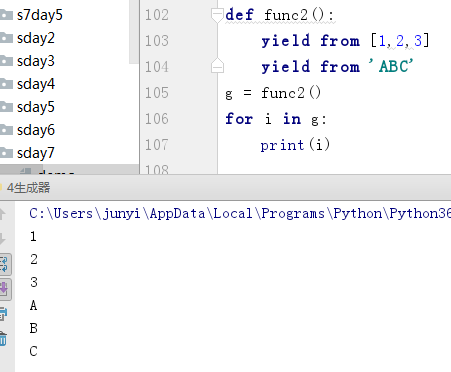
yield from是py3特有的,它和for循环的作用一样
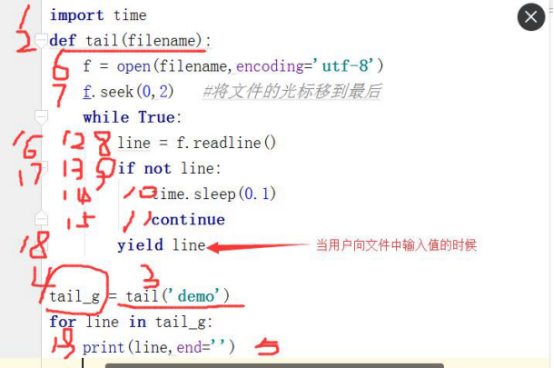
8.3 生成器实例
import time
def tail(filename):
f = open(filename,encoding='utf-8')
f.seek(0,2) #将文件的光标移到最后
while True:
line = f.readline()
if not line:
time.sleep(0.1)
continue
yield line
tail_g = tail('demo')
for line in tail_g:
print(line,end='')
8.4 send()
8.4.1 send()
#首先:send和next工作的起止位置是完全相同的
# send可以把一个值作为信号量传递到函数中去
# 在生成器执行伊始,只能先用next
# 只要用send传递参数的时候,必须在生成器中还有一个未被返回的yield
# 可以看成send和__next__的功能相同但是send多了传值功能

g.__next__()激活生成器,每个生成器都要先激活一次
g.send('aaa')把'aaa'赋值给value,赋值之后要再用一个yield来返回或结束
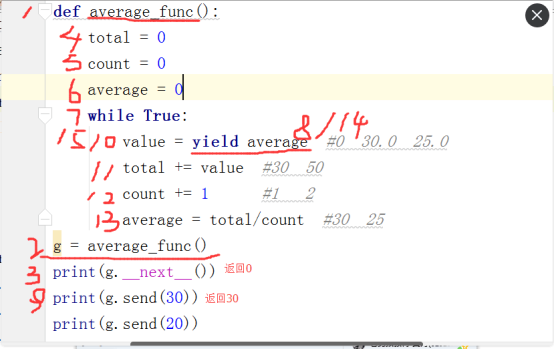
8.4.2 生成器预激装饰器
def wrapper(func): #生成器预激装饰器
def inner(*args,**kwargs):
g = func(*args,**kwargs) #g = average_func()
g.__next__()
return g
return inner
@wrapper
def average_func():
total = 0
count = 0
average = 0
while True:
value = yield average #0 30.0 25.0
total += value #30 50
count += 1 #1 2
average = total/count #30 25
g = average_func()
print(g.send(30))
print(g.send(20))
print(g.send(10))
# print(g.__next__()) #激活生成器
# print(g.send(30))
# print(g.send(20))
# print(g.send(10))
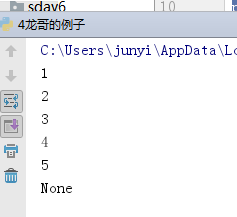
8.4.3 示例
def func():
print(1)
yield 2
print(3)
value = yield 4 #没有给value值所以value为None
print(5)
yield value
g = func()
print(g.__next__()) # 1 2
print(g.send(88)) #send(88)把88给了yield 2 # 3 4
print(g.__next__()) # 5 None没有给value赋值

8.5 生成器表达式
# 列表推导式[] - 生成器表达式()
# 尽量让推导式简化你的操作,增强代码的可读性
# 如果推导式过于复杂了,应该转换成普通的python代码
# 所有的列表推导式都可以转换成生成器表达式,并且应该在代码中尽可能多使用生成器表达式而不是列表推导式
#在代码里 多层嵌套的for循环是禁忌 —— 会大幅度增加代码的复杂度
8.5.1 列表推导式
#列表推导式 == 列表表达式 :简化代码
(1)
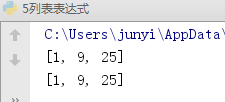
new_l = []
for i in [1,3,5]:
new_l.append(i*i)
print(new_l)
print([i*i for i in [1,3,5]]) #结果必须是一个列表
(2)
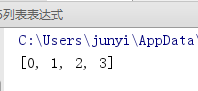
print([i//2 for i in range(0,7,2)])
print(['egg%d'%i for i in range(10)])

8.5.2 生成器表达式
#生成器表达式 —— 节省内存,简化代码
(1)
