1. 程序员的烦恼:Debug
调试(debug),大概是所有程序员的噩梦。而不幸的是,对一个Shader进行调试更是噩梦中的噩梦。这也是造成Shader难写的原因之一——如果发现得到的效果不对,我们就可能花非常多的时间来找到问题所在。造成这种现状的原因就是在Shader中可以选择的调试方法非常有限,甚至连简单的输出都不行。
2. 最新利器:帧调试器
Unity5除了带来全新的UI系统外,还为我们带来了一个新的针对渲染的调试器——帧调试器(Frame Debugger)。与其它调试工具的复杂性相比,Unity原生的帧调试器非常简单快捷。我们可以用它来看到游戏图像的某一帧是如何一步步渲染出来的。
要使用帧调试器,我们首先需要在Window->Frame Debugger中打开帧调试器窗口,如下图所示:
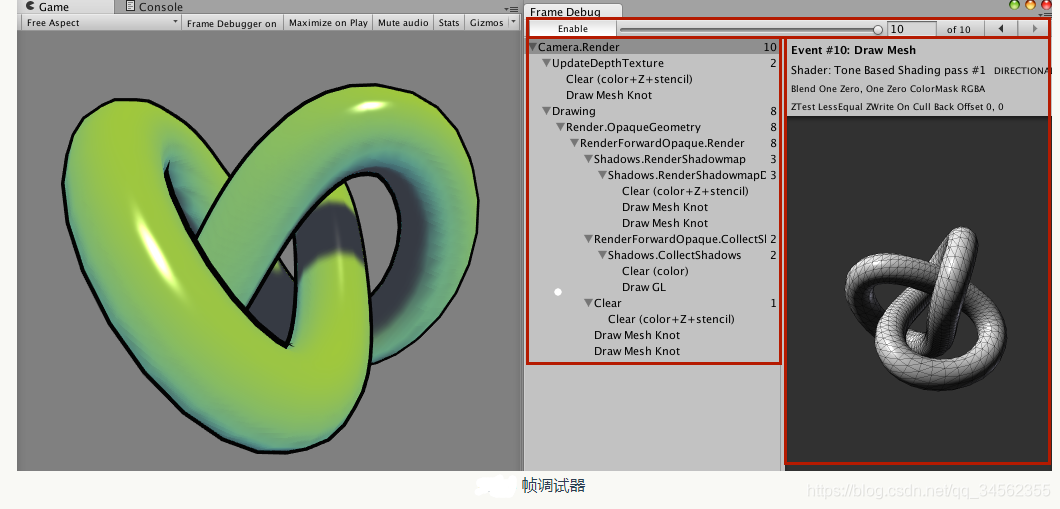
帧调试器可以用于查看渲染该帧时进行的各种渲染事件(event),这些事件包含了Draw Call序列,也包括了类似清空缓存等操作。帧调试器窗口大致可分为3个部分:最上面的区域可以开启/关闭(单击Enable按钮)帧调试功能,当开启了帧调试时,通过移动窗口最上方的滑动条(或单击前进和后退按钮),我们就可以重放这些渲染事件;左侧区域显示了所有事件的树状图,在这个树状图中,每个叶子节点就是一个事件,而每个父节点的右侧显示了该节点下的事件数目。我们可以从事件的名字了解这个事件的操作,例如以Draw开头的事件通常就是一个Draw Call;当单击了某个事件时,在右侧的窗口就会显示该事件的细节,例如几何图形的细节以及使用了哪个Shader等。同时在Game视图中我们也可以看到它的效果。如果该事件是一个Draw Call并且对应了场景中的一个GameObject,那么这个GameObject也会在Hierarchy视图中被高亮显示出来,下图显示了单击渲染某个对象的深度图事件的结果。
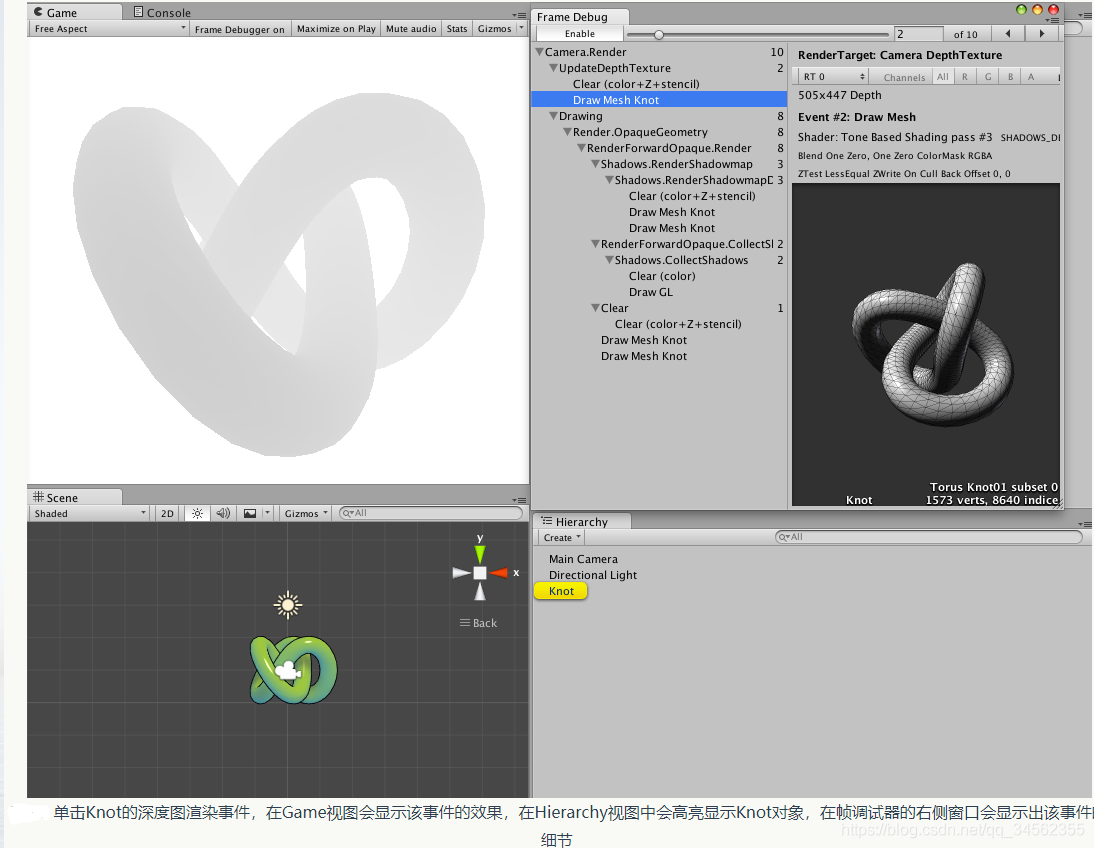
如果被选中的Draw Call是一个对渲染纹理(RenderTexture)的渲染操作,那么这个渲染纹理就会显示在Game视图中。而且,此时右侧面板上方的工具栏中也会出现更多的选项,例如在Game视图中单独显示R、G、B和A通道。
Unity5提供的帧调试器实际上并没有实现一个真正的帧拾取(frame capture)的功能,而是仅仅使用了停止渲染的方法来查看渲染事件的结果。例如我们想要查看第4个Draw Call的结果,那么帧调试器就会在第4个Draw Call调用完毕后停止渲染。这种方法虽然简单,但得到的信息也有限。
3. 小心渲染平台的差异
我们以前提到过OpenGL和DirectX的屏幕空间坐标的差异,如下图所示:
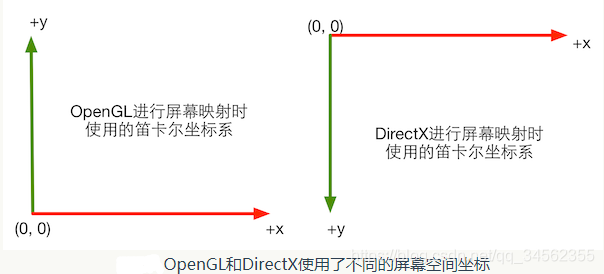
需要注意的是,我们不仅可以把渲染结果输出到屏幕上,还可以输出到不同的渲染目标(Render Target)中。这时,我们需要使用渲染纹理(Render Texture)来保存这些渲染结果。我们将在后面学习如何实现这样的目的。
