1 Hive入门教程
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
在Hive中,Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/RJob里使用这些数据。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下ApacheHive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在Amazon Elastic、MapReduce。
1.1 Hive原理图
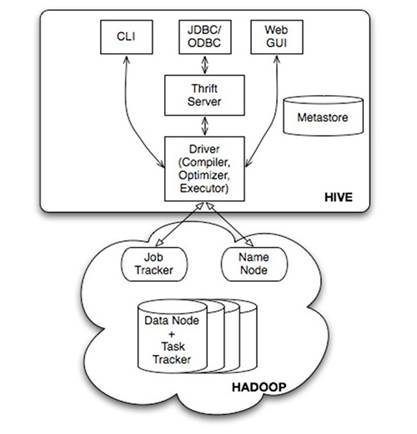
1-1 Hive系统架构图
1.2 Hive系统架构
Hive系统架构图:
1、用户接口:
CLI,即Shell命令行。
JDBC/ODBC是 Hive的Java,与使用传统数据库JDBC的方式类似。
WebGUI是通过浏览器访问 Hive。
2、Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在C++,Java, Go,Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript,Node.js, Smalltalk, and OCaml这些编程语言间无缝结合的、高效的服务。
3、解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
4、Hive的数据存储在 HDFS中,大部分的查询由 MapReduce完成(包含 * 的查询,比如 select *from table不会生成MapRedcue任务)。
5、Hive将元数据存储在数据库中(metastore),目前只支持mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
1.3 前置条件
Hive是建立Hadoop环境安装之上的,所以需要Hadoop的集群环境搭建,Hive即需要依赖于HDFS又需要依赖YARN。安装好Hadoop后需要进行启动HDFS和YARN。
环境安装参考资料:
1、安装《VMware安装Linux教程》地址:http://blog.csdn.net/yuan_xw/article/details/49827477
2、安装《Linux网络配置与远程连接》地址:http://blog.csdn.net/yuan_xw/article/details/49945007
3、安装《Hadoop教程(五)Hadoop分布式集群部署安装》
地址:http://blog.csdn.net/yuan_xw/article/details/51175171
4、安装《MySQL环境安装(一)》地址:http://blog.csdn.net/yuan_xw/article/details/77983704
5、Hive规划图
|
主机名 |
IP |
安装软件 |
运行进程 |
|
Hadoop1 |
192.168.197.128 |
Jdk、Hadoop |
NameNode、DFSZKFailoverController |
|
Hadoop2 |
192.168.197.129 |
Jdk、Hadoop |
NameNode、DFSZKFailoverController |
|
Hadoop3 |
192.168.197.130 |
Jdk、Hadoop |
ResourceManager、Hive、MySQL |
|
Hadoop4 |
192.168.197.131 |
Jdk、Hadoop、Zookeep |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
|
Hadoop5 |
192.168.197.132 |
Jdk、Hadoop、Zookeep |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
|
Hadoop6 |
192.168.197.133 |
Jdk、Hadoop、Zookeep |
DataNode、NodeManager、JournalNode、QuorumPeerMain |