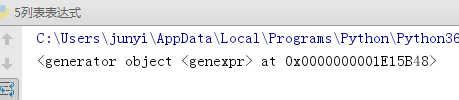
laomuji = ('egg%d'%i for i in range(10)) #这是个生成器
print(laomuji)
(2)
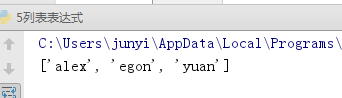
l = [{'name':'alex','age':80},{'name':'egon','age':40},{'name':'yuan','age':30},{'name':'nezha','age':18}]
print([d['name'] for d in l if d['age'] > 18]) #年龄大于18的所有人的名字
(3)
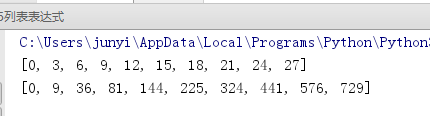
# 30以内能被3整除的数 [0,1,2,3,4,5,6] = [0,3,6]
print([num for num in range(30) if num%3 == 0])
# 30以内能被3整除的数的平方
def func(i):
return i*i
print([func(num) for num in range(30) if num%3 == 0])
8.5.3 生成器面试题
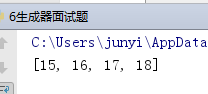
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g=test() #(0,1,2,3)
for n in [1,10,5]: #for循环只产生生成器,并不会启动生成器g
g=(add(n,i) for i in g)
print(list(g))
#g = (add(n, i) for i in test()) #n=1
#g = (add(n, i) for i in (add(n, i) for i in test())) #n=10
#g = (add(n, i) for i in (add(n, i) for i in (add(n, i) for i in (add(n, i) for i in test())))) #n=5
#g = (add(1, i) for i in test()) #(1,2,3,4)
#g = (add(10, i) for i in (add(10, i) for i in test())) #(21,22,23,24)
#g = (add(5, i) for i in (add(5, i) for i in (add(5, i) for i in (add(n, i) for i in test())))) #(15,16,17,18)

9、递归
http://www.cnblogs.com/Eva-J/articles/7205734.html
9.1 递归
#什么是递归 #recursion 递归
#一个函数在内部调用自己
#递归的层数在python里是有限制的
#解耦 要完成一个完整的功能,但这个功能的规模要尽量小,并且和这个功能无关的其他代码应该和这个函数分离
#1.增强代码的重用性
#2.减少代码变更的相互影响
9.2 实例
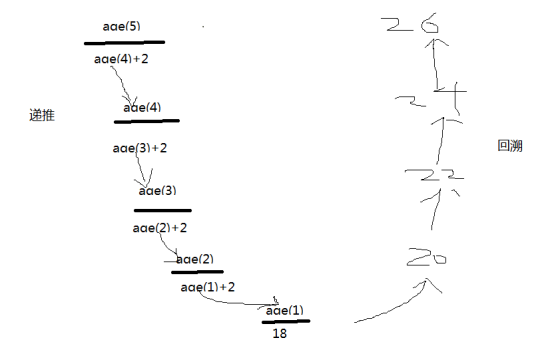
9.2.1 求alex年龄
#写递归函数时先找到函数结束的点
alex比egon小两岁,egon比武sir小两岁,武sir比金鑫小两岁,金鑫今年40岁
#alex
#1 alex egon + 2 n=1 age(1) = age(2) + 2
#2 egon wusir + 2 n=2 age(2) = age(3) +2
#3 wusir 金鑫 + 2 n=3 age(3) = age(4) +2
#4 金鑫 40 n=4 age(4) = 40
def age(n):
if n == 4:
return 40
else:
return age(n+1) + 2
print(age(1))
#推倒过程 一层一层推
# def age(1): #46
# if n == 4:
# return 40
# else:
# return age(2) + 2 #44+2
#
# def age(2): #44
# if n == 4:
# return 40
# else:
# return age(3) + 2 #42+2
#
# def age(3): #42
# if n == 4:
# return 40
# else:
# return age(4) + 2 # 40 +2
9.2.2 求阶乘
