一、拾遗
1、在Python中数据又称为对象,每创建一个对象都会创建三个属性:
(1)身份:id
is 用来比较id,id一样,type和value肯定一样
(2)类型:type
用 type() 查看某一个对象的类型,例:
type(1) is('a")可以判断类型是不是一样
(3)值:value
== 用来比较值,id不一样,value一定不一样
2、列表的常用操作
(1)定义:
l = [l,'a',[1,2,3]] 相当于 l = list(['a',[1,2,3]])
列表里可以是任意数据类型
列表是可变数据类型
(2)索引
通过索引取值: [ ]
中括号中加上索引值,就可以取出列表中的元素名了。
(3)循环
<1>根据索引方式循环用while和for
I、while
index = 0
while index < len(l)
print(l[index])
index += 1
II、for
for i in range(len(l)):
print(l[i])
<2>不通过索引方式用for
for i in l:
print(i)
(4)切片
读操作
例:
l[1:5] # 表示切到索引位置1-4的位置,顾首不顾尾
l[1:5:2] # 2是步长
(5)追加
l.append(元素)
(6)删除
删除索引值为0的元素
del l[0]
l.pop[0]
l.remove[0]
(7)长度
len(l)
(8)包含
元素 in 列表名
3、元组
(1)定义:
t= (l,'a',[1,2,3]])相当于 t = tuple(('a',[1,2,3]))
元组是不可变数据类型
注意:当元组里只有一个元素时,最好是加上“,”,例:t = ("x",)
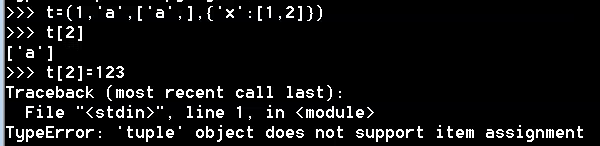
元组本身的元素不可改变,但是元组中的子元素可以改变
例:
对元组本身的元素进行更改会提示错误
对元组中的元素可以进行更改
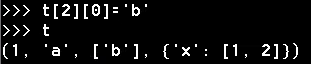
(2)索引
通过索引取值: [ ]
(3)循环
<1>根据索引方式循环用while和for
I、while
index = 0
while index < len(t)
print(t[index])
index += 1
II、for
for i in range(len(t)):
print(t[i])
<2>不通过索引方式用for
for i in t:
print(i)
(4)长度
len(t)
(5)切片
读操作
通过索引切片: [:]
例:
t[1:9:2] # 表示取索引位置1-8之间的元素,且步长为2。顾首不顾尾
(6)包含
通过in
4、字典
(1)定义
d = {“key”:"value"} 或 d = dict({"key":"value"})
(2) 取值
d[“key”] = value
(3)循环
不通过索引的方式:
例:
d = {'x':1,"y":2}
for k in d:
print(k) # 取出字典中的key
print(d[k]) # 取出字典中的value
(4)修改
用[ ]来对字典进行修改操作
d['name'] = 'xiaoxiaobai' # 将原来的值"xiaobai"改为“xiaoxiaobai”
(5)嵌套
(6)字典的其它常用操作
参考:http://www.cnblogs.com/xiaoxiaobai/p/7615608.html
<1>item()
返回可遍历的(键、值)元组数组
例:
d = {'x':1,'y':1}
for item in d.items(): # [('x',1),('y',1)]
print(item) # 遍历出每个元组
<2>变量赋值
例1:
k,v = (1,2)
print(k,v)
所以在循环字典时可以用两个变量分别表示字典的key和value来循环:
例2:
d = {'x':1,'y':1}
for k,v in d.items(): # k表示字典的key,v表示字典的value
print(k,v) # 取出字典里的键和值:x 1
y 1
<3>keys()
取出字典中所有的key
例:
d = {'x':1,'y':1}
res = list(d.keys()) # 将取出的字典里的所有的key转换成列表
print(res) # 都存放到列表里
<4>popitem()
随机返回并删除字典中的一对键和值。
例:
d = {'x':1,'y':12222}
print(d.popitem()) # 随机返回并删除字典中的一对键和值,记住popitem()括号里不能加参数
print(d) # 得到删除后的字典
(7)删除
d.pop("x")
d.popitem() # 随机删除
(8)键、值、键值对
d.keys()
d.values()
d.items()
(9)长度
d = {'x':1,'u':2}
print(len(d))
(10)成员运算
d = {'x':1,'u':2}
print("x" in d) # 判断key是否在字典里,得到布尔值
print(1 in d.values()) # 判断value是否在字典里,得到布尔值
(11)补充:
字典中如果有相同的key,则最后一个生效:
d ={'x':1,'x':2}
print(d) # 输出结果为{'x':2}
二、布尔值
1、True和False
产生布尔值:
print(type(True)) # 可以查看布尔值是由bool的工厂函数产生的。
之前碰到的布尔值都是通过比较运算和成员运算得到布尔值
例:
count = 10
print(count > 10) # 得到布尔类型:False ,相当于在调用bool的工厂函数:print(bool(count > 10))
2、所有的数据类型都自带布尔值。只有0、None、空的布尔值为False,其它都是Ture
例1:判断列表为空
l = []
if len(l) == 0: # 判断列表的长度等于0,这个地方实际上是拿到了一个布尔值。
print("列表为空")
例2:自带布尔值的概念
l = []
if not l:
# 直接写到条件判断的后面,if判断则会调用bool()函数,把列表l传进去,得到bool(l),
#这时的列表l相当于False,等于if not False,也就是 if True:
print("列表为空")
综上所述:什么叫自带布尔值?
if 判断会自动去调bool()工厂函数,然后把数据类型传进去
例3:写一个用户输入命令为空的情况下让其继续输入命令:
# 例3:写一个用户输入命令为空的情况下让其继续输入命令:
while 1:
cmd = input("Please input your cmd:")
if not cmd: # cmd本身带布尔值,如果输入为空,相当于cmd这里放了一个False
# 此时cmd是空,加上not,表示不为空的情况下条件才成立。
# not cmd合到一块代表命令输入为空的情况下
continue
print("====>cmd",cmd) # 输入回车后继续输入。
三、集合
1、定义:
例:
s = {"a","b",1,2,"b"} # 实际上是在调用 s = set({"a","b",1,2,"b"})
2、集合的特点:
集合内的元素必须是唯一的
集合内的元素必须是可hash的(不可变的类型)
集合是无序的
集合没有索引也没有key,不能单个取值
集合是用来作关系运算的,做一个集合与另一个集合找共同部分等操作,单个元素不考虑用集合
3、作用
作用1:关系运算
作用2:去重
4、循环
集合只能用不依赖索引的方式遍历
例:
s = {"a","b",1,2,"b"}
for i in s:
print(i) # 遍历每个集合的元素
