一、测序质量值的意义
测序仪一般是按照荧光信号来判断所测序的碱基是哪一种,例如红黄蓝绿分别对于ATCG,因此,对于每个结果的判断都是一个概率的问题
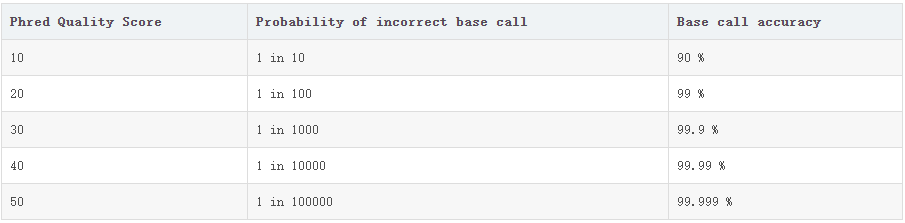
Phred Quality Score:分段质量分数
Probability of incorrent base call:错误率
Base call accuracy:准确率
1、最初Sanger中心用Phred Quality Score来衡量该read中每个碱基的质量:Q=-10logP ,其中P代表该碱基被测序错误的概率,如果该碱基测序出错的概率为0.001,则Q应该为30,那么30+33=63,那么63对应的ASCii码为“?”,则在该碱基对应的质量值即“?”。
2、Solexa系列测序仪使用不同的公示来计算质量值:Q=-10log(P/1-P)
3、在测序质量较高时,这两种算法得到的Q值没有显著差别
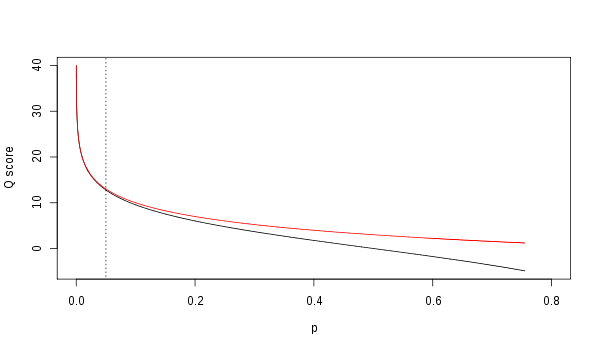
Qscore与p之间的关系,其中红线表示Q=-10 log10p标准,黑色实线表示Q=-10 log10p/(1-p)标准。
为什么不直接存储概率呢——在测序仪测序时,会自动根据荧光信号的强弱给出一个参考的测试错误概率(error probility,P)根据定义来看,P值肯定是越低越好。我们怎么存储他们呢?直接存储小数的话计算机会以浮点数的形式进行存储。这显然是不高效的。
所以有了如下办法:
1、将P取log10之后再乘以-10,得到的结果为Q。
比如,P=1%,那么对应的Q=-10*log10(0.01)=202、把这个Q加上33或者64转成一个新的数值,称为Phred,最后把Phred对应的ASCII字符对应到这个碱基。这样就可以用1个符号与1个碱基一一对应
如Q=20,Phred = 20 + 33 = 53,对应的符号是”5”二、ASCII码
为了方便可读及存储这些信息,利用可打印的ASCI码将这些质量值转化为单个字符。ASCII 字符集,最基本的包含了128 个字符。其中前 32 个, 0-31 ,即 0x00-0x1F ,都是不可见字符,这些字符,为控制字符。可见字符为32–126。sanger-fastaq格式用 ASCII 33–126 来表示phred 质量值 0 到93 。举例来说:一般地,碱基质量从0-40,既ASCii码为从 “!”(0+33)到“I”(40+33)。如果某碱基测序出错的概率为0.001,则Q应该为30。则30+33=63,那么63对应的ASCii码为“?”,在第四行中该碱基对应的质量代表值即为“?”
三、fastQ格式
FASTQ是一种存储了生物序列(通常是核酸序列)以及相应的质量评价的文本格式。FASTQ格式是序列格式中常见的一种,FASTQ格式的序列一般包括四行:
第一行由’@‘开始,后面跟着序列的描述信息,这点跟FASTA格式是一样的;
第二行是序列;
第三行由’+‘开始,后面也可以跟着序列的描述信息
第四行是第二行序列的质量评估,字符数和第二行的序列是相等的
举例分析:

第一行:以@开头,后面是reads的ID以及其他信息,例如上例中 HWUSI-EAS100R代表Illumina设备名称,6代表flowcell中的第六个lane,73代表第六个lane中的第73个tile,941:1973代表该read在该tile中的x:y坐标信息;#0,若为多样本的混合作为输入样本,则该标志代表样本的编号,用来区分个样本中的reads;/1代表paired end中的前一个read。
第二行:read序列
第三行:以“+”开头,跟随着该read的名称(一般@后面的内容相同),但有时可以省略,但“+”一定不能省。
第四行:表示质量值,每个字符与第二行的碱基一一对应,按照一定的转换规则转换为碱基质量得分,进而反映该碱基的错误率,因此字符数必须和第二行保持一致。
四、fasta格式
fasta格式:是一种基于文本用于表示核酸序列或多肽序列的格式。其中核酸或氨基酸均以单个字母表示,且允许在序列前添加序列名及注释。由两部分信息组成:

第一部分:以>号开始,紧接着序列的标识符“gi|187608668|ref|NM_001043364.2|”,然后是序列的描述信息。注意区分大小写,且不能出现空格,空格表示序列标识符结束。
所有来源于NCBI的序列都有一个gi号“gi|gi_identifier”,gi号由数字组成,具有唯一性。一条核酸或者蛋白质改变了,将赋予一个新的gi号(这时序列的接收号可能不变)。gi号后面是序列的标识符,标识符由序列来源标识、序列标识(如接收号、名称等)等几部分组成,他们之间用“|”隔开,如果某项缺失,可以留空但是“|”不能省略。
第二部分:换行后既是第二部分,表示序列信息,序列中允许空格,换行,空行。直到下一个大于号表示该序列结束。