#求阶乘 n = 7 7*6*5*4*3*2*1
# func(2) == func(1)*2
# func(3) == func(2)*3
# func(4) == func(3)*4
def func(n):
if n == 1:
return 1
else:
return func(n-1)*n
print(func(5))
# #推倒过程 一层一层推
# def func(7):#5040
# if n == 1:
# return 1
# else:
# return func(6)*7# #1*2*3*4*5*6*7
#
# def func(6):#720
# if n == 1:
# return 1
# else:
# return func(5) * 6#1*2*3*4*5*6
#
# def func(5):#120
# if n == 1:
# return 1
# else:
# return func(4) * 5 #1*2*3*4*5
#
# def func(4): #24
# if n == 1:
# return 1
# else:
# return func(3) * 4 #1*2*3*4
#
# def func(3): # 6
# if n == 1:
# return 1
# else:
# return func(2) * 3 #1*2*3
#
# def func(2): #2
# if n == 1:
# return 1
# else:
# return func(1) * 2 #1*2
9.2.3 二分查找
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
def search(num,l,start=None,end=None):
start = start if start else 0
end = end if end else len(l) - 1
mid = (end - start)//2 + start
if start > end:
return None
elif l[mid] == num:
return mid
elif l[mid] < num:
return search(num,l,mid+1,end)
elif l[mid] > num:
return search(num,l,start,mid-1)
print(search(66,l))
# def search(num,l,start=None,end=None): #66,l
# start = start if start else 0 # 0
# end = end if end else len(l) - 1 # 24
# mid = (end - start)//2 + start # 12
# if start > end:
# return None
# elif l[mid] == num:
# return mid
# elif l[mid] < num: # 41<66
# return search(num,l,mid+1,end) #search(66,l,13,24)
# elif l[mid] > num:
# return search(num,l,start,mid-1)
# def search(num,l,start=None,end=None): #66,l
# start = start if start else 0 # 13
# end = end if end else len(l) - 1 # 24
# mid = (end - start)//2 + start # 18
# if start > end:
# return None
# elif l[mid] == num:
# return mid
# elif l[mid] < num:
# return search(num,l,mid+1,end)
# elif l[mid] > num: #67 > 66
# return search(num,l,start,mid-1) #search(66,l,13,17)
# def search(num,l,start=None,end=None): #66,l
# start = start if start else 0 # 13