大多数情况下,这样的差异并不会对我们造成任何影响。但当我们要使用渲染到纹理技术,把屏幕图像渲染到一张渲染纹理时,如果不采取任何措施的话,就会出现纹理翻转的情况。幸运的是,Unity在背后为我们处理了这种翻转问题——当在DirectX平台使用渲染到纹理技术时,Unity会为我们翻转屏幕图像纹理,以便在不同平台上达到一致性。
在一种特殊情况下Unity不会为我们进行这个翻转操作,这种情况就是我们开启了抗锯齿(在Edit->Project Setting->Quality->Anti Aliasing中开启)并在此时使用了渲染到纹理技术。在这种情况下,Unity首先渲染得到屏幕图像,再由硬件进行抗锯齿处理后,得到一张渲染纹理来供我们进行后续处理。此时,在DirectX平台下,我们得到的输入屏幕图像并不会被Unity翻转,也就是说,此时对屏幕图像的采样坐标是需要符合DirectX平台规定的。如果我们的屏幕特效只需要处理一张渲染图像,我们仍然不需要在意纹理的翻转问题,这是因为我们在调用Graphics.Blit函数时,Unity已经为我们对屏幕图像的采样坐标进行了处理,我们只需要按照正常的采样过程处理屏幕图像即可。但如果我们需要同时处理多张渲染图像(前提是开启了抗锯齿),例如需要同时处理屏幕图像和法线纹理,这些图像在竖直方向的朝向可能是不同的(只有在DirectX这样的平台上才有这样的问题)。这种时候,我们就需要自己在顶点着色器中翻转某些渲染纹理(例如深度纹理或其它由脚本传递过来的纹理)的纵坐标,使之都符合DirectX平台的规则。例如:
#if UNITY_UV_STARTS_AT_TOP
if(_MainTex_TexelSize.y<0)
uv.y = 1- uv.y;
#endif
其中,UNITY_UV_STARTS_AT_TOP用于判断当前平台是否是DirectX类型的平台,而在这样的平台下开启了抗锯齿后,主纹理的纹理大小在竖直方向上会变成负值,以方便我们对主纹理进行采样。因此,我们可以通过判断_MainTex_TexelSize.y是否小于0来检验是否开启了抗锯齿。如果是,我们就需要对主纹理外的其他纹理的采样进行竖直方向上的翻转。
4. Shader的整洁之道
4.1 float、half还是fixed
我们使用Cg/HLSL来编写UnityShader中的代码。而在Cg/HLSL中,有三种精度的数值类型:float,half和fixed。这些精度将决定计算结果的数值范围。下表给出了这3种精度在通常情况下的数值范围。

上面的精度范围并不是绝对正确的,尤其是在不同平台和GPU上,它们的实际精度可能和上面给出的范围不一致。通常来讲:
(1)大多数现代的桌面GPU会把所有计算都按最高的浮点精度进行计算,也就是说,float、half、fixed在这些平台上实际是等价的。这意味着,我们在PC上很难看出因为half和fixed精度而带来的不同。
(2)但在移动平台GPU上,它们的确会有不同的精度范围,而且不同精度的浮点值的运算速度也会有所差异。因此,我们应该确保在真正的移动平台上验证我们的Shader。
(3)fixed精度实际上只在一些较旧的移动平台上有用,在现在大多数现代的GPU上,它们内部把fixed和half当成同精度来对待。
