一、Runtime架构图
(1)从Spark Runtime的角度讲,包括五大核心对象:Master、Worker、Executor、Driver、CoarseGrainedExecutorBackend。
(2)Spark在做分布式集群系统设计的时候:最大化功能独立、模块化封装具体独立的对象、强内聚松耦合。Spark运行架构图如下图所示。
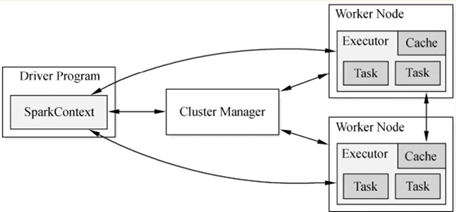
(3)当Driver中的SparkContext初始化时会提交程序给Master,Master如果接受该程序在Spark中运行,就会为当前的程序分配AppID,同时会分配具体的计算资源。
需要特别注意的是,Master是根据当前提交程序的配置信息来给集群中的Worker发指令分配具体的计算资源,但是,Master发出指令后并不关心具体的资源是否已经分配,换言之,Master是发指令后就记录了分配的资源,以后客户端再次提交其他的程序,就不能使用该资源了。
其弊端是可能会导致其他要提交的程序无法分配到本来应该可以分配到的计算资源;最终的优势是Spark分布式系统功能在耦合的基础上最快的运行系统(否则如果Master要等到资源最终分配成功后才通知Driver,就会造成Driver阻塞,不能够最大化并行计算资源的使用率)。
需要补充说明的是:Spark在默认情况下由于集群中一般都只有一个Application在运行,所有Master分配资源策略的弊端就没有那么明显了
二、生命周期
我们从Spark Runtime全局的角度看Spark具体是怎么工作的,从一个具体的job的视角通过Driver、Master、Worker、Executor等角色来具体看看Spark的Runtime生命周期
这里我们编写WordCountJobRuntime.scala代码,观察日志,源数据如下
代码如下:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
object WordCountJobRuntime {
def main(args: Array[String]){
Logger.getLogger("org").setLevel(Level.ALL)
// 第1步:创建Spark的配置对象SparkConf
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName("Wow,WordCountJobRuntime!")
//设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setMaster("local") //此时,程序在本地运行,不需要安装Spark集群
//第2步:创建SparkContext对象
val sc = new SparkContext(conf)
// 第 3 步:根据具体的数据来源(如 HDFS、HBase、Local FS、DB、S3等)通过 SparkContext创建RDD
val lines = sc.textFile("WordCountJobRuntime.txt")
// 第4步:对初始的RDD进行Transformation级别的处理,如通过map、filter等
val words = lines.flatMap { line => line.split(" ")}
val pairs = words.map { word => (word, 1) }
val wordCountsOdered = pairs.reduceByKey(_+_)
wordCountsOdered.foreach(println)
while(true){
}
sc.stop()
}
}
得到结果

在eclipse的控制台中观察WordCountJobRuntime.scala运行日志,日志中显示FileInputFormat: Total input paths to process : 1说明有一个文件要处理。

在Spark中,所有的Action都会触发至少一个Job,在WordCountJobRuntime.scala代码中,是通过println来触发Job的。紧接着交给DAGScheduler,日志中显示DAGScheduler: Registering RDD,因为这里有两个Stage,从具体计算的角度,前面Stage计算的时候保留输出。然后是DAGScheduler获得了job的ID(job 0)。