# end = end if end else len(l) - 1 # 17
# mid = (end - start)//2 + start # 15
# if start > end:
# return None
# elif l[mid] == num:
# return mid
# elif l[mid] < num: #55 < 66
# return search(num,l,mid+1,end) #search(66,l,14,17)
# elif l[mid] > num:
# return search(num,l,start,mid-1)
# def search(num,l,start=None,end=None): #66,l
# start = start if start else 0 # 14
# end = end if end else len(l) - 1 # 17
# mid = (end - start)//2 + start # 16
# if start > end:
# return None
# elif l[mid] == num:
# return mid
# elif l[mid] < num: #56 < 66
# return search(num,l,mid+1,end) #search(66,l,17,17)
# elif l[mid] > num:
# return search(num,l,start,mid-1)
# def search(num,l,start=None,end=None): #66,l
# start = start if start else 0 # 117
# end = end if end else len(l) - 1 # 17
# mid = (end - start)//2 + start # 17
# if start > end:
# return None
# elif l[mid] == num: #66==66
# return mid #17
# elif l[mid] < num:
# return search(num,l,mid+1,end)
# elif l[mid] > num:
# return search(num,l,start,mid-1)
# print(search(66,l))
9.2.4 三级菜单
#三级菜单
menu = {
'北京': {
'海淀': {
'五道口': {
'soho': {},
'网易': {},
'google': {}
},
'中关村': {
'爱奇艺': {},
'汽车之家': {},
'youku': {},
},
'上地': {
'百度': {},
},
},
'昌平': {
'沙河': {
'老男孩': {},
'北航': {},
},
'天通苑': {},
'回龙观': {},
},
'朝阳': {},
'东城': {},
},
'上海': {
'闵行': {
"人民广场": {
'炸鸡店': {}
}
},
'闸北': {
'火车战': {
'携程': {}
}
},
'浦东': {},
},
'山东': {},
}
(1) 用递归
#相同的数据类型 嵌套在一起
def three_level_menu(menu):
while True:
for i in menu:
print(i)
choice = input('>>>:').strip()
if choice in menu:
res = three_level_menu(menu[choice])
if res == 'q':
return 'q'
elif choice == 'b':
break
elif choice == 'q':
return 'q'
three_level_menu(menu)
(2) 类递归
def three_level_menu(menu):
li = [1]
while menu != 1:
for i in menu:print(i)
choice = input('>>>:').strip()
if choice in menu:
li.append(menu)
if menu[choice]:
menu = menu[choice]
if choice == 'q':break
if choice == 'b':menu = li.pop()
three_level_menu(menu)
9.2.5 面试真题