5、关系运算
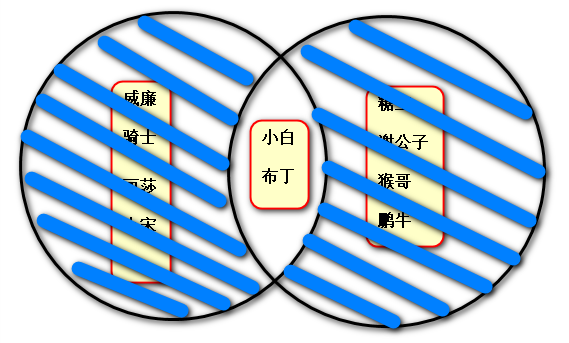
例:假设一个培训机构分别开设了linux培训班和python培训班,用集合求出以下关系运算:
linux_s = {"小白","威廉",“骑士”,“丽莎”,“布丁”,"小宋"}
python_s = {"糖宝",“谢公子”,“布丁”,"猴哥",“鹏牛”,“小白”}
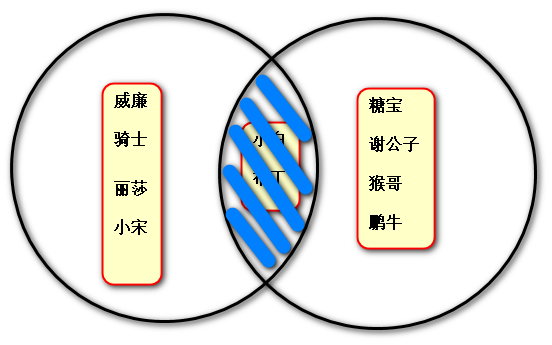
(1)取共二者的共同部分:
找出既报了linux班又报了python班的学生:
print(python_s & linux_s) # 交集
或 print(python_s.intersection(linux_s)) # 交集
输出结果:
{"布丁","小白"}
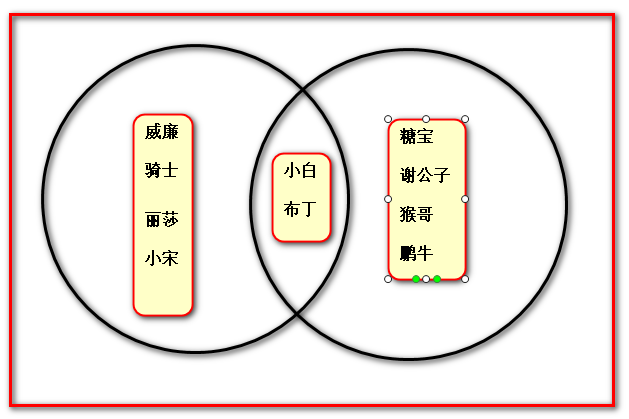
(2)取二者的所有学生:
取出所报了这个培训班所有的学生:
print(python_s | linux_s) # 并集
或 print(python_s.union(linux_s)) # 并集
输出结果:
{"糖宝",“谢公子”,“布丁”,"猴哥",“鹏牛”,“小白”,"威廉",“骑士”,“丽莎”,"小宋"}
(3)取只报了python课程的学生:
print(python_s - linux_s) # 差集
或 print(python_s.difference( linux_s)) # 差集
输出结果:
{"糖宝",“谢公子”,"猴哥",“鹏牛”}
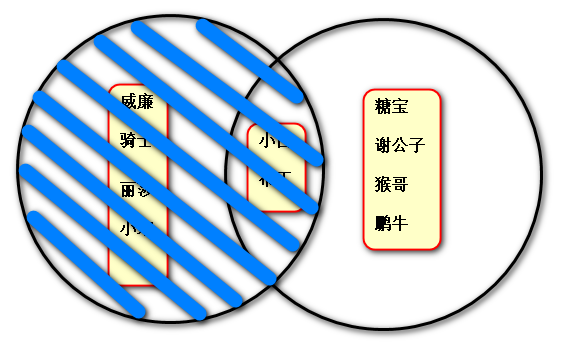
(4)取没有同时报python课程和linux课程的学生:
print(python_s ^ linux_s) # 对称差集
或 print(python_s .symmetric_difference(linux_s)) # 对称差集
输出结果:
{"糖宝",“谢公子”,"猴哥",“鹏牛”,“威廉”,“骑士”,"丽莎",“”}
(5)其它方法操作
参考:http://www.cnblogs.com/xiaoxiaobai/p/7615608.html
四、补充:
1、字符串格式化:%s
例:
res = "name:%s" %"xiaobai" # 如果是%d,就只能传数字
2、while和else的连用
要执行else下的语句,必须满足:1、循环结束
2、没有被break打断
例1:
count = 1
while count < 10:
print(count)
break
count += 1
else: # 在循环正常结束后执行,
# 条件:1、循环结束 2、没有被break打断
# 只有符合以上两点条件,才会执行else下的语句
# 此例因为循环体有break,所以不会执行else下的语句
print("hahahaha")
例2:
for i in range(10):
print(i)
if i == 5:
break
else: # 只有符合以上两点条件,才会执行else下的语句
# 此例因为循环体有break,所以不会执行else下的语句
print("hahahaha")
3、小练习:
要求:将以下列表在不打乱排序的情况下去重。
l = ["xiaobai","lisa","knight","xiaobai","william"]
l = ["xiaobai","lisa","knight","xiaobai","william"]
l1 = []
for i in l: # 遍历l列表中的每个元素
if i not in l1: # 最关键的一步:如果这个元素没有在列表l1里
l1.append(i) # 则将遍历的元素都添加到l1列表中
print(l1)
输出结果:


['xiaobai', 'lisa', 'knight', 'william']