尽管由上面的不同,但一个基本的建议是,尽可能使用精度较低的类型,是因为这可以优化Shader的性能,这一点在移动平台上尤为重要。从它们大体的值域范围来看,我们可以使用fixed类型来存储颜色和单位矢量,如果要存储更大范围的数据可以选择half类型,最差的情况下再选择float。如果我们的目标平台是移动平台,一定要确保在真实的手机上测试我们的Shader,这一点非常重要。
4.2 避免不必要的计算
如果我们毫不节制的在Shader(尤其是片元着色器)中进行了大量计算,那么我们可能很快收到Unity的错误提示:
temporary register limit of 8 exceeded
或
Arithmetic instruction limit of 64 exceeded;65 arithmetic instructions needed to compile program
出现这些错误信息大多是因为我们在Shader中进行了过多的运算,使得需要的临时寄存器数目或指令数目超过了当前可支持的数目。读者需要知道,不同的Shader Target、不同的着色器阶段,我们可以使用的临时寄存器和指令数目都是不同的。
通常,我们可以通过制定更高级的Shader Target来消除这些错误。下表给出了Unity目前支持的一些
Shader Target。

需要注意的是,由于Unity版本的不同,Unity支持的Shader Target种类也不同,读者可以在官方手册上找到更为详细的介绍。
读者:什么是Shader Model呢?
我们:Shader Model是由微软提出的一套规范,通俗的理解就是它们决定了Shader中各个特性(feature)的能力(capability)。这些特性和能力体现在Shader能使用的运算指令数目、寄存器数目等各个方面。Shader Model等级越高,Shader的能力越大。
虽然更高等级的Shader Target可以让我们使用更多的临时寄存器和运算指令,但一个更好的方法是尽可能减少Shader中的运算,或者通过预计算的方式来提供更多的数据。
4.3 慎用分支和循环语句
在最开始,GPU是不支持在顶点着色器和片元着色器中使用流程控制语句的。随着GPU的发展,我们现在已经可以使用if-else、for和while这种流程控制指令了。大体来说,GPU使用了不同于CPU的技术来实现分支语句,在最坏的情况下,我们花在一个分支语句的时间相当于运行了所有分支语句的时间。因此,我们不鼓励在SubShader中使用流程控制语句,因为它们会降低GPU的并行处理操作。
如果我们在Shader中使用了大量的流程控制语句,那么这个Shader的性能会成倍下降。一个解决方法是,我们应该尽量把计算向流水线上方移动,例如把放在片元着色器中的计算放到顶点着色器中去,或者直接在CPU中进行预计算,再把结果传递给Shader。当然,有时我们不可避免的要使用分支语句来进行计算,那么一些建议是:
(1)分支判断语句中使用的条件变量最好是常数,即在Shader运行过程中不会发生变化;
(2)每个分支中包含的操作指令数尽可能少;
(3)分支的嵌套层数尽可能少。