# 有⼀个数据结构如下所⽰,请编写⼀个函数从该结构数据中返回由指定的字段和对应的值组成的字
# 典。如果指定字段不存在,则跳过该字段。(10分)
# data={'time':'2016-08-05T13;13:05',
# 'some_ID':'ID1234',
# 'graps1':{'fld1':1,'fld2':2},
# 'xxx2':{'fld3':0,'fld5':0.4},
# 'fld6':11,
# 'fld7':7,
# 'fld':8
# }
# fields:由"|"连接的以"fld"开头的字符串,如:fld2|fld3|fld7|fld19
# def select(data,fields):
# # TODO:implementation
# return result
(1) 递归方法
#递归
def selete(data,fields):
fields_list = fields.split('|')
result = {}
for key in data:
if type(data[key]) == dict:
res = selete(data[key], fields)
result.update(res)
if key in fields_list:
result[key] = data[key]
return result
data={'time':'2016-08-05T13;13:05',
'some_ID':'ID1234',
'graps1':{'fld1':1,'fld2':2},
'xxx2':{'fld3':0,'fld5':0.4},
'fld6':11,
'fld7':7,
'fld':8
}
fields = 'fld2|fld3|fld7|fld19'
print(selete(data,fields))
(2) 类递归方法
def select(data,fields):
data_list = [1]
result = {}
fields_list = fields.split('|')
while data != 1:
for key in data:
if type(data[key]) == dict:
data_list.append(data[key])
if key in fields_list:
result[key] = data[key]
data = data_list.pop()
return result
data={'time':'2016-08-05T13;13:05',
'some_ID':'ID1234',
'graps1':{'fld1':1,'fld2':2},
'xxx2':{'fld3':0,'fld5':0.4},
'fld6':11,
'fld7':7,
'fld':8
}
fields = 'fld2|fld3|fld7|fld19'
print(select(data,fields))
9.2.6 斐波那契数列
#1,1,2,3,5,8
def fib(n):
if n==1 or n==2:
return 1
return fib(n-1) + fib(n-2)
10、内置函数
http://www.cnblogs.com/Eva-J/articles/7206498.html
https://www.processon.com/view/link/597fcacfe4b08ea3e2454ece
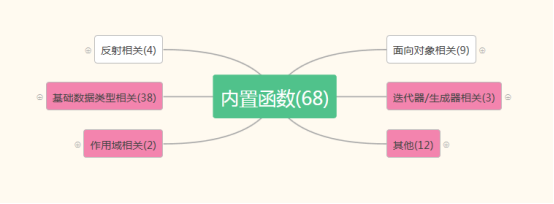
10.1 globals()、locals()

# 局部作用域中的变量 —— locals() #本地
# 全局作用域中的变量 —— globals()
# 在全局执行这两个方法,结果相同
# 在局部执行,locals表示函数内的名字,globals始终不变
10.2 iter()、next()、range()
iter()和next()与__iter__、__next__功能一样
# 在python里 要尽量少去调用双下方法
def iter(iterable):
return iterable.__iter__()
# 在python里 要尽量少去调用双下方法
print([1,2,3].__iter__()) #内置的特殊成员
iterator = iter({1,2,3,4})
def next(iterator):
return iterator.__next__()