SparkContext在实例化的时候会构造StandaloneSchedulerBackend、DAGScheduler、TaskSchedulerImpl、MapOutputTrackerMaster等对象。
其中,StandaloneSchedulerBackend负责集群计算资源的管理和调度,这是从作业的角度来考虑的,注册给Master的时候,Master给我们分配资源,资源从Executor本身转过来向StandaloneSchedulerBackend注册,这是从作业调度的角度来考虑的,不是从整个集群来考虑,整个集群是Master来管理计算资源的。
DAGScheduler负责高层调度(如Job中Stage的划分、数据本地性等内容)。
TaskSchedulerImple负责具体Stage内部的底层调度(如具体每个Task的调度、Task的容错等)。
MapOutputTrackerMaster负责Shuffle中数据输出和读取的管理。Shuffle的时候将数据写到本地,下一个Stage要使用上一个Stage的数据,因此写数据的时候要告诉Driver中的MapOutputTrackerMaster具体写到哪里,下一个Stage读取数据的时候也要访问Driver的MapOutputTrackerMaster获取数据的具体位置。
MapOutputTrackerMaster的源码如下。
private[spark] class MapOutputTrackerMaster(conf: SparkConf,
broadcastManager: BroadcastManager, isLocal: Boolean)
extends MapOutputTracker(conf) {
DAGScheduler是面向Stage调度的高层调度实现。它为每一个Job计算DAG,跟踪RDDS及Stage输出结果进行物化,并找到一个最小的计划去运行Job,然后提交stages中的TaskSets到底层调度器TaskScheduler提交集群运行,TaskSet包含完全独立的任务,基于集群上已存在的数据运行(如从上一个Stage输出的文件),如果这个数据不可用,获取数据可能会失败。
Spark Stages根据RDD图中Shuffle的边界来创建,如果RDD的操作是窄依赖,如map()和filter(),在每个Stages中将一系列tasks组合成流水线执行。但是,如果是宽依赖,Shuffle依赖需要多个Stages(上一个Stage进行map输出写入文件,下一个Stage读取数据文件),每个Stage依赖于其他的Stage,其中进行多个算子操作。算子操作在各种类型的RDDS(如MappedRDD、FilteredRDD)的RDD.compute()中实际执行。
在DAG阶段,DAGScheduler根据当前缓存状态决定每个任务运行的位置,并将任务传递给底层的任务调度器TaskScheduler。此外,它处理Shuffle输出文件丢失的故障,在这种情况下,以前的Stage可能需要重新提交。Stage中不引起Shuffle文件丢失的故障由任务调度器TaskScheduler处理,在取消整个Stage前,将重试几次任务。
当浏览这个代码时,有几个关键概念:
Jobs作业(表现为[ActiveJob])作为顶级工作项提交给调度程序。当用户调用一个action,如count()算子,Job将通过submitJob进行提交。每个作业可能需要执行多个stages来构建中间数据。
Stages ([Stage])是一组任务的集合,在相同的RDD分区上,每个任务计算相同的功能,计算Jobs的中间结果。Stage根据Shuffle划分边界,我们必须等待前一阶段Stage完成输出。有两种类型的Stage:[ResultStage]是执行action的最后一个Stage,[ShuffleMapStage]是Shuffle Stages通过map写入输出文件中的。如果Jobs重用相同的RDDs,Stages可以跨越多个Jobs共享。
Tasks任务是单独的工作单位,每个任务发送到一个分布式节点。
缓存跟踪:DAGScheduler记录哪些RDDS被缓存,避免重复计算,以及记录Shuffle map Stages已经生成的输出文件,避免在map端重新计算。
数据本地化:DAGScheduler基于RDDS的数据本地性、缓存位置,或Shuffle数据在Stage中运行每一个任务的Task。
清理:当依赖于它们的运行作业完成时,所有数据结构将被清除,防止在长期运行的应用程序中内存泄漏。
为了从故障中恢复,同一个Stage可能需要运行多次,这被称为重试“attempts”。如在上一个Stage中的输出文件丢失,TaskScheduler中将报告任务失败,DAGScheduler通过检测CompletionEvent与FetchFailed或ExecutorLost事件重新提交丢失的Stage。DAGScheduler将等待看是否有其他节点或任务失败,然后在丢失计算任务的阶段Stage中重新提交TaskSets。在这个过程中,可能须创建之前被清理的Stage。旧Stage的任务仍然可以运行,但必须在正确的Stage中接收事件并进行操作。
DAGScheduler.scala的源码如下。
private[spark]
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
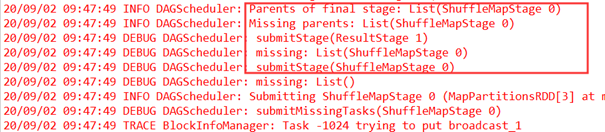
回到运行日志,SparkContext在实例化的时候会构造StandaloneSchedulerBackend、DAGScheduler、TaskSchedulerImpl、MapOutputTrackerMaster四大核心对象,DAGScheduler获得Job ID,日志中显示DAGScheduler: Final stage: ResultStage 1,Final stage是ResultStage;Parents of final stage是ShuffleMapStage,DAGScheduler是面向Stage的。日志中显示两个Stage:Stage 1是Final stage,Stage 0是ShuffleMapStage。
接下来序号改变,运行时最左侧从0开始,日志中显示DAGScheduler: missing: List(ShuffleMapStage 0),父Stage是ShuffleMapStage,DAGScheduler调度时必须先计算父Stage,因此首先提交的是ShuffleMapStage 0,这里RDD是MapPartitionsRDD,只有Stage中的最后一个算子是真正有效的,Stage 0中的最后一个操作是map,因此生成了MapPartitionsRDD。Stage 0无父Stage,因此提交,提交时进行广播等内容,然后提交作业。
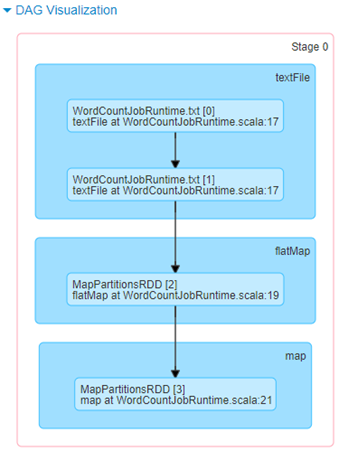
我们从http://172.20.10.3:4040/jobs/的角度看一下,如下图所示,Web UI中显示生成两个Stage:Stage 0、Stage 1。

