xpath是一门在xml文档中查找信息的语言。xpath可以用来在xml文档中对元素和属性进行遍历。
在xpath中,有7中类型的节点,元素,属性,文本,命名空间,处理指令,注释及根节点。
节点
首先看下面例子:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
上面的节点例子:
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)
父:在上面的例子里,book是title,author,year,price的父。
子:反过来,title,author,year,price是book的子。
同胞:title,author,year,price是同胞。
先辈:title的先辈是book,bookstore。
后代:bookstore的后代是book,tite,author,year,price。
再看一个例子:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore
如何选取节点呢?
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。

对应上面的例子,得到结果:

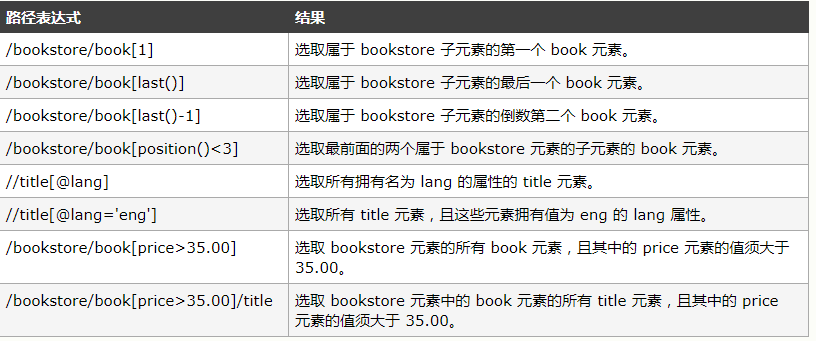
谓语:谓语用来查找某个特定节点或者包含某个指定值的节点。
比如:
选取未知节点:

比如:

选取若干路径:通过在路径表达式中使用“|”运算符,您可以选取若干个路径。

常用xpath属性:
# 找到class属性为song的div标签
//div[@class="song"]
层级定位:
# 找到class属性为tang的div直系字标签ul下的第二个字标签li下的直系字标签a
//div[@class='tang']/ul/li[2]/a
逻辑运算:
找到class属性为空且href属性为tang的a标签
//a[@class='' and @href='tang']
模糊定位
# 查找class属性值里包含'ng'字符串的div标签
//div[contains(@class, 'ng')]
# 配配class属性以ta为开头的div标签
//div[start_with(@class, 'ta')]
获取文本
//div[@class="song"]/p[1]/text()
获取属性
# 获取class属性为tang的div下的第二个li下面a标签的href属性
//div[@class="tang"]//li[2]/a/@href
在python中应用
将html文档或者xml文档转换成一个etree对象,然后调用对象中的方法查找指定节点。
1 本地文件:
tree = etree.parse(文档)
tree.xpath(xpath表达式)
2 网络数据:
tree = etree.HTML(网页字符串)
tree.xpath(xpath表达式)
例子1:随机爬取糗事百科糗图首页的一张图片
import requests
from lxml import etree
import random
def main():
# 网页url
url = 'https://www.qiushibaike.com/pic/'
ua_headers = {"User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
# 网页代码
response = requests.get(url=url, headers=ua_headers).text
# 转换为etree对象
tree = etree.HTML(response)
# 匹配到所有class属性为thumb的div标签下的img标签的src属性值,返回一个列表
img_lst = tree.xpath('//div[@class="thumb"]//img/@src')
# 随机挑选一个图片并且下载下来
res = requests.get(url='https:'+random.choice(img_lst), headers=ua_headers).content
# 将图片保存到本地
with open('image.jpg', 'wb') as f:
f.write(res)
if __name__ == '__main__':
main()
例子2:爬取煎蛋网首页的图片
import requests
from lxml import etree
def main():
url = 'http://jandan.net/ooxx'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) "
"Version/5.1 Safari/534.50"}
response = requests.get(url=url, headers=headers).text
tree = etree.HTML(response)
img_lst = tree.xpath('//div[@class="text"]//img/@src')
for one_image in img_lst:
res = requests.get(url='http:'+one_image, headers=headers).content
with open('image/' + one_image.split('/')[-1] + '.gif', 'wb') as f:
f.write(res)
if __name__ == '__main__':
main()