print(next(iterator)) #iterator.__next__()
print(next(iterator))
print(next(iterator))
range()
range(100) #[0,99] [0,100)
range(10,100) #[10,99]
range(10,100,2) #[10,99]隔一个取一个
可迭代对象 最好循环取结果
10.3 eval()、exec()、complie()
#执行字符串数据类型的python代码
当使用时要检测是否有os模块,很危险
#直接拿来执行的方式一定不要随便用
#如果非用不可,你也要做最起码的检测
#eval : 有返回值
#exec :没有返回值
#complie:当需要对某一个字符串数据类型的python代码多次执行的时候,就是用compile先编译一下
code1 = 'for i in range(0,10): print (i)'
compile1 = compile(code1,'','exec') #编译
# print(compile1) #code
exec(compile1)
code2 = '1 + 2 + 3 + 4'
compile2 = compile(code2,'','eval')
print(eval(compile2))
10.4 input()、print()
10.4.1 input()
input()
#a = input('>>>'),使用时最好写上提示标识
10.4.2 print()
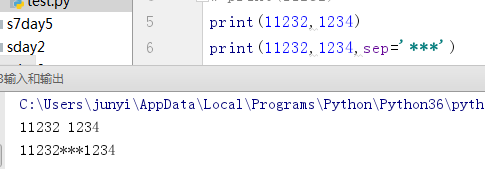
sep设置以什么为分隔符,默认以一个空格
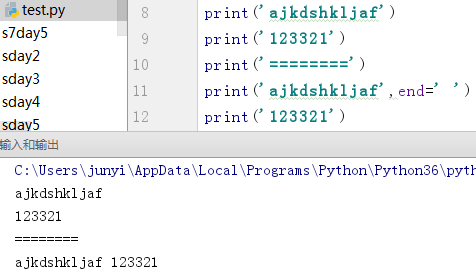
end 设置以什么结尾,默认以换行符 结尾
file写入到某个文件,可以做记日志用

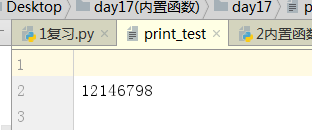
flush fluse=True实时刷新,每打印一次都会显示,默认flush=Falsh
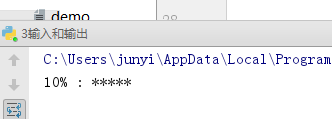
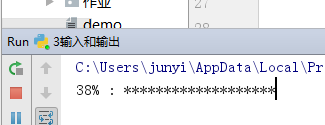
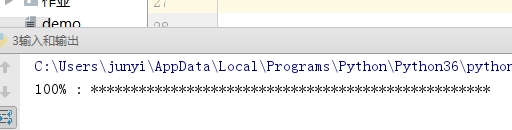
进度条实例
import time
for i in range(0,101,2):
time.sleep(0.5)
char_num = i//2 #打印多少个'*'
per_str = '
%s%% : %s
' % (i, '*' * char_num) if i == 100 else '
%s%% : %s'%(i,'*'*char_num)
print(per_str,end='', flush=True)
#小越越 :
可以把光标移动到行首但不换行
10.5 hash()、id()
10.5.1 hash()
#hash 在python的一次执行中,对于相同的可hash对象来说,得到的是相同的数字
url = 'http://xhpfmapi.zhongguowangshi.com/share/index.html?docid=2269496&channel=weixin'
from urllib.request import urlopen
content = urlopen(url).read()
dic = {hash(url):content}#可以用在字典key上 节省内存 而且方便直接查找
hash(url) #数字
这样key变成了一串数字,可以更好的节省内存
10.5.2 id()
#身份运算 is is not 不仅比较值的大小还比较内存地址是否一致
# == 值运算 只比较值的大小
10.6 filter()、map()
http://www.cnblogs.com/Eva-J/articles/7266192.html
10.6.1 filter()
#filter() 接收一个方法 接收一个可迭代对象 然后把可迭代对象的每一个值拿到方法里面,如果返回True,放到新的列表里,然后返回一个迭代器 filter帮你遍历
#filter()和列表推导式很像 [i for i in lst if i > 10]
# #func,iterable
def func(n):
if n%2 == 0:
return True