日志中显示DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0,DAGScheduler提交作业,显示提交一个须计算的任务,ShuffleMapStage在本地运行是一个并行度,交给TaskSchedulerImpl运行。
这里是一个并行度,提交底层的调度器TaskScheduler,TaskScheduler收到任务后,就发布任务到集群中运行,由TaskSetManager进行管理:日志中显示TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 6012 bytes),显示具体运行的位置,及worker运行了哪些任务。这里在本地只运行了一个任务。
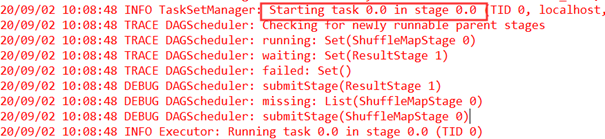
然后是完成作业,日志中显示TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 327 ms on localhost (executor driver),在本地机器上完成作业。当Stage的一个任务完成后,ShuffleMapStage就已完成。Task任务运行完后向DAGScheduler汇报,DAGScheduler查看曾经提交了几个Task,计算Task的数量如果等于Task的总数量,那Stage也就完成了。这个Stage完成以后,下一个Stage开始运行。

ShuffleMapStage完成后,将运行下一个Stage。日志中显示DAGScheduler: looking for newly runnable stages,这里一共有两个Stage,ShuffleMapStage运行完成,那只有一个ResultStage将运行。DAGScheduler又提交最后一个Stage的一个任务,默认并行度是继承的。同样,发布任务给Executor进行计算。

Task任务运行完后向DAGScheduler汇报,DAGScheduler计算曾经提交了几个Task,如果Task的数量等于Task的总数量,ResultStage也运行完成。然后进行相关的清理工作,两个Stage(ShuffleMapStage、ResultStage)完成,Job也就完成。

下面看一下WebUI,ShuffleMapStage中的任务交给Executor,图3-9中显示了任务的相关信息,如Shuffle的输出等,第一个Stage肯定生成Shuffle的输出,可以看一下最右侧的Shuffle Write Size/Records。下图中的Input Size/Records是从Hdfs中读入的文件数据。
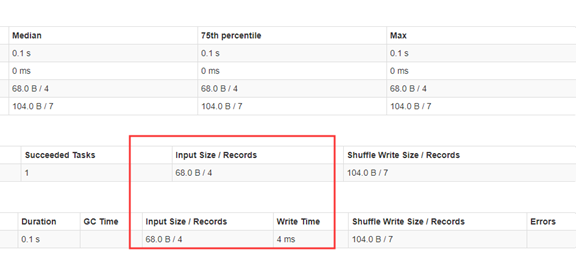
接下来看一下第二个Stage。第二个Stage同样显示Executor的信息,下图最右侧显示Shuffle Read Size/Records。如果在分布式集群运行,须远程读取数据,例如,原来是4个Executor计算,在第二个Stage中是两个Executor计算,因此一部分数据是本地的,一部分是远程的,或从远程节点拉取数据。ResultStage最后要产生输出,输出到文件保存。

三、总结
我们通过对Spark Runtime(Driver、Master、Worker、Executor)内幕解密,从Spark Runtime全局的角度看Spark具体是怎么工作的,从一个作业的视角通过Driver、Master、Worker、Executor等角色来透视Spark的Runtime生命周期。
这里所有截图都是从本机截图的,都是能够进行实际验证的,包括所有源代码是基于Spark-2.0.1的。