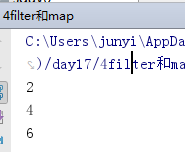
lst = [1,2,3,4,5,6,7]
ret = filter(func,lst) #过滤
#返回一个迭代器
for i in ret:
print(i)
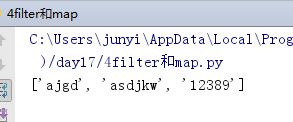
lst2 = ['ajgd','asdjkw','12389',[],(),123,124]
def func2(n):
if type(n) is str:return True
new_ret = filter(func2,lst2)
print(list(new_ret))
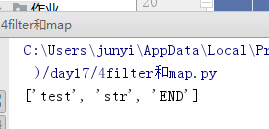
lst = ['test', None, '', 'str', ' ', 'END']
def func2(m):
if m and m.strip():
return True
print(list(filter(func2,lst)))
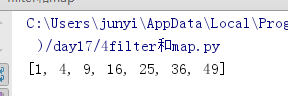
10.6.2 map()
map()和filter()很像但是没有条件,会把所有的值都返回,与没有条件的列表表达式很像。
[i for i in lst]
#map
# [i for i in lst]
lst = [1,2,3,4,5,6,7]
def func(item):
return item*item
print(list(map(func,lst)))
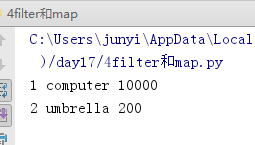
10.7 enumerate()
把可迭代对象的索引拿出来
se = {'computer':10000,'umbrella':200}
# for k in se:
# print(k,se[k])
for num,goods in enumerate(se,1):#第二个参数设置序号从几开始
print(num,goods,se[goods])
10.8 数据类型
bool()
int()
float()
complex()
10.9 数学运算
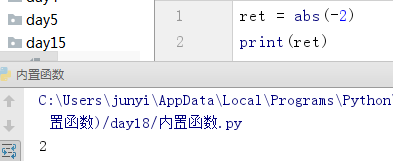
10.9.1 abs()
取绝对值
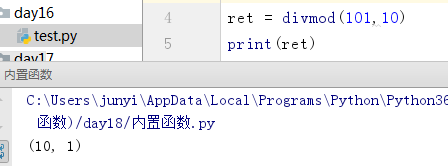
10.9.2 divmod()
取商和余数
做分页的时候可以用这个函数
divmod(a,b)
# (a//b,a%b)
#(商,余)
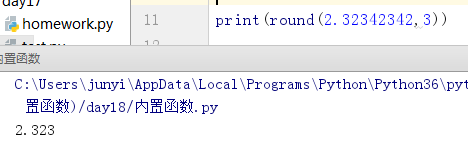
10.9.3 round()
小数精确到几位
10.9.4 pow()
幂运算
pow(x,y) #x**y
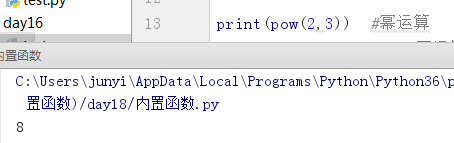
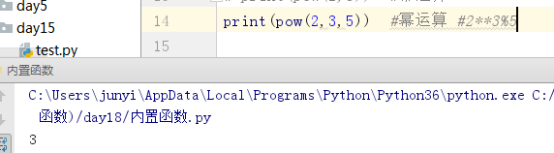
pow(x,y,z) #x**y%z
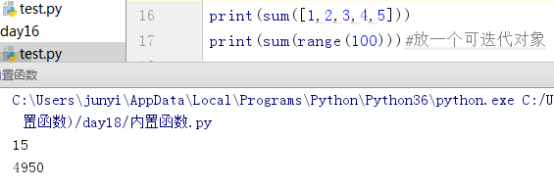
10.9.5 sum()
求和
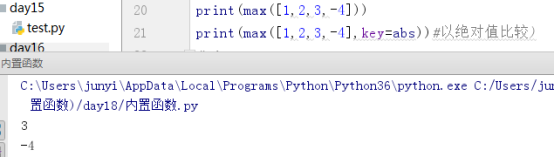
10.9.6 min()、max()
求最小值和最大值
#min max
# 可以接收散列的值,和可迭代的对象
# key是一个函数名,判断的结果根据函数的返回值来确定
# defult 如果可迭代对象为空,设置默认最小值
10.10 数据结构相关
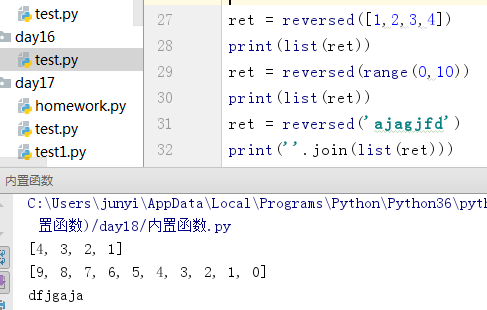
10.10.1 reversed()
反转,返回一个迭代器
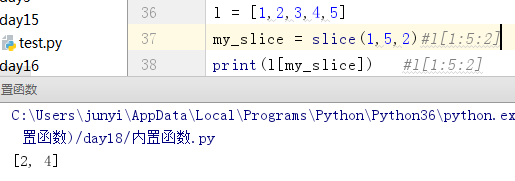
10.10.2 slice()
切片
10.10.3 format()
http://www.cnblogs.com/Eva-J/articles/7266245.html
1. 函数功能将一个数值进行格式化显示。
2. 如果参数format_spec未提供,则和调用str(value)效果相同,转换成字符串格式化。
3. 对于不同的类型,参数format_spec可提供的值都不一样

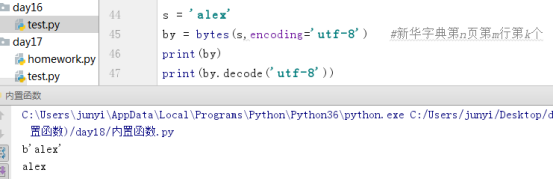
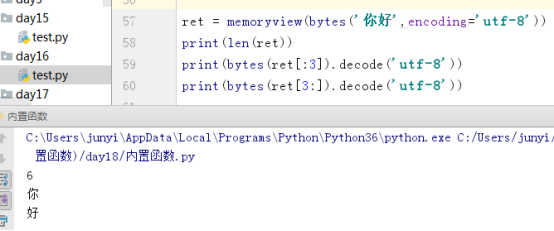
10.10.4 bytes()、bytearray()、

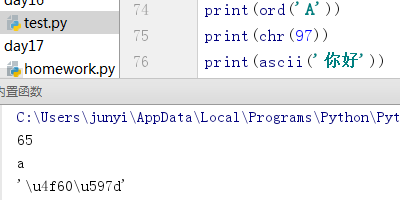
10.10.5 ord()、chr()、ascii()
ord()字符按照unicode转数字
chr()数字按照unicode转字符
ascii()字符转ascii
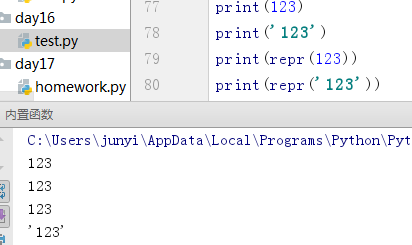
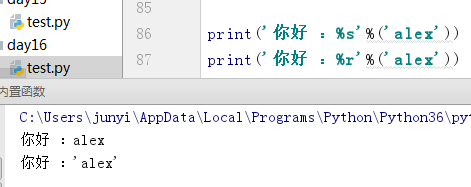
10.10.6 repr()
用于r%格式化输出
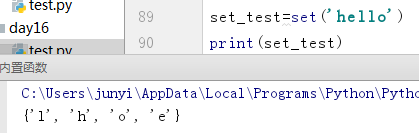
10.11 集合
10.11.1 set()
转集合
10.11.2 frozenset()
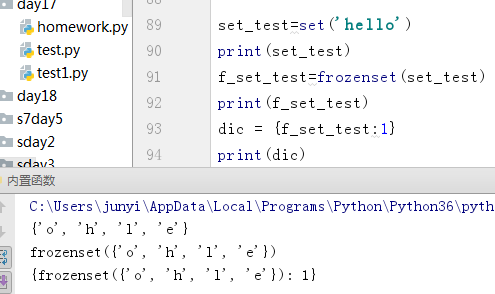
10.12 相关内置函数
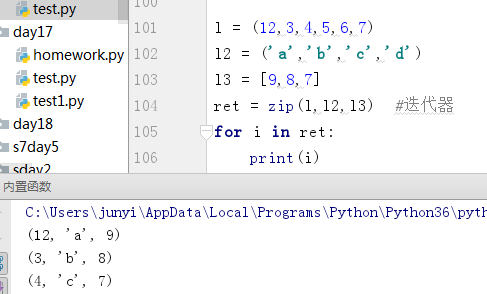
10.12.1 zip()
拉链
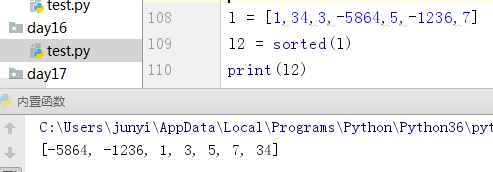
10.12.2 sortrd()
排序
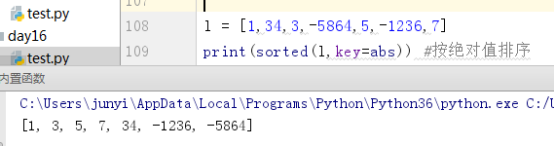
按绝对值排序
按长度排序

11、匿名函数
11.1 匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
一般map filter sorted max min与匿名函数有关
精髓就是匿名函数和内置函数一起用
#匿名函数 —— lambda表达式
#一句话的python
#三元运算
#各种推导式、生成器表达式
#lambda表达式
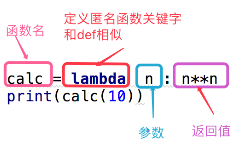
函数名 = lambda 参数 :返回值
#参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
11.2 练习
1.下面程序的输出结果是:
d = lambda p:p*2
t = lambda p:p*3
x = 2
x = d(x)
x = t(x)
x = d(x)
print(x)
24
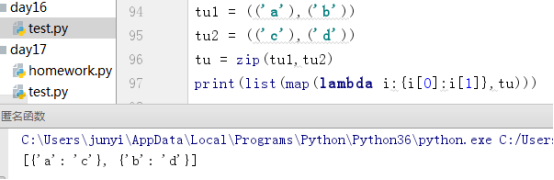
2.现有两元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
tu1 = (('a'),('b'))
tu2 = (('c'),('d'))
tu = zip(tu1,tu2)
print(list(map(lambda i:{i[0]:i[1]},tu)))
3.以下代码的输出是什么?请给出答案并解释。
def multipliers():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in multipliers()])
请修改multipliers的定义来产生期望的结果。
上面函数相当于:
def multipliers():
li = []
for i in range(4):
def lamb(x):
return x*i
li.append(lamb)
return li
li1 = []
for func in multipliers():
func(2)
li1.append(func(2))
print(li1)
修改后:
def multipliers():
return (lambda x:i*x for i in range(4))
print(list((m(2) for m in multipliers())))
[0, 2, 4, 6]
12、小结
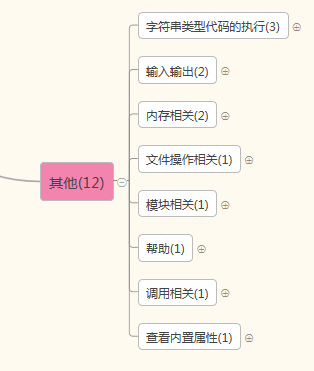
请务必重点掌握:
其他:input,print,type,hash,open,import,dir
str类型代码执行:eval,exec
数字:bool,int,float,abs,divmod,min,max,sum,round,pow
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,bytes,repr
序列:reversed,slice
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,zip,filter,map